Trajectory Planning for Autonomous Vehicle Using Iterative Reward Prediction in Reinforcement Learning
2404.12079
0
0
Abstract
Traditional trajectory planning methods for autonomous vehicles have several limitations. For example, heuristic and explicit simple rules limit generalizability and hinder complex motions. These limitations can be addressed using reinforcement learning-based trajectory planning. However, reinforcement learning suffers from unstable learning, and existing reinforcement learning-based trajectory planning methods do not consider the uncertainties. Thus, this paper, proposes a reinforcement learning-based trajectory planning method for autonomous vehicles. The proposed method involves an iterative reward prediction approach that iteratively predicts expectations of future states. These predicted states are then used to forecast rewards and integrated into the learning process to enhance stability. Additionally, a method is proposed that utilizes uncertainty propagation to make the reinforcement learning agent aware of uncertainties. The proposed method was evaluated using the CARLA simulator. Compared to the baseline methods, the proposed method reduced the collision rate by 60.17 %, and increased the average reward by 30.82 times. A video of the proposed method is available at https://www.youtube.com/watch?v=PfDbaeLfcN4.
Create account to get full access
Overview
- This paper presents a novel approach for trajectory planning of autonomous vehicles using reinforcement learning with iterative reward prediction.
- The proposed method aims to enable autonomous vehicles to navigate complex environments by learning optimal trajectories through an iterative process of reward prediction.
- The authors evaluate their approach using simulation experiments and compare it to other reinforcement learning-based methods for autonomous vehicle navigation.
Plain English Explanation
The paper describes a way for self-driving cars to plan their movements as they navigate through the world. Traditional approaches to this problem often rely on pre-programmed rules or models that can struggle to handle the complexity of real-world driving conditions.
Instead, the researchers use a technique called reinforcement learning. This involves training the car's "brain" (the AI system) by rewarding it when it makes good decisions, and punishing it when it makes bad ones. Over many trials, the system learns to predict the best actions to take in different situations.
The key innovation in this paper is an "iterative reward prediction" process. Rather than just trying to maximize a single reward signal, the system tries to anticipate how its actions will impact future rewards several steps down the line. This allows it to plan more sophisticated, long-term trajectories that navigate complex environments more effectively.
The authors test their approach in simulations and compare it to other reinforcement learning techniques for self-driving. They find that their iterative reward prediction method outperforms these other approaches, suggesting it could be a promising direction for real-world autonomous vehicle navigation.
Technical Explanation
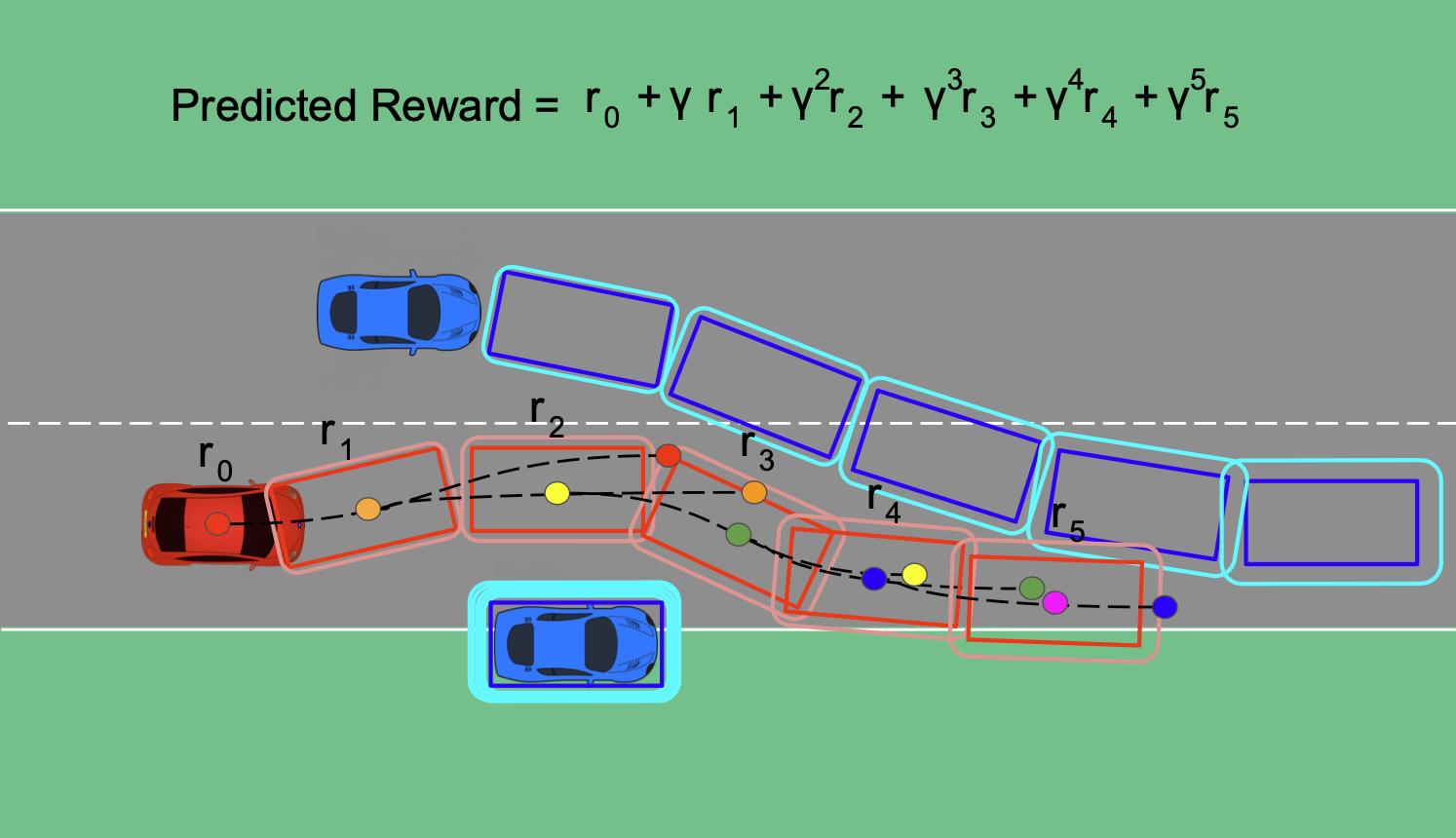
The authors propose a reinforcement learning-based framework for autonomous vehicle trajectory planning that employs an iterative reward prediction mechanism. The core idea is to enable the agent to anticipate the long-term consequences of its actions, rather than just optimizing for immediate rewards.
The system first encodes the current state of the vehicle and its environment as a input feature vector. It then uses a neural network-based policy function to predict the optimal action to take. Crucially, this policy also outputs a predicted reward for that action, not just the action itself.
The agent then simulates executing that action and observes the actual reward it receives. It compares this to its predicted reward, and uses the difference to update the policy network's weights through backpropagation. This "iterative reward prediction" process allows the agent to continually refine its understanding of the environment dynamics and learn better long-term decision making.
The authors evaluate their approach in simulation environments with varying levels of complexity, such as highway driving with dynamic obstacles and multi-agent scenarios. They compare it to other reinforcement learning baselines like Deep Q-Networks and find significant performance improvements, in terms of metrics like collision avoidance and travel time.
Critical Analysis
The authors provide a thorough evaluation of their proposed method, exploring various simulation scenarios and comparing to relevant baselines. This lends credibility to their claims about the effectiveness of iterative reward prediction for autonomous vehicle navigation.
However, the paper does not address some important practical considerations for real-world deployment. For example, the simulation environments are relatively simplistic and lack the full complexity of urban driving. The authors also do not discuss how their approach would handle sensor noise, communication latency, or other real-world challenges.
Additionally, the training process assumes the agent has access to perfect information about the state of the environment. In practice, autonomous vehicles must make decisions based on noisy, partial observations from onboard sensors. Extending the iterative reward prediction framework to handle partial observability could be an important area for future research.
Finally, the authors do not explore the computational and memory requirements of their approach, which could be a significant practical concern for real-time deployment on resource-constrained vehicle hardware.
Conclusion
Overall, this paper presents a promising new technique for autonomous vehicle trajectory planning using reinforcement learning with iterative reward prediction. By training the agent to anticipate long-term consequences of its actions, the authors demonstrate significant performance improvements over other RL-based methods.
While the simulation results are encouraging, further research is needed to address the practical challenges of deploying such a system in the real world. Incorporating partial observability, sensor uncertainty, and computational constraints could help bridge the gap between the laboratory and the open road.
If these challenges can be overcome, the iterative reward prediction approach could represent an important step forward in making autonomous vehicles a safe and reliable reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Trajectory Planning using Reinforcement Learning for Interactive Overtaking Maneuvers in Autonomous Racing Scenarios
Levent Ogretmen, Mo Chen, Phillip Pitschi, Boris Lohmann
0
0
Conventional trajectory planning approaches for autonomous racing are based on the sequential execution of prediction of the opposing vehicles and subsequent trajectory planning for the ego vehicle. If the opposing vehicles do not react to the ego vehicle, they can be predicted accurately. However, if there is interaction between the vehicles, the prediction loses its validity. For high interaction, instead of a planning approach that reacts exclusively to the fixed prediction, a trajectory planning approach is required that incorporates the interaction with the opposing vehicles. This paper demonstrates the limitations of a widely used conventional sampling-based approach within a highly interactive blocking scenario. We show that high success rates are achieved for less aggressive blocking behavior but that the collision rate increases with more significant interaction. We further propose a novel Reinforcement Learning (RL)-based trajectory planning approach for racing that explicitly exploits the interaction with the opposing vehicle without requiring a prediction. In contrast to the conventional approach, the RL-based approach achieves high success rates even for aggressive blocking behavior. Furthermore, we propose a novel safety layer (SL) that intervenes when the trajectory generated by the RL-based approach is infeasible. In that event, the SL generates a sub-optimal but feasible trajectory, avoiding termination of the scenario due to a not found valid solution.
4/17/2024
🔍
Autonomous Algorithm for Training Autonomous Vehicles with Minimal Human Intervention
Sang-Hyun Lee, Daehyeok Kwon, Seung-Woo Seo
0
0
Reinforcement learning (RL) provides a compelling framework for enabling autonomous vehicles to continue to learn and improve diverse driving behaviors on their own. However, training real-world autonomous vehicles with current RL algorithms presents several challenges. One critical challenge, often overlooked in these algorithms, is the need to reset a driving environment between every episode. While resetting an environment after each episode is trivial in simulated settings, it demands significant human intervention in the real world. In this paper, we introduce a novel autonomous algorithm that allows off-the-shelf RL algorithms to train an autonomous vehicle with minimal human intervention. Our algorithm takes into account the learning progress of the autonomous vehicle to determine when to abort episodes before it enters unsafe states and where to reset it for subsequent episodes in order to gather informative transitions. The learning progress is estimated based on the novelty of both current and future states. We also take advantage of rule-based autonomous driving algorithms to safely reset an autonomous vehicle to an initial state. We evaluate our algorithm against baselines on diverse urban driving tasks. The experimental results show that our algorithm is task-agnostic and achieves better driving performance with fewer manual resets than baselines.
5/24/2024

New!Let Hybrid A* Path Planner Obey Traffic Rules: A Deep Reinforcement Learning-Based Planning Framework
Xibo Li, Shruti Patel, Christof Buskens
0
0
Deep reinforcement learning (DRL) allows a system to interact with its environment and take actions by training an efficient policy that maximizes self-defined rewards. In autonomous driving, it can be used as a strategy for high-level decision making, whereas low-level algorithms such as the hybrid A* path planning have proven their ability to solve the local trajectory planning problem. In this work, we combine these two methods where the DRL makes high-level decisions such as lane change commands. After obtaining the lane change command, the hybrid A* planner is able to generate a collision-free trajectory to be executed by a model predictive controller (MPC). In addition, the DRL algorithm is able to keep the lane change command consistent within a chosen time-period. Traffic rules are implemented using linear temporal logic (LTL), which is then utilized as a reward function in DRL. Furthermore, we validate the proposed method on a real system to demonstrate its feasibility from simulation to implementation on real hardware.
7/2/2024

A survey on robustness in trajectory prediction for autonomous vehicles
Jeroen Hagenus, Frederik Baymler Mathiesen, Julian F. Schumann, Arkady Zgonnikov
0
0
Autonomous vehicles rely on accurate trajectory prediction to inform decision-making processes related to navigation and collision avoidance. However, current trajectory prediction models show signs of overfitting, which may lead to unsafe or suboptimal behavior. To address these challenges, this paper presents a comprehensive framework that categorizes and assesses the definitions and strategies used in the literature on evaluating and improving the robustness of trajectory prediction models. This involves a detailed exploration of various approaches, including data slicing methods, perturbation techniques, model architecture changes, and post-training adjustments. In the literature, we see many promising methods for increasing robustness, which are necessary for safe and reliable autonomous driving.
4/23/2024