Two Hands Are Better Than One: Resolving Hand to Hand Intersections via Occupancy Networks
2404.05414
0
0

Abstract
3D hand pose estimation from images has seen considerable interest from the literature, with new methods improving overall 3D accuracy. One current challenge is to address hand-to-hand interaction where self-occlusions and finger articulation pose a significant problem to estimation. Little work has applied physical constraints that minimize the hand intersections that occur as a result of noisy estimation. This work addresses the intersection of hands by exploiting an occupancy network that represents the hand's volume as a continuous manifold. This allows us to model the probability distribution of points being inside a hand. We designed an intersection loss function to minimize the likelihood of hand-to-point intersections. Moreover, we propose a new hand mesh parameterization that is superior to the commonly used MANO model in many respects including lower mesh complexity, underlying 3D skeleton extraction, watertightness, etc. On the benchmark InterHand2.6M dataset, the models trained using our intersection loss achieve better results than the state-of-the-art by significantly decreasing the number of hand intersections while lowering the mean per-joint positional error. Additionally, we demonstrate superior performance for 3D hand uplift on Re:InterHand and SMILE datasets and show reduced hand-to-hand intersections for complex domains such as sign-language pose estimation.
Create account to get full access
Overview
- This paper presents a novel approach to resolving hand-to-hand intersections in 3D hand pose estimation using an occupancy network.
- The authors develop a deep learning model that can accurately distinguish between different hands, even when they overlap or intersect in the input data.
- This addresses a common challenge in hand pose estimation, where accurately identifying individual hands is crucial for downstream applications like human-computer interaction and augmented reality.
Plain English Explanation
The paper focuses on a problem that often arises when trying to track the 3D positions of a person's hands - what happens when the hands overlap or intersect with each other in the camera's view? This can make it very difficult to accurately identify which hand belongs to which person.
The researchers developed a deep learning model called an occupancy network that is able to solve this problem. The occupancy network can look at an image or 3D scan of overlapping hands and accurately determine which parts belong to which hand. This allows for much more precise 3D hand pose estimation, which is important for things like virtual reality, sign language recognition, and controlling computers with hand gestures.
The key innovation is that the occupancy network learns an internal 3D representation of the hands and uses that to segment the hands, even when they are touching or crossing over each other. This is a significant advance over previous methods that struggled with these types of hand intersections.
Technical Explanation
The paper introduces an occupancy network architecture that can accurately resolve hand-to-hand intersections in 3D hand pose estimation. The occupancy network takes in a 3D point cloud or depth image as input and outputs a 3D occupancy grid, where each voxel is classified as belonging to the left hand, right hand, or neither.
The authors train the occupancy network using a combination of ground truth hand segmentation data and synthetic data generated by their own hand interaction simulation. This allows the model to learn robust representations of how hands can occlude and intersect with each other in 3D space.
Once the occupancy network is trained, it can be used to pre-process 3D hand input data before feeding it into a standard 3D hand pose estimation pipeline. By first separating the left and right hands, the downstream pose estimation becomes much more accurate and reliable, even in complex hand interaction scenarios.
The paper demonstrates the effectiveness of this approach through extensive experiments on public benchmarks, showing significant performance improvements over previous state-of-the-art methods, especially in cases with hand intersections. The authors also show how the occupancy network can be used to enable new applications like improved hand-based virtual interaction.
Critical Analysis
The paper presents a compelling solution to an important problem in 3D hand pose estimation, and the occupancy network approach seems to be a significant technical advance in this area. However, the authors do acknowledge some limitations in their work.
For example, the occupancy network is trained on synthetic data in addition to real-world examples, and it's not clear how well the model would generalize to truly novel hand interaction scenarios that were not represented in the training data. Additionally, the computational cost of running the occupancy network pre-processing step may limit the real-time performance of the overall system in some applications.
The paper also does not provide much analysis of potential failure cases or edge cases where the occupancy network may struggle. Further research could explore the robustness of the approach in more diverse or challenging hand interaction scenarios.
Overall, though, this work represents an impressive advance in a important computer vision problem, and the occupancy network concept could potentially be applied to other domains beyond just 3D hand pose estimation. Continued research in this direction seems promising for improving human-computer interaction and related applications.
Conclusion
This paper introduces a novel occupancy network architecture that can effectively resolve hand-to-hand intersections in 3D hand pose estimation. By learning an internal 3D representation of hands and how they can occlude each other, the occupancy network is able to accurately segment left and right hands even when they overlap in the input data.
The authors demonstrate significant performance improvements over previous state-of-the-art methods, especially in challenging hand interaction scenarios. This advance has important implications for applications like virtual/augmented reality, sign language recognition, and general hand-based human-computer interaction, where reliable 3D hand tracking is crucial.
While the approach has some limitations that warrant further research, this work represents an important step forward in addressing a longstanding challenge in computer vision and robotics. The occupancy network concept could potentially see broader application beyond just 3D hand pose estimation as well.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
3D Hand Mesh Recovery from Monocular RGB in Camera Space
Haonan Li, Patrick P. K. Chen, Yitong Zhou
0
0
With the rapid advancement of technologies such as virtual reality, augmented reality, and gesture control, users expect interactions with computer interfaces to be more natural and intuitive. Existing visual algorithms often struggle to accomplish advanced human-computer interaction tasks, necessitating accurate and reliable absolute spatial prediction methods. Moreover, dealing with complex scenes and occlusions in monocular images poses entirely new challenges. This study proposes a network model that performs parallel processing of root-relative grids and root recovery tasks. The model enables the recovery of 3D hand meshes in camera space from monocular RGB images. To facilitate end-to-end training, we utilize an implicit learning approach for 2D heatmaps, enhancing the compatibility of 2D cues across different subtasks. Incorporate the Inception concept into spectral graph convolutional network to explore relative mesh of root, and integrate it with the locally detailed and globally attentive method designed for root recovery exploration. This approach improves the model's predictive performance in complex environments and self-occluded scenes. Through evaluation on the large-scale hand dataset FreiHAND, we have demonstrated that our proposed model is comparable with state-of-the-art models. This study contributes to the advancement of techniques for accurate and reliable absolute spatial prediction in various human-computer interaction applications.
5/14/2024

GEARS: Local Geometry-aware Hand-object Interaction Synthesis
Keyang Zhou, Bharat Lal Bhatnagar, Jan Eric Lenssen, Gerard Pons-moll
0
0
Generating realistic hand motion sequences in interaction with objects has gained increasing attention with the growing interest in digital humans. Prior work has illustrated the effectiveness of employing occupancy-based or distance-based virtual sensors to extract hand-object interaction features. Nonetheless, these methods show limited generalizability across object categories, shapes and sizes. We hypothesize that this is due to two reasons: 1) the limited expressiveness of employed virtual sensors, and 2) scarcity of available training data. To tackle this challenge, we introduce a novel joint-centered sensor designed to reason about local object geometry near potential interaction regions. The sensor queries for object surface points in the neighbourhood of each hand joint. As an important step towards mitigating the learning complexity, we transform the points from global frame to hand template frame and use a shared module to process sensor features of each individual joint. This is followed by a spatio-temporal transformer network aimed at capturing correlation among the joints in different dimensions. Moreover, we devise simple heuristic rules to augment the limited training sequences with vast static hand grasping samples. This leads to a broader spectrum of grasping types observed during training, in turn enhancing our model's generalization capability. We evaluate on two public datasets, GRAB and InterCap, where our method shows superiority over baselines both quantitatively and perceptually.
5/14/2024
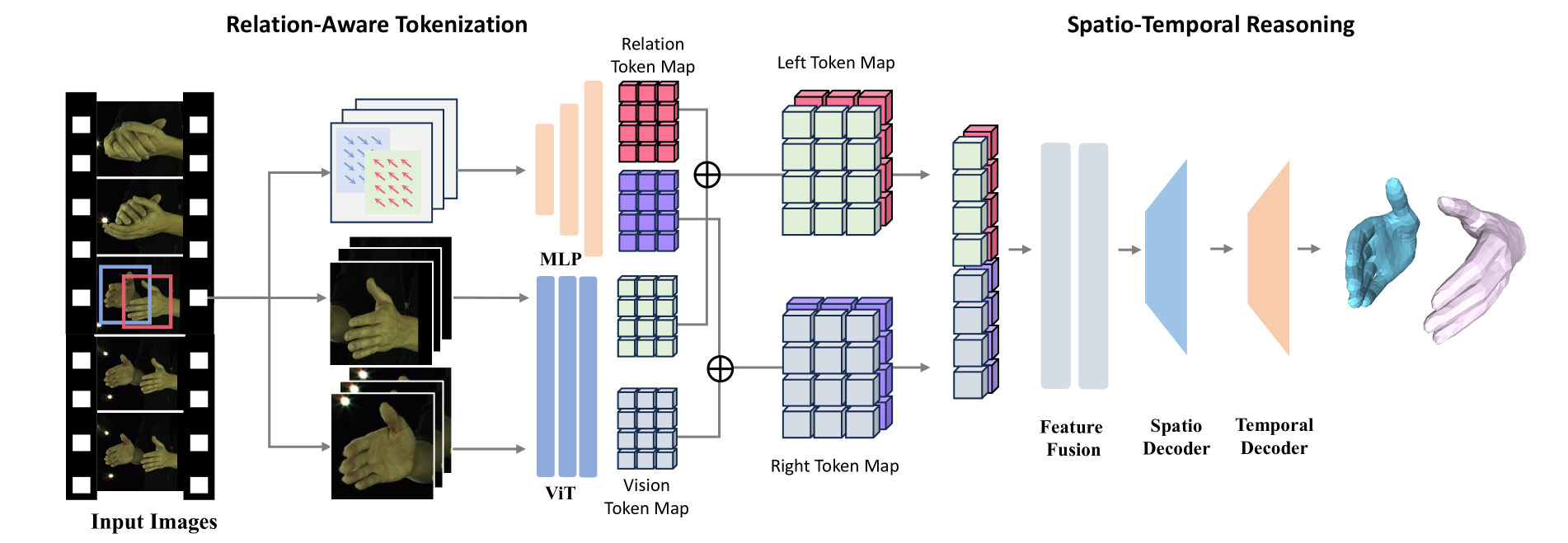
4DHands: Reconstructing Interactive Hands in 4D with Transformers
Dixuan Lin, Yuxiang Zhang, Mengcheng Li, Yebin Liu, Wei Jing, Qi Yan, Qianying Wang, Hongwen Zhang
0
0
In this paper, we introduce 4DHands, a robust approach to recovering interactive hand meshes and their relative movement from monocular inputs. Our approach addresses two major limitations of previous methods: lacking a unified solution for handling various hand image inputs and neglecting the positional relationship of two hands within images. To overcome these challenges, we develop a transformer-based architecture with novel tokenization and feature fusion strategies. Specifically, we propose a Relation-aware Two-Hand Tokenization (RAT) method to embed positional relation information into the hand tokens. In this way, our network can handle both single-hand and two-hand inputs and explicitly leverage relative hand positions, facilitating the reconstruction of intricate hand interactions in real-world scenarios. As such tokenization indicates the relative relationship of two hands, it also supports more effective feature fusion. To this end, we further develop a Spatio-temporal Interaction Reasoning (SIR) module to fuse hand tokens in 4D with attention and decode them into 3D hand meshes and relative temporal movements. The efficacy of our approach is validated on several benchmark datasets. The results on in-the-wild videos and real-world scenarios demonstrate the superior performances of our approach for interactive hand reconstruction. More video results can be found on the project page: https://4dhands.github.io.
6/3/2024
🎲
Semi-Autonomous Laparoscopic Robot Docking with Learned Hand-Eye Information Fusion
Huanyu Tian, Martin Huber, Christopher E. Mower, Zhe Han, Changsheng Li, Xingguang Duan, Christos Bergeles
0
0
In this study, we introduce a novel shared-control system for key-hole docking operations, combining a commercial camera with occlusion-robust pose estimation and a hand-eye information fusion technique. This system is used to enhance docking precision and force-compliance safety. To train a hand-eye information fusion network model, we generated a self-supervised dataset using this docking system. After training, our pose estimation method showed improved accuracy compared to traditional methods, including observation-only approaches, hand-eye calibration, and conventional state estimation filters. In real-world phantom experiments, our approach demonstrated its effectiveness with reduced position dispersion (1.23pm 0.81 mm vs. 2.47 pm 1.22 mm) and force dispersion (0.78pm 0.57 N vs. 1.15 pm 0.97 N) compared to the control group. These advancements in semi-autonomy co-manipulation scenarios enhance interaction and stability. The study presents an anti-interference, steady, and precision solution with potential applications extending beyond laparoscopic surgery to other minimally invasive procedures.
5/10/2024