TransDAE: Dual Attention Mechanism in a Hierarchical Transformer for Efficient Medical Image Segmentation

0

Sign in to get full access
Overview
- This paper introduces TransDAE, a hierarchical transformer model for efficient medical image segmentation.
- TransDAE uses a novel dual attention mechanism to capture both global and local features in medical images.
- The model demonstrates strong performance on medical image segmentation tasks while being computationally efficient.
Plain English Explanation
Medical image segmentation is the process of dividing an image into meaningful regions, such as identifying different organs or tissues. This is an important task in healthcare, as it can help doctors diagnose and monitor medical conditions more accurately.
The researchers behind this paper developed a new deep learning model called TransDAE that is designed to be efficient and effective at medical image segmentation. The key innovation of TransDAE is its "dual attention mechanism", which allows the model to focus on both global and local features in the images.
Typically, deep learning models for image segmentation either focus on the overall structure of the image (global features) or the fine-grained details (local features). TransDAE combines these two approaches by using two different attention mechanisms - one to capture the global context and one to focus on local, fine-grained details.
This dual attention approach allows TransDAE to perform medical image segmentation more accurately than previous models, while also being more computationally efficient. The researchers tested TransDAE on several medical imaging datasets and found that it outperformed other state-of-the-art models in terms of segmentation accuracy.
Technical Explanation
The key innovations in the TransDAE architecture are:
-
Hierarchical Transformer: TransDAE uses a hierarchical transformer design, with multiple transformer blocks stacked to capture features at different scales. This allows the model to understand both global and local context in the medical images.
-
Dual Attention Mechanism: The transformer blocks in TransDAE incorporate two types of attention - spatial attention and channel attention. Spatial attention focuses on the spatial relationships between different regions of the image, while channel attention captures interdependencies between different feature channels.
-
Efficient Design: To make TransDAE computationally efficient, the researchers used a lightweight CNN-based feature extractor and a novel "dual-pyramid" structure in the transformer blocks. This reduces the number of parameters and computational complexity compared to previous transformer-based models.
The researchers evaluated TransDAE on several medical image segmentation benchmarks, including CT, MRI, and microscopy datasets. They found that TransDAE outperformed existing state-of-the-art models in terms of segmentation accuracy, while also being more efficient in terms of inference time and memory usage.
Critical Analysis
One potential limitation of the TransDAE model is that it was only evaluated on 2D medical images, and the researchers did not explore its performance on 3D volumetric data, such as 3D CT or MRI scans. Extending the model to handle 3D data could be an important area for future research, as many clinical applications require segmentation of 3D medical images.
Additionally, the paper does not provide much insight into the interpretability of the TransDAE model - it is not clear what types of visual features or patterns the model is learning to perform the segmentation task. Improving the interpretability of the model could be valuable for building trust and understanding in clinical applications.
Another aspect that could be further explored is the model's robustness to different types of medical imaging artifacts or variations in image quality. Real-world medical images can often be noisy or affected by various factors, and it would be important to understand how well the TransDAE model can generalize to such challenging cases.
Conclusion
In summary, the TransDAE model introduces a novel hierarchical transformer architecture with a dual attention mechanism to address the task of efficient medical image segmentation. By capturing both global and local features, TransDAE demonstrates strong performance on several medical imaging benchmarks while being computationally efficient.
The key innovations of TransDAE, such as its hierarchical design and dual attention mechanism, could have broader implications for the development of advanced deep learning models for medical image analysis. As medical imaging data continues to grow in volume and complexity, efficient and effective segmentation algorithms will be increasingly important for supporting clinical decision-making and improving patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TransDAE: Dual Attention Mechanism in a Hierarchical Transformer for Efficient Medical Image Segmentation
Bobby Azad, Pourya Adibfar, Kaiqun Fu
In healthcare, medical image segmentation is crucial for accurate disease diagnosis and the development of effective treatment strategies. Early detection can significantly aid in managing diseases and potentially prevent their progression. Machine learning, particularly deep convolutional neural networks, has emerged as a promising approach to addressing segmentation challenges. Traditional methods like U-Net use encoding blocks for local representation modeling and decoding blocks to uncover semantic relationships. However, these models often struggle with multi-scale objects exhibiting significant variations in texture and shape, and they frequently fail to capture long-range dependencies in the input data. Transformers designed for sequence-to-sequence predictions have been proposed as alternatives, utilizing global self-attention mechanisms. Yet, they can sometimes lack precise localization due to insufficient granular details. To overcome these limitations, we introduce TransDAE: a novel approach that reimagines the self-attention mechanism to include both spatial and channel-wise associations across the entire feature space, while maintaining computational efficiency. Additionally, TransDAE enhances the skip connection pathway with an inter-scale interaction module, promoting feature reuse and improving localization accuracy. Remarkably, TransDAE outperforms existing state-of-the-art methods on the Synaps multi-organ dataset, even without relying on pre-trained weights.
Read more9/4/2024
🖼️
0
Multi-dimension Transformer with Attention-based Filtering for Medical Image Segmentation
Wentao Wang, Xi Xiao, Mingjie Liu, Qing Tian, Xuanyao Huang, Qizhen Lan, Swalpa Kumar Roy, Tianyang Wang
The accurate segmentation of medical images is crucial for diagnosing and treating diseases. Recent studies demonstrate that vision transformer-based methods have significantly improved performance in medical image segmentation, primarily due to their superior ability to establish global relationships among features and adaptability to various inputs. However, these methods struggle with the low signal-to-noise ratio inherent to medical images. Additionally, the effective utilization of channel and spatial information, which are essential for medical image segmentation, is limited by the representation capacity of self-attention. To address these challenges, we propose a multi-dimension transformer with attention-based filtering (MDT-AF), which redesigns the patch embedding and self-attention mechanism for medical image segmentation. MDT-AF incorporates an attention-based feature filtering mechanism into the patch embedding blocks and employs a coarse-to-fine process to mitigate the impact of low signal-to-noise ratio. To better capture complex structures in medical images, MDT-AF extends the self-attention mechanism to incorporate spatial and channel dimensions, enriching feature representation. Moreover, we introduce an interaction mechanism to improve the feature aggregation between spatial and channel dimensions. Experimental results on three public medical image segmentation benchmarks show that MDT-AF achieves state-of-the-art (SOTA) performance.
Read more5/22/2024
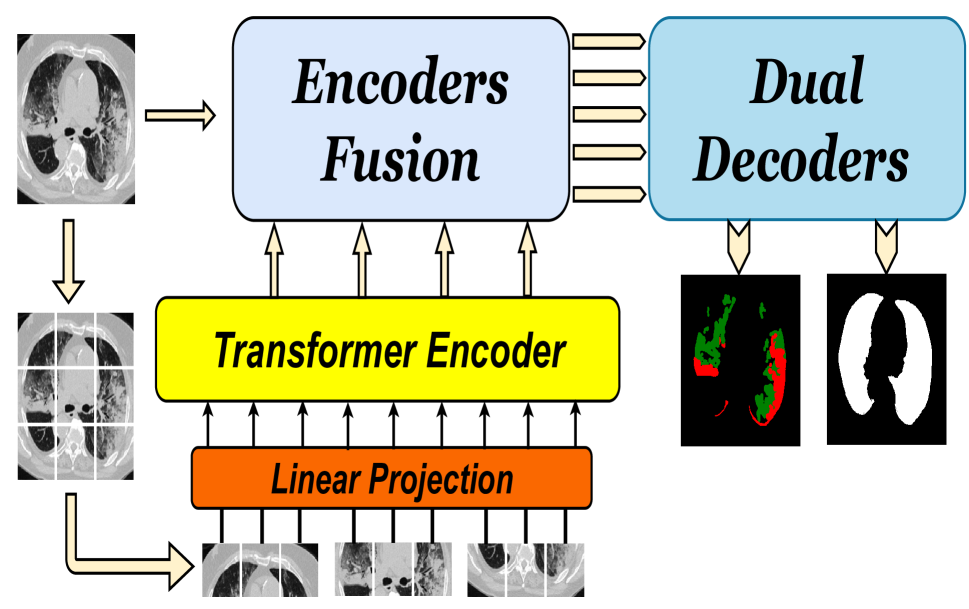
0
D-TrAttUnet: Toward Hybrid CNN-Transformer Architecture for Generic and Subtle Segmentation in Medical Images
Fares Bougourzi, Fadi Dornaika, Cosimo Distante, Abdelmalik Taleb-Ahmed
Over the past two decades, machine analysis of medical imaging has advanced rapidly, opening up significant potential for several important medical applications. As complicated diseases increase and the number of cases rises, the role of machine-based imaging analysis has become indispensable. It serves as both a tool and an assistant to medical experts, providing valuable insights and guidance. A particularly challenging task in this area is lesion segmentation, a task that is challenging even for experienced radiologists. The complexity of this task highlights the urgent need for robust machine learning approaches to support medical staff. In response, we present our novel solution: the D-TrAttUnet architecture. This framework is based on the observation that different diseases often target specific organs. Our architecture includes an encoder-decoder structure with a composite Transformer-CNN encoder and dual decoders. The encoder includes two paths: the Transformer path and the Encoders Fusion Module path. The Dual-Decoder configuration uses two identical decoders, each with attention gates. This allows the model to simultaneously segment lesions and organs and integrate their segmentation losses. To validate our approach, we performed evaluations on the Covid-19 and Bone Metastasis segmentation tasks. We also investigated the adaptability of the model by testing it without the second decoder in the segmentation of glands and nuclei. The results confirmed the superiority of our approach, especially in Covid-19 infections and the segmentation of bone metastases. In addition, the hybrid encoder showed exceptional performance in the segmentation of glands and nuclei, solidifying its role in modern medical image analysis.
Read more5/8/2024

0
Medical Image Segmentation Using Directional Window Attention
Daniya Najiha Abdul Kareem, Mustansar Fiaz, Noa Novershtern, Hisham Cholakkal
Accurate segmentation of medical images is crucial for diagnostic purposes, including cell segmentation, tumor identification, and organ localization. Traditional convolutional neural network (CNN)-based approaches struggled to achieve precise segmentation results due to their limited receptive fields, particularly in cases involving multi-organ segmentation with varying shapes and sizes. The transformer-based approaches address this limitation by leveraging the global receptive field, but they often face challenges in capturing local information required for pixel-precise segmentation. In this work, we introduce DwinFormer, a hierarchical encoder-decoder architecture for medical image segmentation comprising a directional window (Dwin) attention and global self-attention (GSA) for feature encoding. The focus of our design is the introduction of Dwin block within DwinFormer that effectively captures local and global information along the horizontal, vertical, and depthwise directions of the input feature map by separately performing attention in each of these directional volumes. To this end, our Dwin block introduces a nested Dwin attention (NDA) that progressively increases the receptive field in horizontal, vertical, and depthwise directions and a convolutional Dwin attention (CDA) that captures local contextual information for the attention computation. While the proposed Dwin block captures local and global dependencies at the first two high-resolution stages of DwinFormer, the GSA block encodes global dependencies at the last two lower-resolution stages. Experiments over the challenging 3D Synapse Multi-organ dataset and Cell HMS dataset demonstrate the benefits of our DwinFormer over the state-of-the-art approaches. Our source code will be publicly available at url{https://github.com/Daniyanaj/DWINFORMER}.
Read more6/26/2024