TRRG: Towards Truthful Radiology Report Generation With Cross-modal Disease Clue Enhanced Large Language Model

0

Sign in to get full access
Overview
- This paper proposes a model called TRRG (Towards Truthful Radiology Report Generation) that aims to generate more truthful and accurate radiology reports by incorporating cross-modal disease clues.
- The key idea is to leverage both image and text data to better understand the patient's condition and generate more reliable reports.
- The model uses a large language model as its foundation and enhances it with additional components to capture relevant disease information from the medical images.
Plain English Explanation
The paper discusses a new approach to generating radiology reports, which are the written summaries that doctors provide after analyzing medical images like X-rays or CT scans. Traditionally, these reports have been generated by language models that only look at the text data, without considering the visual information in the images.
The researchers behind this work wanted to create a model that could generate more truthful and accurate radiology reports by incorporating insights from both the text and the images. Their key insight was that the visual clues in the medical images can provide important information about the patient's medical condition that may not be fully captured in the textual data alone.
To achieve this, they developed a model called TRRG that builds on a large language model (a type of AI system trained on a vast amount of text data) but adds additional components to help the model better understand the relevant disease information from the images. The idea is that by considering both the text and visual data, the model can produce radiology reports that are more reflective of the patient's actual medical state.
Technical Explanation
The TRRG model is built upon a large language model, which is a powerful AI system trained on a massive amount of text data to generate human-like language. To enhance the language model's ability to understand and generate accurate radiology reports, the researchers incorporated several key components:
-
Cross-modal Disease Clue Encoding: This module takes the medical image and extracts relevant visual features related to different diseases. This helps the model better comprehend the patient's medical condition from the image data.
-
Cross-modal Fusion: The text-based features from the language model and the visual disease features are then combined to provide a more holistic representation of the patient's case.
-
Report Generation: The fused text-image features are then used to generate the final radiology report, with the goal of making it more truthful and accurate compared to reports generated by language models alone.
The researchers evaluated TRRG on several radiology report benchmarks and found that it outperformed existing language-only models in terms of generating more truthful and medically relevant reports. This suggests that the cross-modal approach of leveraging both textual and visual information can lead to substantial improvements in the quality and reliability of automatically generated radiology reports.
Critical Analysis
The paper presents a compelling approach to enhancing radiology report generation by incorporating cross-modal disease clues. The key strength of this work is the intuition that visual information from medical images can provide valuable insights that complement the textual data, leading to more truthful and accurate reports.
However, the paper does not delve deeply into the potential limitations or caveats of this approach. For example, it would be helpful to understand how the model performs on edge cases or rare medical conditions where the visual disease clues may be more subtle or difficult to extract. Additionally, the paper does not discuss the potential biases or errors that could be introduced by the disease feature extraction module, and how these might impact the final report generation.
Further research could also explore the interpretability of the TRRG model, as understanding the reasoning behind the generated reports could be crucial for building trust and adoption in clinical settings. Lastly, a more comprehensive evaluation across a broader range of medical conditions and report types would help validate the generalizability of the proposed approach.
Conclusion
The TRRG model presented in this paper represents an important step towards generating more truthful and accurate radiology reports by leveraging both textual and visual information. The key insight of incorporating cross-modal disease clues from medical images is a promising direction that has the potential to significantly improve the reliability of automated report generation, which could ultimately lead to better patient care and more informed clinical decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TRRG: Towards Truthful Radiology Report Generation With Cross-modal Disease Clue Enhanced Large Language Model
Yuhao Wang, Chao Hao, Yawen Cui, Xinqi Su, Weicheng Xie, Tao Tan, Zitong Yu
The vision-language modeling capability of multi-modal large language models has attracted wide attention from the community. However, in medical domain, radiology report generation using vision-language models still faces significant challenges due to the imbalanced data distribution caused by numerous negated descriptions in radiology reports and issues such as rough alignment between radiology reports and radiography. In this paper, we propose a truthful radiology report generation framework, namely TRRG, based on stage-wise training for cross-modal disease clue injection into large language models. In pre-training stage, During the pre-training phase, contrastive learning is employed to enhance the ability of visual encoder to perceive fine-grained disease details. In fine-tuning stage, the clue injection module we proposed significantly enhances the disease-oriented perception capability of the large language model by effectively incorporating the robust zero-shot disease perception. Finally, through the cross-modal clue interaction module, our model effectively achieves the multi-granular interaction of visual embeddings and an arbitrary number of disease clue embeddings. This significantly enhances the report generation capability and clinical effectiveness of multi-modal large language models in the field of radiology reportgeneration. Experimental results demonstrate that our proposed pre-training and fine-tuning framework achieves state-of-the-art performance in radiology report generation on datasets such as IU-Xray and MIMIC-CXR. Further analysis indicates that our proposed method can effectively enhance the model to perceive diseases and improve its clinical effectiveness.
Read more8/23/2024

0
X-ray Made Simple: Radiology Report Generation and Evaluation with Layman's Terms
Kun Zhao, Chenghao Xiao, Chen Tang, Bohao Yang, Kai Ye, Noura Al Moubayed, Liang Zhan, Chenghua Lin
Radiology Report Generation (RRG) has achieved significant progress with the advancements of multimodal generative models. However, the evaluation in the domain suffers from a lack of fair and robust metrics. We reveal that, high performance on RRG with existing lexical-based metrics (e.g. BLEU) might be more of a mirage - a model can get a high BLEU only by learning the template of reports. This has become an urgent problem for RRG due to the highly patternized nature of these reports. In this work, we un-intuitively approach this problem by proposing the Layman's RRG framework, a layman's terms-based dataset, evaluation and training framework that systematically improves RRG with day-to-day language. We first contribute the translated Layman's terms dataset. Building upon the dataset, we then propose a semantics-based evaluation method, which is proved to mitigate the inflated numbers of BLEU and provides fairer evaluation. Last, we show that training on the layman's terms dataset encourages models to focus on the semantics of the reports, as opposed to overfitting to learning the report templates. We reveal a promising scaling law between the number of training examples and semantics gain provided by our dataset, compared to the inverse pattern brought by the original formats. Our code is available at url{https://github.com/hegehongcha/LaymanRRG}.
Read more7/2/2024
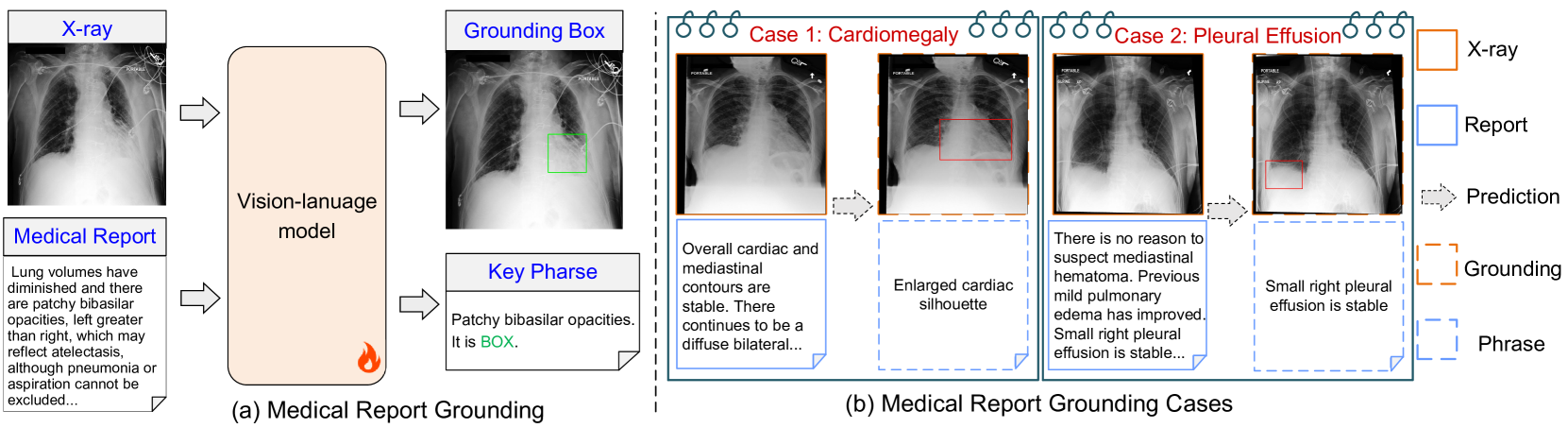
0
MedRG: Medical Report Grounding with Multi-modal Large Language Model
Ke Zou, Yang Bai, Zhihao Chen, Yang Zhou, Yidi Chen, Kai Ren, Meng Wang, Xuedong Yuan, Xiaojing Shen, Huazhu Fu
Medical Report Grounding is pivotal in identifying the most relevant regions in medical images based on a given phrase query, a critical aspect in medical image analysis and radiological diagnosis. However, prevailing visual grounding approaches necessitate the manual extraction of key phrases from medical reports, imposing substantial burdens on both system efficiency and physicians. In this paper, we introduce a novel framework, Medical Report Grounding (MedRG), an end-to-end solution for utilizing a multi-modal Large Language Model to predict key phrase by incorporating a unique token, BOX, into the vocabulary to serve as an embedding for unlocking detection capabilities. Subsequently, the vision encoder-decoder jointly decodes the hidden embedding and the input medical image, generating the corresponding grounding box. The experimental results validate the effectiveness of MedRG, surpassing the performance of the existing state-of-the-art medical phrase grounding methods. This study represents a pioneering exploration of the medical report grounding task, marking the first-ever endeavor in this domain.
Read more4/11/2024

0
A Systematic Review of Deep Learning-based Research on Radiology Report Generation
Chang Liu, Yuanhe Tian, Yan Song
Radiology report generation (RRG) aims to automatically generate free-text descriptions from clinical radiographs, e.g., chest X-Ray images. RRG plays an essential role in promoting clinical automation and presents significant help to provide practical assistance for inexperienced doctors and alleviate radiologists' workloads. Therefore, consider these meaningful potentials, research on RRG is experiencing explosive growth in the past half-decade, especially with the rapid development of deep learning approaches. Existing studies perform RRG from the perspective of enhancing different modalities, provide insights on optimizing the report generation process with elaborated features from both visual and textual information, and further facilitate RRG with the cross-modal interactions among them. In this paper, we present a comprehensive review of deep learning-based RRG from various perspectives. Specifically, we firstly cover pivotal RRG approaches based on the task-specific features of radiographs, reports, and the cross-modal relations between them, and then illustrate the benchmark datasets conventionally used for this task with evaluation metrics, subsequently analyze the performance of different approaches and finally offer our summary on the challenges and the trends in future directions. Overall, the goal of this paper is to serve as a tool for understanding existing literature and inspiring potential valuable research in the field of RRG.
Read more4/26/2024