TSDiT: Traffic Scene Diffusion Models With Transformers
2405.02289
0
0
🔄
Abstract
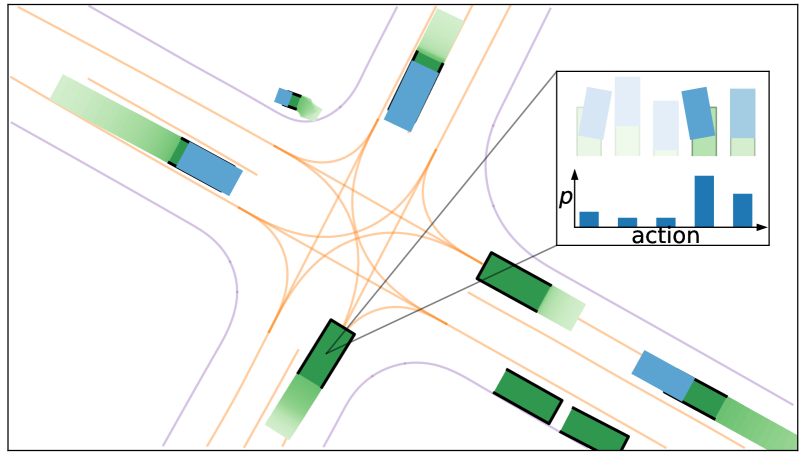
In this paper, we introduce a novel approach to trajectory generation for autonomous driving, combining the strengths of Diffusion models and Transformers. First, we use the historical trajectory data for efficient preprocessing and generate action latent using a diffusion model with DiT(Diffusion with Transformers) Blocks to increase scene diversity and stochasticity of agent actions. Then, we combine action latent, historical trajectories and HD Map features and put them into different transformer blocks. Finally, we use a trajectory decoder to generate future trajectories of agents in the traffic scene. The method exhibits superior performance in generating smooth turning trajectories, enhancing the model's capability to fit complex steering patterns. The experimental results demonstrate the effectiveness of our method in producing realistic and diverse trajectories, showcasing its potential for application in autonomous vehicle navigation systems.
Create account to get full access
Overview
- The paper introduces a novel approach to trajectory generation for autonomous driving, combining Diffusion models and Transformers.
- The method uses historical trajectory data to generate action latent using a diffusion model with DiT (Diffusion with Transformers) Blocks, which increases scene diversity and stochasticity of agent actions.
- The action latent, historical trajectories, and HD Map features are then combined and fed into different transformer blocks.
- Finally, a trajectory decoder is used to generate future trajectories of agents in the traffic scene.
- The proposed method exhibits superior performance in generating smooth turning trajectories, enhancing the model's capability to fit complex steering patterns.
Plain English Explanation
In this research, the authors have developed a new way to generate trajectories for autonomous vehicles. They combine two powerful machine learning techniques: Diffusion models and Transformers.
First, the model uses historical data on how vehicles have moved in the past to create a sort of "blueprint" for future movements. This blueprint, called "action latent," is generated using a diffusion model with special "DiT" (Diffusion with Transformers) Blocks, which help the model create a diverse range of possible actions and make the vehicle's movements more realistic and unpredictable.
Next, the model takes this action latent, along with information about the vehicle's past movements and features of the surrounding environment (like high-definition maps), and feeds it into different "transformer" modules. Transformers are a type of machine learning model that can understand complex relationships in data.
Finally, the model uses a "trajectory decoder" to generate the actual future paths the vehicle might take. The key advantage of this approach is that it can produce smooth, realistic turns and other complex steering patterns that are crucial for safe and natural autonomous driving.
Technical Explanation
The paper presents a novel approach to trajectory generation for autonomous driving that leverages the strengths of Diffusion models and Transformers.
The method begins by using historical trajectory data for efficient preprocessing and generating an "action latent" using a diffusion model with DiT (Diffusion with Transformers) Blocks. This helps increase the scene diversity and stochasticity of the agent's actions, allowing for more realistic and varied trajectories.
The generated action latent is then combined with the historical trajectories and HD Map features, and this combined input is fed into different transformer blocks. The transformers are able to model the complex relationships between these various inputs, which are crucial for generating realistic and smooth turning trajectories.
Finally, a trajectory decoder is used to generate the future trajectories of the agents in the traffic scene. The experimental results demonstrate the effectiveness of this approach, showing that it can produce diverse and realistic trajectories that outperform other state-of-the-art methods, particularly in its ability to capture complex steering patterns.
Critical Analysis
The paper presents a well-designed and thorough approach to trajectory generation for autonomous driving. The combination of diffusion models and transformers is a novel and promising direction, as it allows the model to capture both the stochasticity of agent actions and the complex spatial and temporal relationships in the traffic scene.
However, the paper does not address some potential limitations or areas for further research. For example, it would be interesting to see how the model performs in more challenging or edge cases, such as highly congested traffic or unexpected events. Additionally, the paper does not discuss the computational complexity or real-time performance of the proposed method, which would be crucial for deployment in real-world autonomous driving systems.
Furthermore, the paper could have provided more insight into the inner workings of the DiT Blocks and the specific transformer architectures used, as these design choices likely play a key role in the model's performance. A deeper analysis of the learned representations and their interpretability would also be valuable for understanding the model's strengths and limitations.
Overall, the research presented in this paper is a significant contribution to the field of autonomous driving, and the proposed Diffusion-Transformer approach shows great promise. However, further investigation and validation of the method's robustness and real-world applicability would be beneficial for its wider adoption and impact.
Conclusion
This paper introduces a novel approach to trajectory generation for autonomous driving that combines the strengths of diffusion models and transformers. By using historical trajectory data to generate action latent with a diffusion model, and then feeding this latent along with other relevant features into transformer blocks, the method is able to produce diverse and realistic trajectories that excel at capturing complex steering patterns.
The experimental results demonstrate the effectiveness of this Diffusion-Transformer approach, and its potential for application in autonomous vehicle navigation systems. While the paper leaves room for further research into the method's limitations and real-world performance, it represents an important step forward in the development of robust and reliable trajectory generation for self-driving cars.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

WcDT: World-centric Diffusion Transformer for Traffic Scene Generation
Chen Yang, Aaron Xuxiang Tian, Dong Chen, Tianyu Shi, Arsalan Heydarian
0
0
In this paper, we introduce a novel approach for autonomous driving trajectory generation by harnessing the complementary strengths of diffusion probabilistic models (a.k.a., diffusion models) and transformers. Our proposed framework, termed the World-Centric Diffusion Transformer (WcDT), optimizes the entire trajectory generation process, from feature extraction to model inference. To enhance the scene diversity and stochasticity, the historical trajectory data is first preprocessed and encoded into latent space using Denoising Diffusion Probabilistic Models (DDPM) enhanced with Diffusion with Transformer (DiT) blocks. Then, the latent features, historical trajectories, HD map features, and historical traffic signal information are fused with various transformer-based encoders. The encoded traffic scenes are then decoded by a trajectory decoder to generate multimodal future trajectories. Comprehensive experimental results show that the proposed approach exhibits superior performance in generating both realistic and diverse trajectories, showing its potential for integration into automatic driving simulation systems.
4/3/2024
Trajeglish: Traffic Modeling as Next-Token Prediction
Jonah Philion, Xue Bin Peng, Sanja Fidler
0
0
A longstanding challenge for self-driving development is simulating dynamic driving scenarios seeded from recorded driving logs. In pursuit of this functionality, we apply tools from discrete sequence modeling to model how vehicles, pedestrians and cyclists interact in driving scenarios. Using a simple data-driven tokenization scheme, we discretize trajectories to centimeter-level resolution using a small vocabulary. We then model the multi-agent sequence of discrete motion tokens with a GPT-like encoder-decoder that is autoregressive in time and takes into account intra-timestep interaction between agents. Scenarios sampled from our model exhibit state-of-the-art realism; our model tops the Waymo Sim Agents Benchmark, surpassing prior work along the realism meta metric by 3.3% and along the interaction metric by 9.9%. We ablate our modeling choices in full autonomy and partial autonomy settings, and show that the representations learned by our model can quickly be adapted to improve performance on nuScenes. We additionally evaluate the scalability of our model with respect to parameter count and dataset size, and use density estimates from our model to quantify the saliency of context length and intra-timestep interaction for the traffic modeling task.
4/16/2024

Versatile Scene-Consistent Traffic Scenario Generation as Optimization with Diffusion
Zhiyu Huang, Zixu Zhang, Ameya Vaidya, Yuxiao Chen, Chen Lv, Jaime Fern'andez Fisac
0
0
Generating realistic and controllable agent behaviors in traffic simulation is crucial for the development of autonomous vehicles. This problem is often formulated as imitation learning (IL) from real-world driving data by either directly predicting future trajectories or inferring cost functions with inverse optimal control. In this paper, we draw a conceptual connection between IL and diffusion-based generative modeling and introduce a novel framework Versatile Behavior Diffusion (VBD) to simulate interactive scenarios with multiple traffic participants. Our model not only generates scene-consistent multi-agent interactions but also enables scenario editing through multi-step guidance and refinement. Experimental evaluations show that VBD achieves state-of-the-art performance on the Waymo Sim Agents benchmark. In addition, we illustrate the versatility of our model by adapting it to various applications. VBD is capable of producing scenarios conditioning on priors, integrating with model-based optimization, sampling multi-modal scene-consistent scenarios by fusing marginal predictions, and generating safety-critical scenarios when combined with a game-theoretic solver.
4/4/2024
👀
DiffiT: Diffusion Vision Transformers for Image Generation
Ali Hatamizadeh, Jiaming Song, Guilin Liu, Jan Kautz, Arash Vahdat
0
0
Diffusion models with their powerful expressivity and high sample quality have achieved State-Of-The-Art (SOTA) performance in the generative domain. The pioneering Vision Transformer (ViT) has also demonstrated strong modeling capabilities and scalability, especially for recognition tasks. In this paper, we study the effectiveness of ViTs in diffusion-based generative learning and propose a new model denoted as Diffusion Vision Transformers (DiffiT). Specifically, we propose a methodology for finegrained control of the denoising process and introduce the Time-dependant Multihead Self Attention (TMSA) mechanism. DiffiT is surprisingly effective in generating high-fidelity images with significantly better parameter efficiency. We also propose latent and image space DiffiT models and show SOTA performance on a variety of class-conditional and unconditional synthesis tasks at different resolutions. The Latent DiffiT model achieves a new SOTA FID score of 1.73 on ImageNet-256 dataset while having 19.85%, 16.88% less parameters than other Transformer-based diffusion models such as MDT and DiT, respectively. Code: https://github.com/NVlabs/DiffiT
4/3/2024