Transparent Image Layer Diffusion using Latent Transparency
2402.17113
43
0

Abstract
We present LayerDiffuse, an approach enabling large-scale pretrained latent diffusion models to generate transparent images. The method allows generation of single transparent images or of multiple transparent layers. The method learns a latent transparency that encodes alpha channel transparency into the latent manifold of a pretrained latent diffusion model. It preserves the production-ready quality of the large diffusion model by regulating the added transparency as a latent offset with minimal changes to the original latent distribution of the pretrained model. In this way, any latent diffusion model can be converted into a transparent image generator by finetuning it with the adjusted latent space. We train the model with 1M transparent image layer pairs collected using a human-in-the-loop collection scheme. We show that latent transparency can be applied to different open source image generators, or be adapted to various conditional control systems to achieve applications like foreground/background-conditioned layer generation, joint layer generation, structural control of layer contents, etc. A user study finds that in most cases (97%) users prefer our natively generated transparent content over previous ad-hoc solutions such as generating and then matting. Users also report the quality of our generated transparent images is comparable to real commercial transparent assets like Adobe Stock.
Create account to get full access
Overview
- This paper presents a novel method for embedding transparent image layers within a diffusion model using "latent transparency".
- The authors demonstrate how this technique can be used for transparent watermarking, stereo image generation, image editing, and more.
- Key contributions include a new diffusion-based architecture and training approach to enable transparent and flexible image manipulations.
Plain English Explanation
The researchers have developed a new way to embed transparent image layers within a diffusion model, a type of machine learning model used to generate images. This "latent transparency" technique allows for some parts of an image to be transparent or see-through, while other parts remain opaque.
<a href="https://aimodels.fyi/papers/arxiv/diffusetrace-transparent-flexible-watermarking-scheme-latent-diffusion">Transparent watermarking</a> is one application, where a logo or text could be invisibly embedded in an image. <a href="https://aimodels.fyi/papers/arxiv/stereodiffusion-training-free-stereo-image-generation-using">Stereo image generation</a> is another, creating a 3D effect by having two slightly offset views. <a href="https://aimodels.fyi/papers/arxiv/streamlining-image-editing-layered-diffusion-brushes">Image editing</a> can also benefit, allowing selected parts of an image to be modified without affecting the rest. And <a href="https://aimodels.fyi/papers/arxiv/move-anything-layered-scene-diffusion">scene manipulation</a> is possible, moving or replacing specific objects.
The key innovation is a new diffusion-based architecture and training approach that enables these transparent and flexible image manipulations, going beyond what was possible with previous diffusion models.
Technical Explanation
The paper introduces a novel diffusion-based model architecture and training procedure that enables the generation of images with transparent layers. This "latent transparency" approach encodes the transparency information in the latent space of the diffusion model, rather than directly in the output image.
<a href="https://aimodels.fyi/papers/arxiv/diffusetrace-transparent-flexible-watermarking-scheme-latent-diffusion">The authors demonstrate how this can be used for transparent watermarking</a>, where a logo or text is invisibly embedded in an image. <a href="https://aimodels.fyi/papers/arxiv/stereodiffusion-training-free-stereo-image-generation-using">They also show how it enables training-free stereo image generation</a>, creating a 3D effect by having two slightly offset views.
The model architecture includes a transparency encoder that learns to predict the transparency information in the latent space, and a transparency decoder that reconstructs the final transparent image. This is integrated with a standard diffusion model for image generation.
<a href="https://aimodels.fyi/papers/arxiv/streamlining-image-editing-layered-diffusion-brushes">The authors also present applications in image editing</a>, allowing selected parts of an image to be modified without affecting the rest. And <a href="https://aimodels.fyi/papers/arxiv/move-anything-layered-scene-diffusion">they demonstrate scene manipulation</a>, moving or replacing specific objects in a generated image.
Critical Analysis
The paper presents a compelling approach for enabling transparent and flexible image manipulations using diffusion models. The latent transparency technique is a novel contribution that expands the capabilities of these generative models.
However, the authors acknowledge some limitations. The transparent watermarking approach may be vulnerable to attacks that try to remove the embedded information. And the stereo image generation quality is not as high as specialized methods.
Additionally, the model complexity and computational requirements may limit its practical deployment, especially for real-time applications. Further research is needed to optimize the architecture and training process for improved efficiency and scalability.
More broadly, the potential misuse of such transparent manipulation techniques, such as for creating deepfakes, raises ethical concerns that warrant careful consideration and mitigation strategies.
Conclusion
This paper introduces a significant advance in diffusion-based image generation by enabling transparent and flexible image manipulations through the use of "latent transparency". The applications demonstrated, from watermarking to scene editing, showcase the versatility of this approach and its potential to impact various domains.
While some limitations and challenges exist, the core innovation represents an important step forward in the capabilities of generative models. As the field continues to evolve, addressing the identified issues and exploring the ethical implications of these technologies will be crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
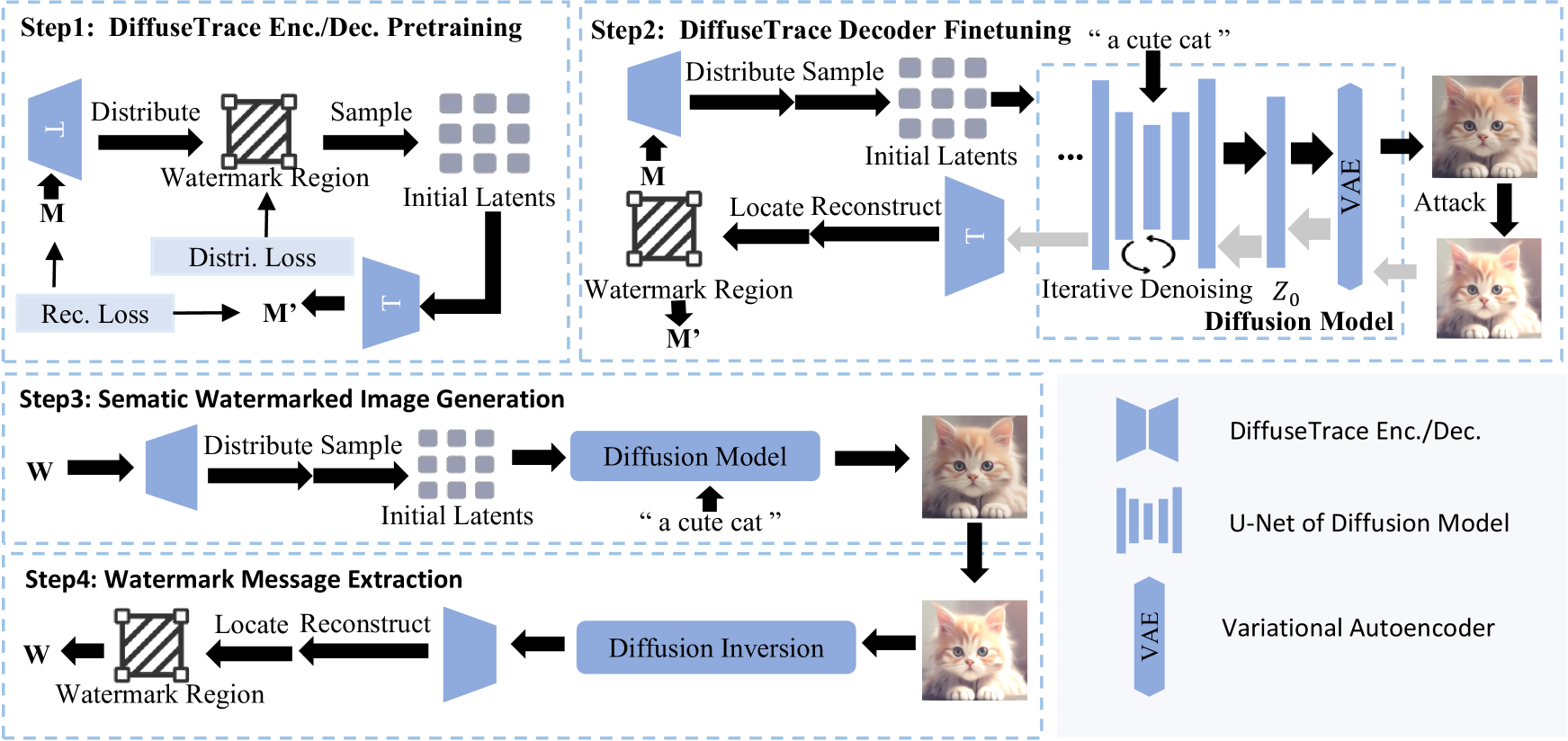
DiffuseTrace: A Transparent and Flexible Watermarking Scheme for Latent Diffusion Model
Liangqi Lei, Keke Gai, Jing Yu, Liehuang Zhu
0
0
Latent Diffusion Models (LDMs) enable a wide range of applications but raise ethical concerns regarding illegal utilization.Adding watermarks to generative model outputs is a vital technique employed for copyright tracking and mitigating potential risks associated with AI-generated content. However, post-hoc watermarking techniques are susceptible to evasion. Existing watermarking methods for LDMs can only embed fixed messages. Watermark message alteration requires model retraining. The stability of the watermark is influenced by model updates and iterations. Furthermore, the current reconstruction-based watermark removal techniques utilizing variational autoencoders (VAE) and diffusion models have the capability to remove a significant portion of watermarks. Therefore, we propose a novel technique called DiffuseTrace. The goal is to embed invisible watermarks in all generated images for future detection semantically. The method establishes a unified representation of the initial latent variables and the watermark information through training an encoder-decoder model. The watermark information is embedded into the initial latent variables through the encoder and integrated into the sampling process. The watermark information is extracted by reversing the diffusion process and utilizing the decoder. DiffuseTrace does not rely on fine-tuning of the diffusion model components. The watermark is embedded into the image space semantically without compromising image quality. The encoder-decoder can be utilized as a plug-in in arbitrary diffusion models. We validate through experiments the effectiveness and flexibility of DiffuseTrace. DiffuseTrace holds an unprecedented advantage in combating the latest attacks based on variational autoencoders and Diffusion Models.
5/9/2024

StereoDiffusion: Training-Free Stereo Image Generation Using Latent Diffusion Models
Lezhong Wang, Jeppe Revall Frisvad, Mark Bo Jensen, Siavash Arjomand Bigdeli
0
0
The demand for stereo images increases as manufacturers launch more XR devices. To meet this demand, we introduce StereoDiffusion, a method that, unlike traditional inpainting pipelines, is trainning free, remarkably straightforward to use, and it seamlessly integrates into the original Stable Diffusion model. Our method modifies the latent variable to provide an end-to-end, lightweight capability for fast generation of stereo image pairs, without the need for fine-tuning model weights or any post-processing of images. Using the original input to generate a left image and estimate a disparity map for it, we generate the latent vector for the right image through Stereo Pixel Shift operations, complemented by Symmetric Pixel Shift Masking Denoise and Self-Attention Layers Modification methods to align the right-side image with the left-side image. Moreover, our proposed method maintains a high standard of image quality throughout the stereo generation process, achieving state-of-the-art scores in various quantitative evaluations.
6/4/2024
🖼️
Streamlining Image Editing with Layered Diffusion Brushes
Peyman Gholami, Robert Xiao
0
0
Denoising diffusion models have recently gained prominence as powerful tools for a variety of image generation and manipulation tasks. Building on this, we propose a novel tool for real-time editing of images that provides users with fine-grained region-targeted supervision in addition to existing prompt-based controls. Our novel editing technique, termed Layered Diffusion Brushes, leverages prompt-guided and region-targeted alteration of intermediate denoising steps, enabling precise modifications while maintaining the integrity and context of the input image. We provide an editor based on Layered Diffusion Brushes modifications, which incorporates well-known image editing concepts such as layer masks, visibility toggles, and independent manipulation of layers; regardless of their order. Our system renders a single edit on a 512x512 image within 140 ms using a high-end consumer GPU, enabling real-time feedback and rapid exploration of candidate edits. We validated our method and editing system through a user study involving both natural images (using inversion) and generated images, showcasing its usability and effectiveness compared to existing techniques such as InstructPix2Pix and Stable Diffusion Inpainting for refining images. Our approach demonstrates efficacy across a range of tasks, including object attribute adjustments, error correction, and sequential prompt-based object placement and manipulation, demonstrating its versatility and potential for enhancing creative workflows.
5/2/2024

Move Anything with Layered Scene Diffusion
Jiawei Ren, Mengmeng Xu, Jui-Chieh Wu, Ziwei Liu, Tao Xiang, Antoine Toisoul
0
0
Diffusion models generate images with an unprecedented level of quality, but how can we freely rearrange image layouts? Recent works generate controllable scenes via learning spatially disentangled latent codes, but these methods do not apply to diffusion models due to their fixed forward process. In this work, we propose SceneDiffusion to optimize a layered scene representation during the diffusion sampling process. Our key insight is that spatial disentanglement can be obtained by jointly denoising scene renderings at different spatial layouts. Our generated scenes support a wide range of spatial editing operations, including moving, resizing, cloning, and layer-wise appearance editing operations, including object restyling and replacing. Moreover, a scene can be generated conditioned on a reference image, thus enabling object moving for in-the-wild images. Notably, this approach is training-free, compatible with general text-to-image diffusion models, and responsive in less than a second.
4/11/2024