Trusted Unified Feature-Neighborhood Dynamics for Multi-View Classification

0
Sign in to get full access
Overview
- Presents a novel approach called "Trusted Unified Feature-Neighborhood Dynamics for Multi-View Classification"
- Aims to address challenges in multi-view classification tasks, where data is collected from multiple sources or modalities
- Introduces a framework that combines feature learning and neighborhood dynamics to improve classification performance
Plain English Explanation
Multi-view classification is a type of machine learning problem where data is collected from different sources or modalities, such as images, text, and sensor data. This can be challenging because the different views of the data may contain conflicting or complementary information, making it difficult to build an accurate classification model.
The researchers behind this paper have developed a new approach called "Trusted Unified Feature-Neighborhood Dynamics for Multi-View Classification" to address these challenges. The key idea is to combine feature learning and neighborhood dynamics in a way that allows the model to effectively leverage the information from multiple views of the data.
The feature learning component learns a set of features that are common across the different views, while the neighborhood dynamics component analyzes the relationships between data points in the feature space. By combining these two elements, the model can identify the most relevant and trustworthy features for classification, even when the views of the data may be conflicting or incomplete.
The researchers have tested their approach on several real-world datasets and found that it outperforms other state-of-the-art multi-view classification methods. This suggests that their framework could be a valuable tool for a wide range of applications, such as medical diagnosis, image recognition, and text analysis, where data is collected from multiple sources.
Technical Explanation
The paper introduces a novel framework called "Trusted Unified Feature-Neighborhood Dynamics for Multi-View Classification" (TUFN) that combines feature learning and neighborhood dynamics to address the challenges of multi-view classification.
The feature learning component of TUFN learns a set of shared features across the different views of the data, which helps to capture the underlying patterns and relationships that are common to all the views. This is done by optimizing a joint objective function that encourages the features to be both discriminative and robust to noise or missing data.
The neighborhood dynamics component of TUFN analyzes the relationships between data points in the feature space, using techniques like graph construction and label propagation. This allows the model to identify the most trustworthy features and data points for classification, even when the different views of the data may be conflicting or incomplete.
The researchers have evaluated TUFN on several benchmark multi-view datasets, and have found that it outperforms other state-of-the-art multi-view classification methods in terms of classification accuracy and robustness to noise or missing data. The results suggest that the combination of feature learning and neighborhood dynamics can be a powerful approach for multi-view classification tasks.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the TUFN framework, with experiments on several real-world datasets and comparisons to other state-of-the-art methods. The researchers have also discussed some potential limitations and areas for further research, such as extending the framework to handle more complex data structures or exploring the trade-offs between feature learning and neighborhood dynamics.
One potential area of concern is the computational complexity of the TUFN framework, which may be higher than some other multi-view classification methods due to the additional steps involved in feature learning and neighborhood dynamics. This could limit the scalability of the approach, particularly for very large or high-dimensional datasets.
Additionally, the paper does not provide much insight into the interpretability of the TUFN framework, i.e., how the learned features and neighborhood dynamics can be used to understand the underlying relationships and patterns in the data. This could be an important consideration for certain applications, where explainability and transparency are crucial.
Overall, the TUFN framework presented in this paper appears to be a promising approach for multi-view classification, with strong empirical performance and a solid theoretical foundation. However, as with any research, there are still opportunities for further exploration and refinement to address the potential limitations and expand the applicability of the method.
Conclusion
The "Trusted Unified Feature-Neighborhood Dynamics for Multi-View Classification" (TUFN) framework introduced in this paper represents a novel and effective approach for addressing the challenges of multi-view classification. By combining feature learning and neighborhood dynamics, the TUFN framework is able to leverage the complementary information from multiple views of the data to achieve superior classification performance, even in the presence of noise or missing data.
The strong empirical results demonstrated in the paper suggest that the TUFN framework could be a valuable tool for a wide range of real-world applications, from medical diagnosis to image recognition and text analysis. As the volume and complexity of multi-modal data continue to grow, approaches like TUFN that can effectively integrate and make sense of these diverse data sources will become increasingly important.
While the paper has identified some potential areas for further research, such as improving the computational efficiency and interpretability of the framework, the core ideas and insights presented in this work represent a significant contribution to the field of multi-view machine learning. By continuing to build on these advancements, researchers and practitioners can unlock new possibilities for leveraging the wealth of data available in today's connected world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Trusted Unified Feature-Neighborhood Dynamics for Multi-View Classification
Haojian Huang, Chuanyu Qin, Zhe Liu, Kaijing Ma, Jin Chen, Han Fang, Chao Ban, Hao Sun, Zhongjiang He
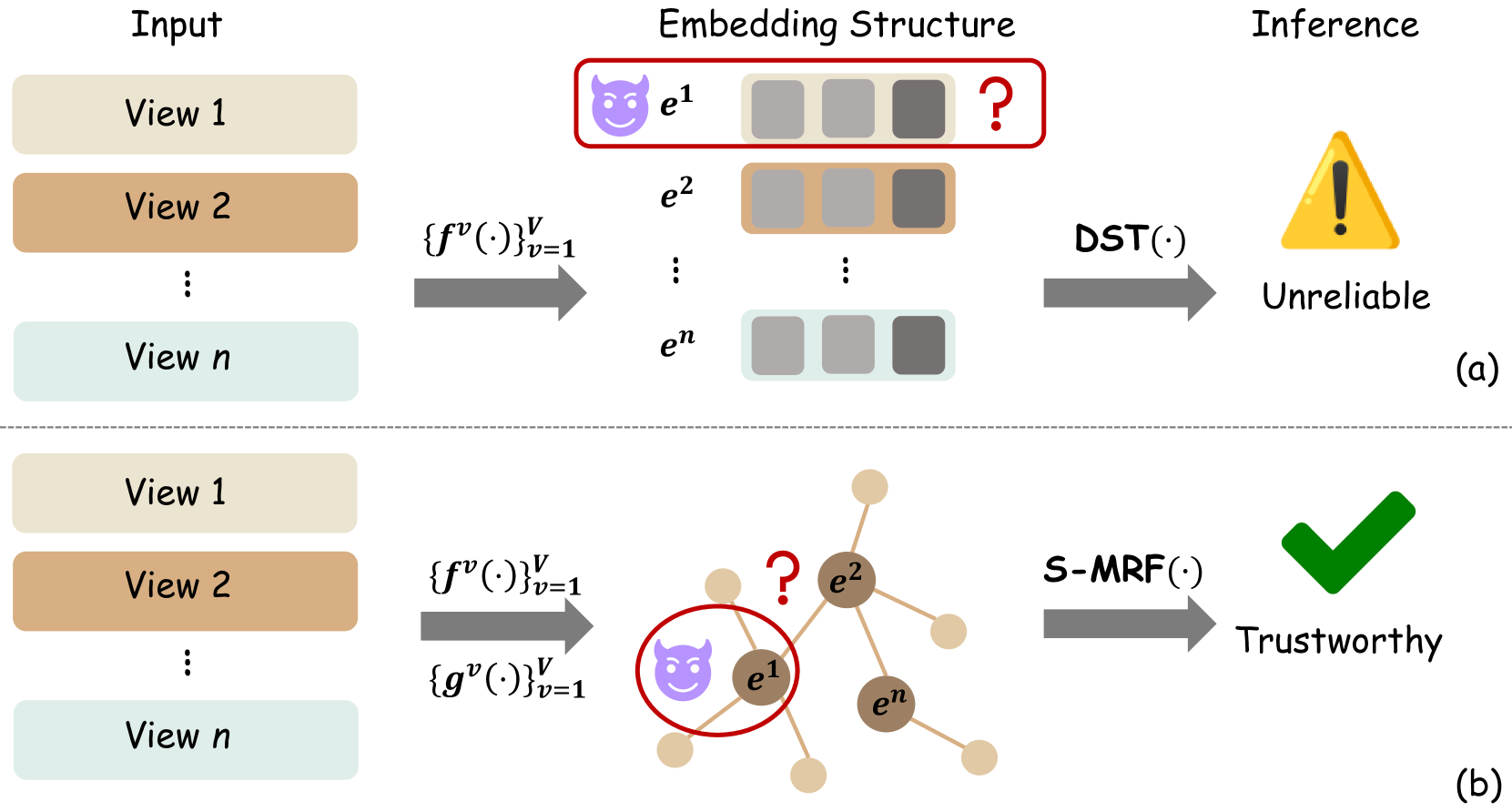
Multi-view classification (MVC) faces inherent challenges due to domain gaps and inconsistencies across different views, often resulting in uncertainties during the fusion process. While Evidential Deep Learning (EDL) has been effective in addressing view uncertainty, existing methods predominantly rely on the Dempster-Shafer combination rule, which is sensitive to conflicting evidence and often neglects the critical role of neighborhood structures within multi-view data. To address these limitations, we propose a Trusted Unified Feature-NEighborhood Dynamics (TUNED) model for robust MVC. This method effectively integrates local and global feature-neighborhood (F-N) structures for robust decision-making. Specifically, we begin by extracting local F-N structures within each view. To further mitigate potential uncertainties and conflicts in multi-view fusion, we employ a selective Markov random field that adaptively manages cross-view neighborhood dependencies. Additionally, we employ a shared parameterized evidence extractor that learns global consensus conditioned on local F-N structures, thereby enhancing the global integration of multi-view features. Experiments on benchmark datasets show that our method improves accuracy and robustness over existing approaches, particularly in scenarios with high uncertainty and conflicting views. The code will be made available at https://github.com/JethroJames/TUNED.
Read more9/4/2024

0
Evidential Deep Partial Multi-View Classification With Discount Fusion
Haojian Huang, Zhe Liu, Sukumar Letchmunan, Muhammet Deveci, Mingwei Lin, Weizhong Wang
Incomplete multi-view data classification poses significant challenges due to the common issue of missing views in real-world scenarios. Despite advancements, existing methods often fail to provide reliable predictions, largely due to the uncertainty of missing views and the inconsistent quality of imputed data. To tackle these problems, we propose a novel framework called Evidential Deep Partial Multi-View Classification (EDP-MVC). Initially, we use K-means imputation to address missing views, creating a complete set of multi-view data. However, the potential conflicts and uncertainties within this imputed data can affect the reliability of downstream inferences. To manage this, we introduce a Conflict-Aware Evidential Fusion Network (CAEFN), which dynamically adjusts based on the reliability of the evidence, ensuring trustworthy discount fusion and producing reliable inference outcomes. Comprehensive experiments on various benchmark datasets reveal EDP-MVC not only matches but often surpasses the performance of state-of-the-art methods.
Read more9/2/2024

0
Towards Robust Uncertainty-Aware Incomplete Multi-View Classification
Mulin Chen, Haojian Huang, Qiang Li
Handling incomplete data in multi-view classification is challenging, especially when traditional imputation methods introduce biases that compromise uncertainty estimation. Existing Evidential Deep Learning (EDL) based approaches attempt to address these issues, but they often struggle with conflicting evidence due to the limitations of the Dempster-Shafer combination rule, leading to unreliable decisions. To address these challenges, we propose the Alternating Progressive Learning Network (APLN), specifically designed to enhance EDL-based methods in incomplete MVC scenarios. Our approach mitigates bias from corrupted observed data by first applying coarse imputation, followed by mapping the data to a latent space. In this latent space, we progressively learn an evidence distribution aligned with the target domain, incorporating uncertainty considerations through EDL. Additionally, we introduce a conflict-aware Dempster-Shafer combination rule (DSCR) to better handle conflicting evidence. By sampling from the learned distribution, we optimize the latent representations of missing views, reducing bias and enhancing decision-making robustness. Extensive experiments demonstrate that APLN, combined with DSCR, significantly outperforms traditional methods, particularly in environments characterized by high uncertainty and conflicting evidence, establishing it as a promising solution for incomplete multi-view classification.
Read more9/11/2024

0
Federated Incomplete Multi-View Clustering with Heterogeneous Graph Neural Networks
Xueming Yan, Ziqi Wang, Yaochu Jin
Federated multi-view clustering offers the potential to develop a global clustering model using data distributed across multiple devices. However, current methods face challenges due to the absence of label information and the paramount importance of data privacy. A significant issue is the feature heterogeneity across multi-view data, which complicates the effective mining of complementary clustering information. Additionally, the inherent incompleteness of multi-view data in a distributed setting can further complicate the clustering process. To address these challenges, we introduce a federated incomplete multi-view clustering framework with heterogeneous graph neural networks (FIM-GNNs). In the proposed FIM-GNNs, autoencoders built on heterogeneous graph neural network models are employed for feature extraction of multi-view data at each client site. At the server level, heterogeneous features from overlapping samples of each client are aggregated into a global feature representation. Global pseudo-labels are generated at the server to enhance the handling of incomplete view data, where these labels serve as a guide for integrating and refining the clustering process across different data views. Comprehensive experiments have been conducted on public benchmark datasets to verify the performance of the proposed FIM-GNNs in comparison with state-of-the-art algorithms.
Read more6/14/2024