StereoDiffusion: Training-Free Stereo Image Generation Using Latent Diffusion Models
2403.04965
0
0

Abstract
The demand for stereo images increases as manufacturers launch more XR devices. To meet this demand, we introduce StereoDiffusion, a method that, unlike traditional inpainting pipelines, is trainning free, remarkably straightforward to use, and it seamlessly integrates into the original Stable Diffusion model. Our method modifies the latent variable to provide an end-to-end, lightweight capability for fast generation of stereo image pairs, without the need for fine-tuning model weights or any post-processing of images. Using the original input to generate a left image and estimate a disparity map for it, we generate the latent vector for the right image through Stereo Pixel Shift operations, complemented by Symmetric Pixel Shift Masking Denoise and Self-Attention Layers Modification methods to align the right-side image with the left-side image. Moreover, our proposed method maintains a high standard of image quality throughout the stereo generation process, achieving state-of-the-art scores in various quantitative evaluations.
Create account to get full access
Overview
• This paper presents StereoDiffusion, a novel method for generating stereo images using a pre-trained latent diffusion model without additional training.
• StereoDiffusion leverages the powerful capabilities of latent diffusion models to generate high-quality stereo image pairs from a single input image, enabling 3D visualization and depth perception.
• The approach does not require specialized training on stereo data, making it a versatile and accessible technique for a wide range of applications, including virtual reality, 3D content creation, and computational photography.
Plain English Explanation
StereoDiffusion: Training-Free Stereo Image Generation Using Latent Diffusion Models is a new method for creating 3D images from a single 2D picture. It uses a pre-trained machine learning model called a "latent diffusion model" to generate a pair of images that, when viewed together, create a 3D effect.
The key innovation is that this process doesn't require any additional training on stereo image data. The latent diffusion model has already learned the necessary skills to generate high-quality images, and the researchers found a way to adapt this model to create stereo pairs without needing to retrain it from scratch.
This is significant because it makes the technique much more accessible and flexible. Rather than having to collect and curate a large dataset of stereo images to train a new model, StereoDiffusion can be applied to a wide range of existing 2D images to generate their 3D counterparts. This opens up new possibilities for virtual reality, 3D content creation, computational photography, and other applications that rely on 3D visual information.
Technical Explanation
StereoDiffusion: Training-Free Stereo Image Generation Using Latent Diffusion Models introduces a novel approach for generating stereo image pairs from a single input image using a pre-trained latent diffusion model.
Latent diffusion models are a type of generative AI that can create high-quality images by learning the underlying patterns and structures in a dataset. The key insight behind StereoDiffusion is that these models can be repurposed to generate stereo image pairs without requiring any additional training on stereo-specific data.
The researchers develop a two-stage process: first, they use the pre-trained latent diffusion model to generate a high-quality 2D image from the input. Then, they introduce a specialized module that takes this 2D image and predicts the corresponding stereo pair, leveraging the latent representations learned by the diffusion model.
Critically, this approach does not require collecting and training on a dataset of stereo images, which can be a significant bottleneck for many 3D content generation methods. Instead, StereoDiffusion is able to generate high-quality stereo pairs directly from 2D input, making it a more accessible and flexible solution.
The paper presents extensive experiments demonstrating the effectiveness of StereoDiffusion on a range of image types, as well as comparisons to alternative stereo generation approaches. The results show that StereoDiffusion can produce stereo image pairs with compelling depth and 3D effects, all without the need for specialized training.
Critical Analysis
The StereoDiffusion paper presents a compelling and innovative approach to stereo image generation, but it's important to consider some potential limitations and areas for further research.
One key concern is the reliance on a pre-trained latent diffusion model, which may introduce biases or limitations in the generated stereo pairs. While the authors demonstrate impressive results, it's possible that certain image types or domains may not be well-handled by the pre-trained model, requiring further adjustments or fine-tuning.
Additionally, the paper does not provide a thorough analysis of the generated stereo pairs' depth accuracy or perceptual quality. Further user studies and quantitative evaluations would be helpful to fully assess the practical utility of StereoDiffusion for real-world applications.
Another area for exploration is the potential to incorporate additional input modalities, such as depth maps or semantic segmentation, to further improve the quality and accuracy of the generated stereo pairs. Integrating such complementary information could lead to more robust and versatile stereo generation capabilities.
Despite these potential limitations, the StereoDiffusion approach represents a significant advancement in the field of 3D content creation, offering a promising path forward for making stereo image generation more accessible and practical.
Conclusion
StereoDiffusion: Training-Free Stereo Image Generation Using Latent Diffusion Models presents a novel and innovative method for generating high-quality stereo image pairs from a single input image, without the need for specialized training on stereo data.
By leveraging the powerful capabilities of pre-trained latent diffusion models, StereoDiffusion offers a versatile and accessible solution for a wide range of applications, including virtual reality, 3D content creation, and computational photography. The ability to generate stereo pairs directly from 2D input represents a significant advancement in the field of 3D imaging and visualization.
While the paper identifies some potential areas for further research and improvement, the core ideas and techniques behind StereoDiffusion demonstrate the potential of repurposing generative AI models to tackle complex challenges in a training-free manner. As the field of machine learning continues to evolve, approaches like StereoDiffusion could pave the way for more efficient and accessible 3D content generation, unlocking new possibilities for how we interact with and experience the digital world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
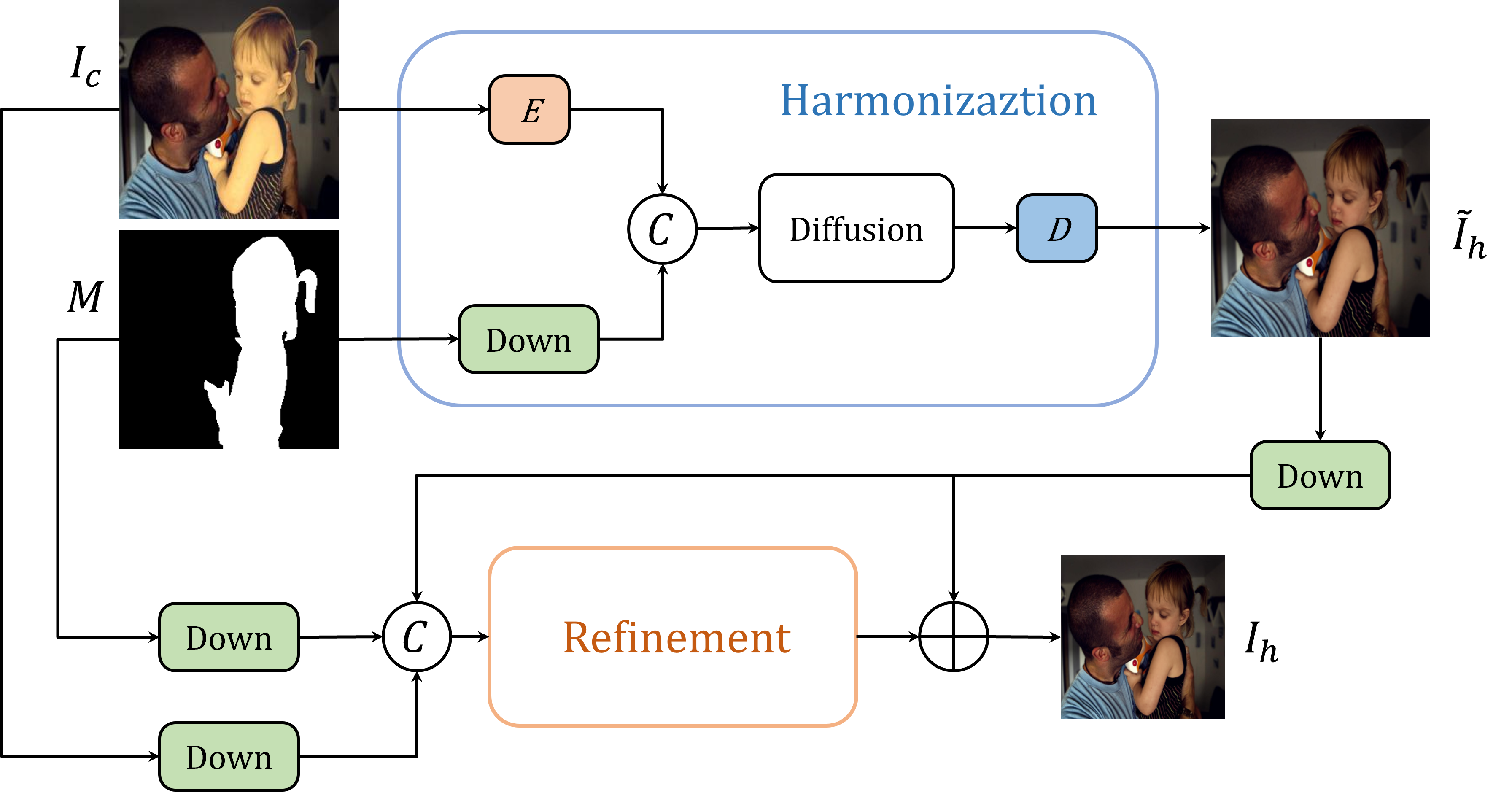
DiffHarmony: Latent Diffusion Model Meets Image Harmonization
Pengfei Zhou, Fangxiang Feng, Xiaojie Wang
0
0
Image harmonization, which involves adjusting the foreground of a composite image to attain a unified visual consistency with the background, can be conceptualized as an image-to-image translation task. Diffusion models have recently promoted the rapid development of image-to-image translation tasks . However, training diffusion models from scratch is computationally intensive. Fine-tuning pre-trained latent diffusion models entails dealing with the reconstruction error induced by the image compression autoencoder, making it unsuitable for image generation tasks that involve pixel-level evaluation metrics. To deal with these issues, in this paper, we first adapt a pre-trained latent diffusion model to the image harmonization task to generate the harmonious but potentially blurry initial images. Then we implement two strategies: utilizing higher-resolution images during inference and incorporating an additional refinement stage, to further enhance the clarity of the initially harmonized images. Extensive experiments on iHarmony4 datasets demonstrate the superiority of our proposed method. The code and model will be made publicly available at https://github.com/nicecv/DiffHarmony .
4/10/2024

ZeroSmooth: Training-free Diffuser Adaptation for High Frame Rate Video Generation
Shaoshu Yang, Yong Zhang, Xiaodong Cun, Ying Shan, Ran He
0
0
Video generation has made remarkable progress in recent years, especially since the advent of the video diffusion models. Many video generation models can produce plausible synthetic videos, e.g., Stable Video Diffusion (SVD). However, most video models can only generate low frame rate videos due to the limited GPU memory as well as the difficulty of modeling a large set of frames. The training videos are always uniformly sampled at a specified interval for temporal compression. Previous methods promote the frame rate by either training a video interpolation model in pixel space as a postprocessing stage or training an interpolation model in latent space for a specific base video model. In this paper, we propose a training-free video interpolation method for generative video diffusion models, which is generalizable to different models in a plug-and-play manner. We investigate the non-linearity in the feature space of video diffusion models and transform a video model into a self-cascaded video diffusion model with incorporating the designed hidden state correction modules. The self-cascaded architecture and the correction module are proposed to retain the temporal consistency between key frames and the interpolated frames. Extensive evaluations are preformed on multiple popular video models to demonstrate the effectiveness of the propose method, especially that our training-free method is even comparable to trained interpolation models supported by huge compute resources and large-scale datasets.
6/4/2024
Diffusion-based image inpainting with internal learning
Nicolas Cherel, Andr'es Almansa, Yann Gousseau, Alasdair Newson
0
0
Diffusion models are now the undisputed state-of-the-art for image generation and image restoration. However, they require large amounts of computational power for training and inference. In this paper, we propose lightweight diffusion models for image inpainting that can be trained on a single image, or a few images. We show that our approach competes with large state-of-the-art models in specific cases. We also show that training a model on a single image is particularly relevant for image acquisition modality that differ from the RGB images of standard learning databases. We show results in three different contexts: texture images, line drawing images, and materials BRDF, for which we achieve state-of-the-art results in terms of realism, with a computational load that is greatly reduced compared to concurrent methods.
6/7/2024
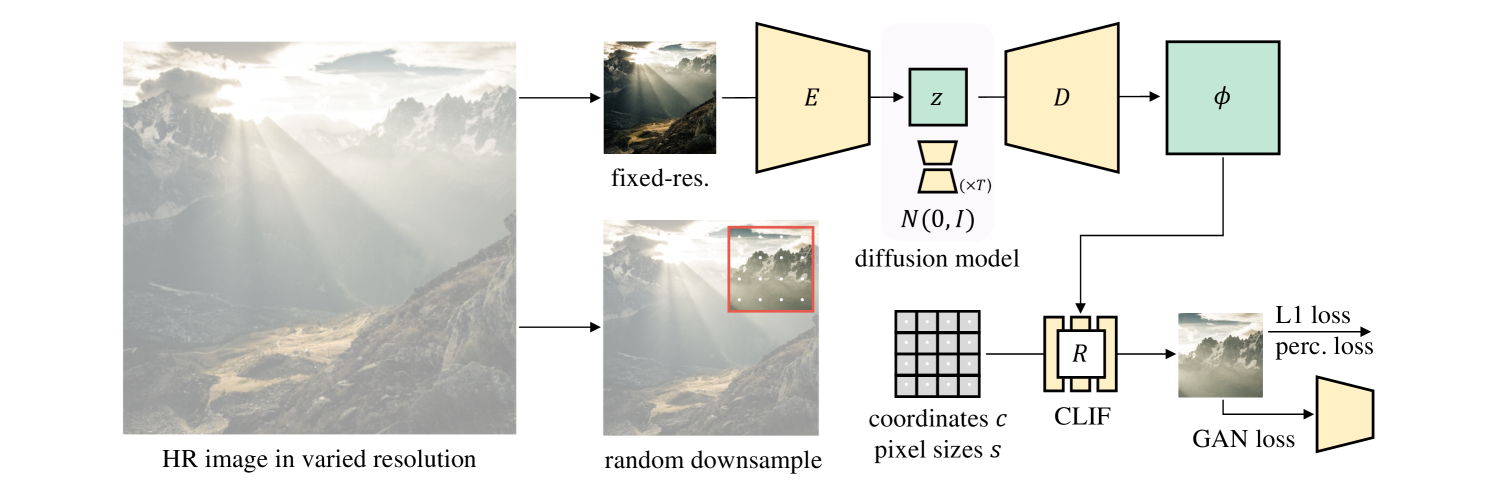
Image Neural Field Diffusion Models
Yinbo Chen, Oliver Wang, Richard Zhang, Eli Shechtman, Xiaolong Wang, Michael Gharbi
0
0
Diffusion models have shown an impressive ability to model complex data distributions, with several key advantages over GANs, such as stable training, better coverage of the training distribution's modes, and the ability to solve inverse problems without extra training. However, most diffusion models learn the distribution of fixed-resolution images. We propose to learn the distribution of continuous images by training diffusion models on image neural fields, which can be rendered at any resolution, and show its advantages over fixed-resolution models. To achieve this, a key challenge is to obtain a latent space that represents photorealistic image neural fields. We propose a simple and effective method, inspired by several recent techniques but with key changes to make the image neural fields photorealistic. Our method can be used to convert existing latent diffusion autoencoders into image neural field autoencoders. We show that image neural field diffusion models can be trained using mixed-resolution image datasets, outperform fixed-resolution diffusion models followed by super-resolution models, and can solve inverse problems with conditions applied at different scales efficiently.
6/12/2024