Training and Tuning Generative Neural Radiance Fields for Attribute-Conditional 3D-Aware Face Generation

0
🏋️
Sign in to get full access
Overview
- Generative Neural Radiance Fields (GNeRF)-based 3D-aware GANs have shown impressive ability to create high-quality, realistic images while maintaining 3D consistency, particularly for face generation.
- However, existing models prioritize view consistency over disentanglement, limiting semantic or attribute control during the generation process.
- Many methods have tried incorporating semantic masks or 3D Morphable Model (3DMM) priors to give models more semantic control, but these often require training from scratch, which is computationally expensive.
Plain English Explanation
The paper proposes a novel approach: a conditional GNeRF model that takes specific attribute labels as input, enhancing the controllability and disentanglement capabilities of 3D-aware generative models. This builds upon a pre-trained 3D-aware face model, using a "Training as Init and Optimizing for Tuning" (TRIOT) method to train a conditional normalized flow module for facial attribute editing. The latent vector is then optimized to further improve the precision of attribute editing.
Technical Explanation
The paper presents a conditional GNeRF model that integrates specific attribute labels as input. This amplifies the controllability and disentanglement capabilities of the 3D-aware generative model.
The approach builds upon a pre-trained 3D-aware face model. The authors introduce a "Training as Init and Optimizing for Tuning" (TRIOT) method, which trains a conditional normalized flow module to enable facial attribute editing, and then optimizes the latent vector to further improve the precision of attribute editing.
Critical Analysis
The paper addresses an important challenge in 3D-aware generative models - balancing view consistency and semantic control. By incorporating attribute labels as input, the proposed approach enhances the disentanglement and controllability of the generation process.
However, the paper does not discuss the limitations of the TRIOT method or the potential issues that may arise from optimizing the latent vector. It would be helpful to understand the computational overhead of this approach compared to training from scratch, as well as any potential biases or artifacts introduced by the optimization process.
Conclusion
This research presents a novel conditional GNeRF model that integrates attribute labels to amplify the controllability and disentanglement of 3D-aware generative models, particularly for face generation. The TRIOT training method allows for efficient fine-tuning of a pre-trained 3D-aware model, improving attribute editing precision. This approach could have significant implications for developing more controllable and semantically-aware 3D generative models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Training and Tuning Generative Neural Radiance Fields for Attribute-Conditional 3D-Aware Face Generation
Jichao Zhang, Aliaksandr Siarohin, Yahui Liu, Hao Tang, Nicu Sebe, Wei Wang
Generative Neural Radiance Fields (GNeRF)-based 3D-aware GANs have showcased remarkable prowess in crafting high-fidelity images while upholding robust 3D consistency, particularly face generation. However, specific existing models prioritize view consistency over disentanglement, leading to constrained semantic or attribute control during the generation process. While many methods have explored incorporating semantic masks or leveraging 3D Morphable Models (3DMM) priors to imbue models with semantic control, these methods often demand training from scratch, entailing significant computational overhead. In this paper, we propose a novel approach: a conditional GNeRF model that integrates specific attribute labels as input, thus amplifying the controllability and disentanglement capabilities of 3D-aware generative models. Our approach builds upon a pre-trained 3D-aware face model, and we introduce a Training as Init and Optimizing for Tuning (TRIOT) method to train a conditional normalized flow module to enable the facial attribute editing, then optimize the latent vector to improve attribute-editing precision further. Our extensive experiments substantiate the efficacy of our model, showcasing its ability to generate high-quality edits with enhanced view consistency while safeguarding non-target regions. The code for our model is publicly available at https://github.com/zhangqianhui/TT-GNeRF.
Read more9/4/2024
🧪
0
HyperNeRFGAN: Hypernetwork approach to 3D NeRF GAN
Adam Kania, Artur Kasymov, Jakub Ko'sciukiewicz, Artur G'orak, Marcin Mazur, Maciej Zik{e}ba, Przemys{l}aw Spurek
The recent surge in popularity of deep generative models for 3D objects has highlighted the need for more efficient training methods, particularly given the difficulties associated with training with conventional 3D representations, such as voxels or point clouds. Neural Radiance Fields (NeRFs), which provide the current benchmark in terms of quality for the generation of novel views of complex 3D scenes from a limited set of 2D images, represent a promising solution to this challenge. However, the training of these models requires the knowledge of the respective camera positions from which the images were viewed. In this paper, we overcome this limitation by introducing HyperNeRFGAN, a Generative Adversarial Network (GAN) architecture employing a hypernetwork paradigm to transform a Gaussian noise into the weights of a NeRF architecture that does not utilize viewing directions in its training phase. Consequently, as evidenced by the findings of our experimental study, the proposed model, despite its notable simplicity in comparison to existing state-of-the-art alternatives, demonstrates superior performance on a diverse range of image datasets where camera position estimation is challenging, particularly in the context of medical data.
Read more8/23/2024
📊
0
DatasetNeRF: Efficient 3D-aware Data Factory with Generative Radiance Fields
Yu Chi, Fangneng Zhan, Sibo Wu, Christian Theobalt, Adam Kortylewski
Progress in 3D computer vision tasks demands a huge amount of data, yet annotating multi-view images with 3D-consistent annotations, or point clouds with part segmentation is both time-consuming and challenging. This paper introduces DatasetNeRF, a novel approach capable of generating infinite, high-quality 3D-consistent 2D annotations alongside 3D point cloud segmentations, while utilizing minimal 2D human-labeled annotations. Specifically, we leverage the strong semantic prior within a 3D generative model to train a semantic decoder, requiring only a handful of fine-grained labeled samples. Once trained, the decoder efficiently generalizes across the latent space, enabling the generation of infinite data. The generated data is applicable across various computer vision tasks, including video segmentation and 3D point cloud segmentation. Our approach not only surpasses baseline models in segmentation quality, achieving superior 3D consistency and segmentation precision on individual images, but also demonstrates versatility by being applicable to both articulated and non-articulated generative models. Furthermore, we explore applications stemming from our approach, such as 3D-aware semantic editing and 3D inversion.
Read more8/20/2024
0
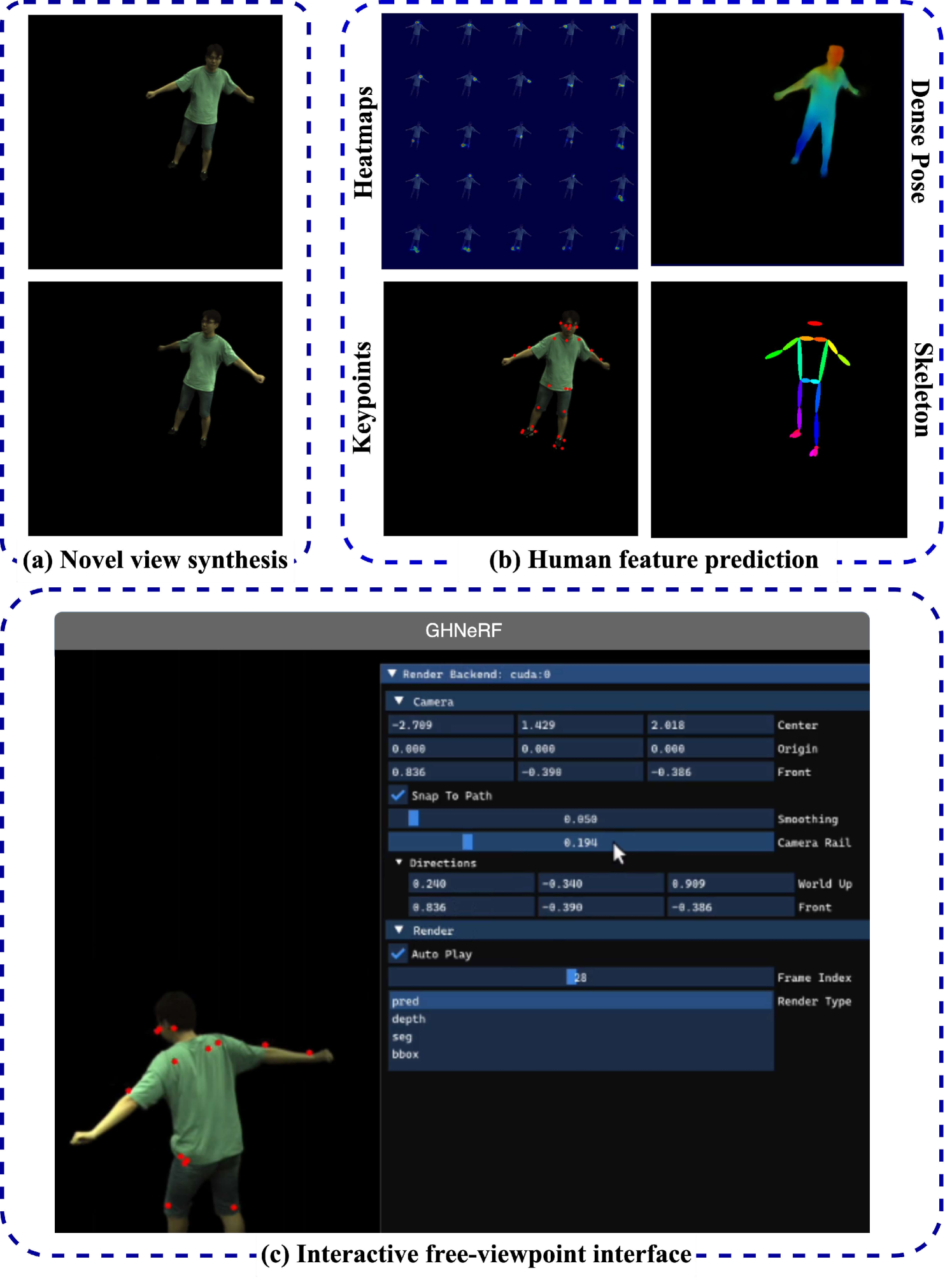
GHNeRF: Learning Generalizable Human Features with Efficient Neural Radiance Fields
Arnab Dey, Di Yang, Rohith Agaram, Antitza Dantcheva, Andrew I. Comport, Srinath Sridhar, Jean Martinet
Recent advances in Neural Radiance Fields (NeRF) have demonstrated promising results in 3D scene representations, including 3D human representations. However, these representations often lack crucial information on the underlying human pose and structure, which is crucial for AR/VR applications and games. In this paper, we introduce a novel approach, termed GHNeRF, designed to address these limitations by learning 2D/3D joint locations of human subjects with NeRF representation. GHNeRF uses a pre-trained 2D encoder streamlined to extract essential human features from 2D images, which are then incorporated into the NeRF framework in order to encode human biomechanic features. This allows our network to simultaneously learn biomechanic features, such as joint locations, along with human geometry and texture. To assess the effectiveness of our method, we conduct a comprehensive comparison with state-of-the-art human NeRF techniques and joint estimation algorithms. Our results show that GHNeRF can achieve state-of-the-art results in near real-time.
Read more4/10/2024