Trajectory-wise Iterative Reinforcement Learning Framework for Auto-bidding
2402.15102
0
0
Abstract
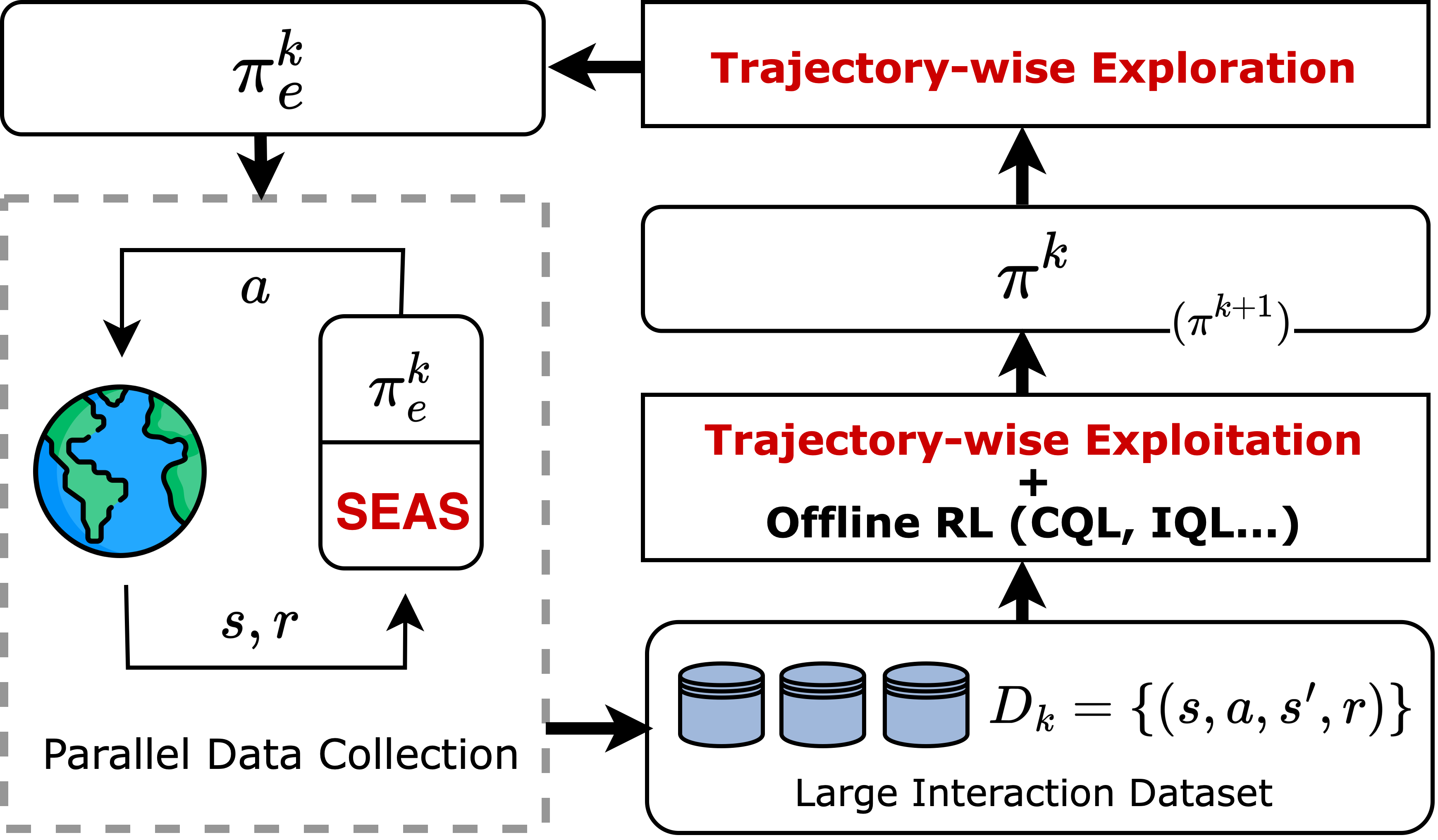
In online advertising, advertisers participate in ad auctions to acquire ad opportunities, often by utilizing auto-bidding tools provided by demand-side platforms (DSPs). The current auto-bidding algorithms typically employ reinforcement learning (RL). However, due to safety concerns, most RL-based auto-bidding policies are trained in simulation, leading to a performance degradation when deployed in online environments. To narrow this gap, we can deploy multiple auto-bidding agents in parallel to collect a large interaction dataset. Offline RL algorithms can then be utilized to train a new policy. The trained policy can subsequently be deployed for further data collection, resulting in an iterative training framework, which we refer to as iterative offline RL. In this work, we identify the performance bottleneck of this iterative offline RL framework, which originates from the ineffective exploration and exploitation caused by the inherent conservatism of offline RL algorithms. To overcome this bottleneck, we propose Trajectory-wise Exploration and Exploitation (TEE), which introduces a novel data collecting and data utilization method for iterative offline RL from a trajectory perspective. Furthermore, to ensure the safety of online exploration while preserving the dataset quality for TEE, we propose Safe Exploration by Adaptive Action Selection (SEAS). Both offline experiments and real-world experiments on Alibaba display advertising platform demonstrate the effectiveness of our proposed method.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel framework for auto-bidding in real-time bidding (RTB) advertising using an iterative reinforcement learning approach.
- The proposed framework, called Trajectory-wise Iterative Reinforcement Learning (TIRL), learns a bidding strategy by optimizing the cumulative rewards obtained from historical bidding trajectories.
- TIRL is designed to address the challenges of offline reinforcement learning, where the agent has access only to historical data and not to a live environment.
Plain English Explanation
The paper introduces a new way for companies to automatically bid on advertising slots in real-time bidding (RTB) markets. RTB is a system where advertisers can bid on individual ad impressions, similar to an auction, to determine which ads are shown to users.
The authors have developed a [Bayesian approach to robust inverse reinforcement learning] that allows companies to learn an optimal bidding strategy by analyzing their past bidding history, without needing to test new strategies in a live environment. This is important because companies cannot easily experiment with different bidding strategies in a live RTB market, as that could lead to lost revenue.
The key innovation of this framework, called [Trajectory-wise Iterative Reinforcement Learning (TIRL)], is that it optimizes the bidding strategy by looking at entire sequences of past bids (called "trajectories") rather than just individual bids. This allows the system to learn more nuanced relationships between the bidding behavior and the resulting rewards (e.g., ad clicks or conversions).
The authors show through experiments that TIRL can outperform other offline reinforcement learning techniques, such as [solving continual offline reinforcement learning] and [autonomous driving benchmarks], in terms of the final bidding strategy's performance.
Technical Explanation
The paper formulates the auto-bidding problem as an [offline reinforcement learning] task, where the agent (the bidding algorithm) must learn an optimal bidding strategy based on historical data, without interacting with a live RTB environment.
The [Trajectory-wise Iterative Reinforcement Learning (TIRL)] framework proposed in the paper consists of two key components:
-
Trajectory-wise Reward Estimation: Instead of estimating rewards for individual bids, TIRL estimates rewards for entire bidding trajectories (sequences of bids). This allows the system to capture the long-term impact of bidding decisions.
-
Iterative Policy Improvement: TIRL iteratively updates the bidding policy by solving an optimization problem that maximizes the estimated trajectory-wise rewards. This is done without requiring access to a live environment.
The authors evaluate TIRL against several baselines, including [extremum seeking action selection] and [efficient reinforcement learning task planners], on both synthetic and real-world RTB data. The results show that TIRL can significantly outperform these other offline reinforcement learning approaches in terms of the final bidding strategy's performance.
Critical Analysis
The paper presents a novel and promising approach to the challenging problem of auto-bidding in RTB markets using offline reinforcement learning. The authors have carefully designed the TIRL framework to address the key challenges of this setting, such as the need to learn from historical data without live experimentation.
One potential limitation of the research is the reliance on simulated environments and synthetic data for a significant portion of the experiments. While the authors do evaluate TIRL on real-world RTB data as well, it would be valuable to see more extensive real-world testing to fully validate the approach's practical effectiveness.
Additionally, the paper does not delve deeply into the potential biases or skewed perspectives that may arise from learning solely from historical data, which is a common concern in offline reinforcement learning. The authors could have discussed strategies to mitigate such issues or acknowledged them as areas for further research.
Overall, the [Trajectory-wise Iterative Reinforcement Learning (TIRL)] framework represents an important contribution to the field of auto-bidding and offline reinforcement learning. The authors have demonstrated the potential of their approach, and further research in this direction could lead to significant advancements in the practical application of these techniques in real-world RTB markets.
Conclusion
This paper introduces a novel [Trajectory-wise Iterative Reinforcement Learning (TIRL)] framework for auto-bidding in real-time bidding (RTB) advertising. The key innovation of TIRL is its ability to learn an optimal bidding strategy by optimizing the cumulative rewards obtained from historical bidding trajectories, without requiring access to a live RTB environment.
The authors have shown through extensive experiments that TIRL can outperform other offline reinforcement learning approaches in terms of the final bidding strategy's performance. This work represents an important step forward in addressing the challenges of offline reinforcement learning and has the potential to significantly impact the way companies approach auto-bidding in RTB markets.
As the digital advertising industry continues to evolve, techniques like TIRL could become increasingly valuable in helping companies navigate the complexities of RTB and make more informed, data-driven decisions about their advertising strategies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Offline Reinforcement Learning with Behavioral Supervisor Tuning
Padmanaba Srinivasan, William Knottenbelt
0
0
Offline reinforcement learning (RL) algorithms are applied to learn performant, well-generalizing policies when provided with a static dataset of interactions. Many recent approaches to offline RL have seen substantial success, but with one key caveat: they demand substantial per-dataset hyperparameter tuning to achieve reported performance, which requires policy rollouts in the environment to evaluate; this can rapidly become cumbersome. Furthermore, substantial tuning requirements can hamper the adoption of these algorithms in practical domains. In this paper, we present TD3 with Behavioral Supervisor Tuning (TD3-BST), an algorithm that trains an uncertainty model and uses it to guide the policy to select actions within the dataset support. TD3-BST can learn more effective policies from offline datasets compared to previous methods and achieves the best performance across challenging benchmarks without requiring per-dataset tuning.
4/26/2024
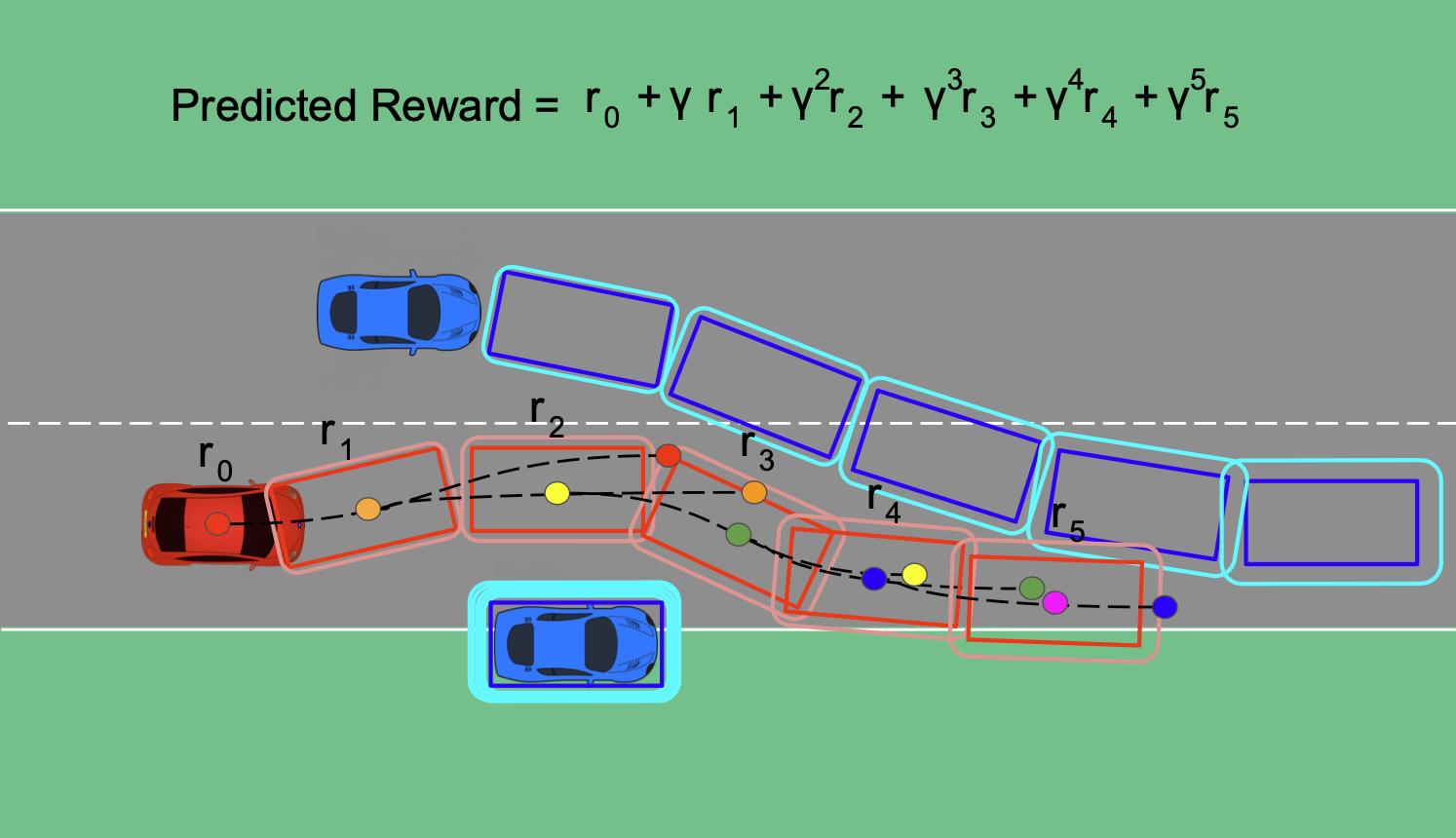
Trajectory Planning for Autonomous Vehicle Using Iterative Reward Prediction in Reinforcement Learning
Hyunwoo Park
0
0
Traditional trajectory planning methods for autonomous vehicles have several limitations. For example, heuristic and explicit simple rules limit generalizability and hinder complex motions. These limitations can be addressed using reinforcement learning-based trajectory planning. However, reinforcement learning suffers from unstable learning, and existing reinforcement learning-based trajectory planning methods do not consider the uncertainties. Thus, this paper, proposes a reinforcement learning-based trajectory planning method for autonomous vehicles. The proposed method involves an iterative reward prediction approach that iteratively predicts expectations of future states. These predicted states are then used to forecast rewards and integrated into the learning process to enhance stability. Additionally, a method is proposed that utilizes uncertainty propagation to make the reinforcement learning agent aware of uncertainties. The proposed method was evaluated using the CARLA simulator. Compared to the baseline methods, the proposed method reduced the collision rate by 60.17 %, and increased the average reward by 30.82 times. A video of the proposed method is available at https://www.youtube.com/watch?v=PfDbaeLfcN4.
5/14/2024

Offline Policy Evaluation for Reinforcement Learning with Adaptively Collected Data
Sunil Madhow, Dan Qiao, Ming Yin, Yu-Xiang Wang
0
0
Developing theoretical guarantees on the sample complexity of offline RL methods is an important step towards making data-hungry RL algorithms practically viable. Currently, most results hinge on unrealistic assumptions about the data distribution -- namely that it comprises a set of i.i.d. trajectories collected by a single logging policy. We consider a more general setting where the dataset may have been gathered adaptively. We develop theory for the TMIS Offline Policy Evaluation (OPE) estimator in this generalized setting for tabular MDPs, deriving high-probability, instance-dependent bounds on its estimation error. We also recover minimax-optimal offline learning in the adaptive setting. Finally, we conduct simulations to empirically analyze the behavior of these estimators under adaptive and non-adaptive regimes.
5/2/2024
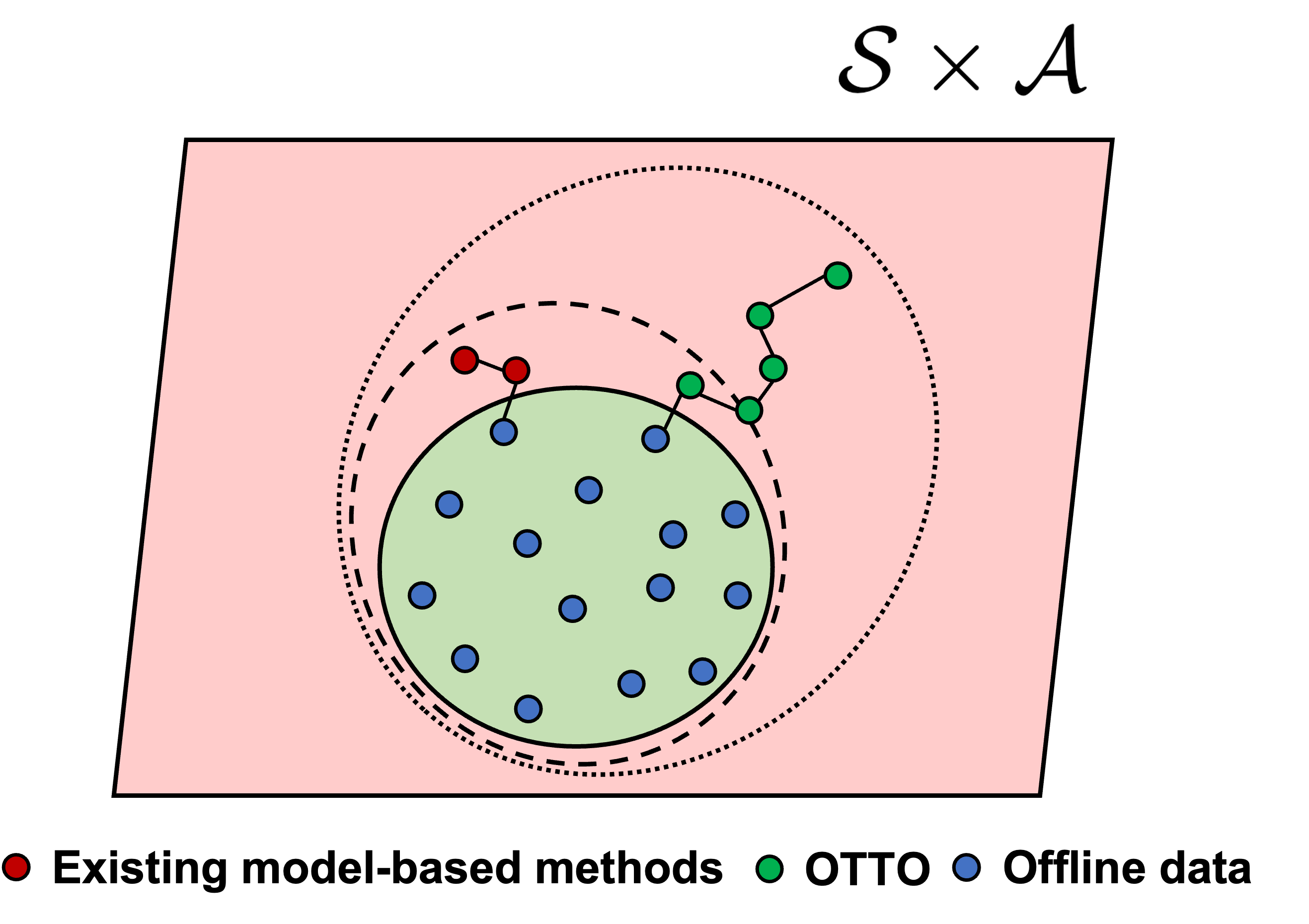
Offline Trajectory Generalization for Offline Reinforcement Learning
Ziqi Zhao, Zhaochun Ren, Liu Yang, Fajie Yuan, Pengjie Ren, Zhumin Chen, jun Ma, Xin Xin
0
0
Offline reinforcement learning (RL) aims to learn policies from static datasets of previously collected trajectories. Existing methods for offline RL either constrain the learned policy to the support of offline data or utilize model-based virtual environments to generate simulated rollouts. However, these methods suffer from (i) poor generalization to unseen states; and (ii) trivial improvement from low-qualified rollout simulation. In this paper, we propose offline trajectory generalization through world transformers for offline reinforcement learning (OTTO). Specifically, we use casual Transformers, a.k.a. World Transformers, to predict state dynamics and the immediate reward. Then we propose four strategies to use World Transformers to generate high-rewarded trajectory simulation by perturbing the offline data. Finally, we jointly use offline data with simulated data to train an offline RL algorithm. OTTO serves as a plug-in module and can be integrated with existing offline RL methods to enhance them with better generalization capability of transformers and high-rewarded data augmentation. Conducting extensive experiments on D4RL benchmark datasets, we verify that OTTO significantly outperforms state-of-the-art offline RL methods.
4/17/2024