TravelPlanner: A Benchmark for Real-World Planning with Language Agents
2402.01622
0
0
💬
Abstract
Planning has been part of the core pursuit for artificial intelligence since its conception, but earlier AI agents mostly focused on constrained settings because many of the cognitive substrates necessary for human-level planning have been lacking. Recently, language agents powered by large language models (LLMs) have shown interesting capabilities such as tool use and reasoning. Are these language agents capable of planning in more complex settings that are out of the reach of prior AI agents? To advance this investigation, we propose TravelPlanner, a new planning benchmark that focuses on travel planning, a common real-world planning scenario. It provides a rich sandbox environment, various tools for accessing nearly four million data records, and 1,225 meticulously curated planning intents and reference plans. Comprehensive evaluations show that the current language agents are not yet capable of handling such complex planning tasks-even GPT-4 only achieves a success rate of 0.6%. Language agents struggle to stay on task, use the right tools to collect information, or keep track of multiple constraints. However, we note that the mere possibility for language agents to tackle such a complex problem is in itself non-trivial progress. TravelPlanner provides a challenging yet meaningful testbed for future language agents.
Create account to get full access
Overview
- Explores the capabilities of language agents powered by large language models (LLMs) in complex planning tasks
- Introduces a new planning benchmark called TravelPlanner that focuses on travel planning scenarios
- Finds that current language agents, including GPT-4, struggle to handle the complex planning tasks in TravelPlanner, achieving only a 0.6% success rate
Plain English Explanation
Artificial intelligence (AI) has long been interested in the ability to plan, as it is a crucial cognitive skill. However, earlier AI systems were mostly limited to simpler, constrained settings because they lacked many of the necessary cognitive abilities for human-level planning.
Recently, language agents powered by large language models (LLMs) have shown some interesting capabilities, such as tool use and reasoning. This raises the question of whether these language agents can handle more complex planning tasks that were out of reach for previous AI systems.
To investigate this, the researchers propose the TravelPlanner benchmark, which focuses on travel planning - a common real-world planning scenario. TravelPlanner provides a rich environment with various tools and a large dataset of planning information, as well as a set of carefully curated planning tasks.
The researchers' comprehensive evaluations found that even the powerful GPT-4 language model struggles to successfully complete the complex planning tasks in TravelPlanner, achieving only a 0.6% success rate. The language agents have difficulty staying on task, using the right tools to gather information, and keeping track of multiple constraints.
However, the mere fact that language agents can tackle such a complex problem is still a notable advancement in the field of AI. TravelPlanner provides a challenging yet meaningful testbed for future language agents to improve their planning capabilities.
Technical Explanation
The researchers propose TravelPlanner, a new planning benchmark that focuses on travel planning, a common real-world planning scenario. TravelPlanner provides a rich sandbox environment with various tools for accessing nearly four million data records, as well as 1,225 meticulously curated planning intents and reference plans.
Comprehensive evaluations were conducted to assess the capabilities of current language agents, including the powerful GPT-4 model, in handling the complex planning tasks within the TravelPlanner environment. The results showed that even GPT-4 only achieved a success rate of 0.6% on these tasks.
The researchers found that the language agents struggled with several key aspects of the planning process. They had difficulty staying focused on the task, using the right tools to collect the necessary information, and keeping track of multiple constraints simultaneously. These challenges highlight the limitations of current language agents in tackling complex, real-world planning problems.
However, the researchers note that the mere possibility for language agents to engage with such a complex problem is in itself a significant advancement in the field of AI. TravelPlanner provides a valuable testbed for future research and development of planning-aware language agents.
Critical Analysis
The researchers acknowledge several caveats and limitations in their study. They note that the TravelPlanner benchmark, while designed to be a challenging and realistic planning scenario, may not fully capture the nuances and complexities of actual human travel planning. Additionally, the current language agents, including GPT-4, are not specifically designed or trained for complex planning tasks, which may contribute to their poor performance.
Further research is needed to address these limitations and explore alternative approaches to improving the planning capabilities of language agents. For example, incorporating proactive planning strategies or developing specialized planning-aware techniques may help language agents navigate the challenges presented by the TravelPlanner benchmark more effectively.
It is also important to consider the broader implications of these findings. While the current language agents may not be capable of handling complex planning tasks, the continued advancement of natural language planning techniques could have significant real-world applications, such as assisting humans with travel planning or other complex decision-making processes.
Conclusion
The research presented in this paper highlights the limitations of current language agents, even powerful models like GPT-4, in handling complex planning tasks. The TravelPlanner benchmark provides a challenging and meaningful testbed for evaluating the planning capabilities of these language agents.
While the current language agents struggle to successfully complete the planning tasks in TravelPlanner, the mere fact that they can engage with such complex problems represents a notable advancement in the field of AI. The findings from this study underscore the need for further research and development to enhance the planning capabilities of language agents, which could have significant implications for various real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
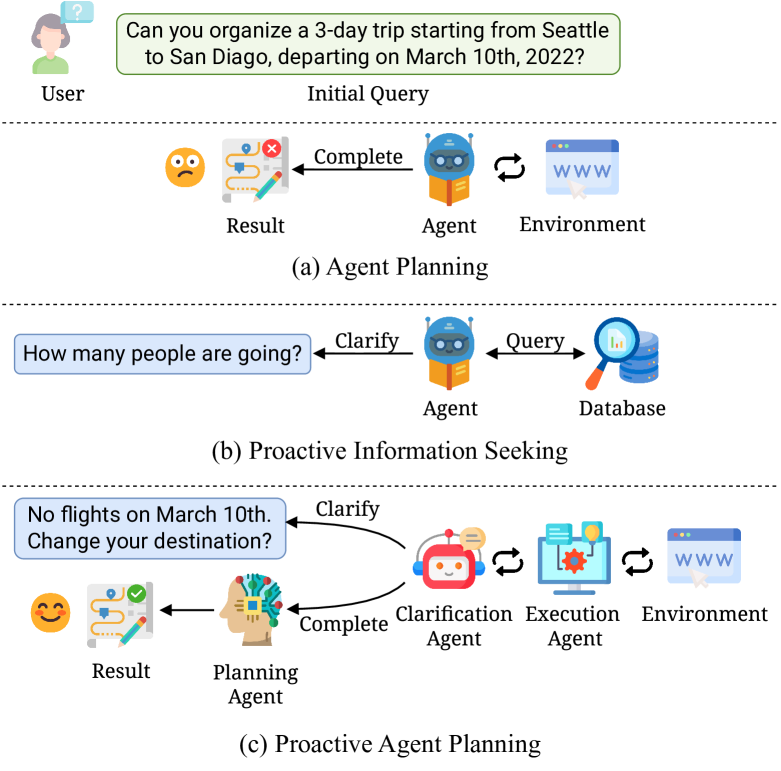
Ask-before-Plan: Proactive Language Agents for Real-World Planning
Xuan Zhang, Yang Deng, Zifeng Ren, See-Kiong Ng, Tat-Seng Chua
0
0
The evolution of large language models (LLMs) has enhanced the planning capabilities of language agents in diverse real-world scenarios. Despite these advancements, the potential of LLM-powered agents to comprehend ambiguous user instructions for reasoning and decision-making is still under exploration. In this work, we introduce a new task, Proactive Agent Planning, which requires language agents to predict clarification needs based on user-agent conversation and agent-environment interaction, invoke external tools to collect valid information, and generate a plan to fulfill the user's demands. To study this practical problem, we establish a new benchmark dataset, Ask-before-Plan. To tackle the deficiency of LLMs in proactive planning, we propose a novel multi-agent framework, Clarification-Execution-Planning (texttt{CEP}), which consists of three agents specialized in clarification, execution, and planning. We introduce the trajectory tuning scheme for the clarification agent and static execution agent, as well as the memory recollection mechanism for the dynamic execution agent. Extensive evaluations and comprehensive analyses conducted on the Ask-before-Plan dataset validate the effectiveness of our proposed framework.
6/19/2024

NATURAL PLAN: Benchmarking LLMs on Natural Language Planning
Huaixiu Steven Zheng, Swaroop Mishra, Hugh Zhang, Xinyun Chen, Minmin Chen, Azade Nova, Le Hou, Heng-Tze Cheng, Quoc V. Le, Ed H. Chi, Denny Zhou
0
0
We introduce NATURAL PLAN, a realistic planning benchmark in natural language containing 3 key tasks: Trip Planning, Meeting Planning, and Calendar Scheduling. We focus our evaluation on the planning capabilities of LLMs with full information on the task, by providing outputs from tools such as Google Flights, Google Maps, and Google Calendar as contexts to the models. This eliminates the need for a tool-use environment for evaluating LLMs on Planning. We observe that NATURAL PLAN is a challenging benchmark for state of the art models. For example, in Trip Planning, GPT-4 and Gemini 1.5 Pro could only achieve 31.1% and 34.8% solve rate respectively. We find that model performance drops drastically as the complexity of the problem increases: all models perform below 5% when there are 10 cities, highlighting a significant gap in planning in natural language for SoTA LLMs. We also conduct extensive ablation studies on NATURAL PLAN to further shed light on the (in)effectiveness of approaches such as self-correction, few-shot generalization, and in-context planning with long-contexts on improving LLM planning.
6/10/2024
💬
Large Language Models Can Plan Your Travels Rigorously with Formal Verification Tools
Yilun Hao, Yongchao Chen, Yang Zhang, Chuchu Fan
0
0
The recent advancements of Large Language Models (LLMs), with their abundant world knowledge and capabilities of tool-using and reasoning, fostered many LLM planning algorithms. However, LLMs have not shown to be able to accurately solve complex combinatorial optimization problems. In Xie et al. (2024), the authors proposed TravelPlanner, a U.S. domestic travel planning benchmark, and showed that LLMs themselves cannot make travel plans that satisfy user requirements with a best success rate of 0.6%. In this work, we propose a framework that enables LLMs to formally formulate and solve the travel planning problem as a satisfiability modulo theory (SMT) problem and use SMT solvers interactively and automatically solve the combinatorial search problem. The SMT solvers guarantee the satisfiable of input constraints and the LLMs can enable a language-based interaction with our framework. When the input constraints cannot be satisfiable, our LLM-based framework will interactively offer suggestions to users to modify their travel requirements via automatic reasoning using the SMT solvers. We evaluate our framework with TravelPlanner and achieve a success rate of 97%. We also create a separate dataset that contain international travel benchmarks and use both dataset to evaluate the effectiveness of our interactive planning framework when the initial user queries cannot be satisfied. Our framework could generate valid plans with an average success rate of 78.6% for our dataset and 85.0% for TravelPlanner according to diverse humans preferences.
4/22/2024
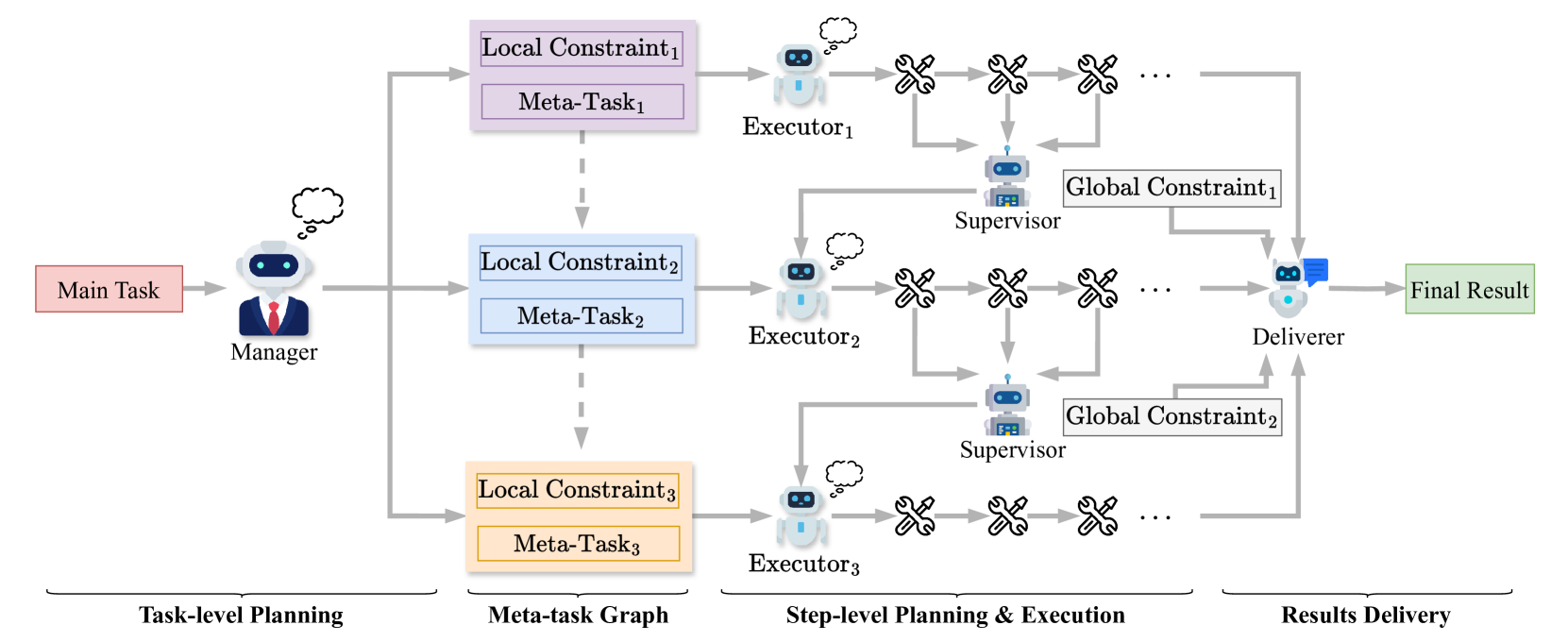
Meta-Task Planning for Language Agents
Cong Zhang, Derrick Goh Xin Deik, Dexun Li, Hao Zhang, Yong Liu
0
0
The rapid advancement of neural language models has sparked a new surge of intelligent agent research. Unlike traditional agents, large language model-based agents (LLM agents) have emerged as a promising paradigm for achieving artificial general intelligence (AGI) due to their superior reasoning and generalization capabilities. Effective planning is crucial for the success of LLM agents in real-world tasks, making it a highly pursued topic in the community. Current planning methods typically translate tasks into executable action sequences. However, determining a feasible or optimal sequence for complex tasks at fine granularity, which often requires compositing long chains of heterogeneous actions, remains challenging. This paper introduces Meta-Task Planning (MTP), a zero-shot methodology for collaborative LLM-based multi-agent systems that simplifies complex task planning by decomposing it into a hierarchy of subordinate tasks, or meta-tasks. Each meta-task is then mapped into executable actions. MTP was assessed on two rigorous benchmarks, TravelPlanner and API-Bank. Notably, MTP achieved an average $sim40%$ success rate on TravelPlanner, significantly higher than the state-of-the-art (SOTA) baseline ($2.92%$), and outperforming $LLM_{api}$-4 with ReAct on API-Bank by $sim14%$, showing the immense potential of integrating LLM with multi-agent systems.
5/31/2024