U3M: Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation
2405.15365
0
0

Abstract
Multimodal semantic segmentation is a pivotal component of computer vision and typically surpasses unimodal methods by utilizing rich information set from various sources.Current models frequently adopt modality-specific frameworks that inherently biases toward certain modalities. Although these biases might be advantageous in specific situations, they generally limit the adaptability of the models across different multimodal contexts, thereby potentially impairing performance. To address this issue, we leverage the inherent capabilities of the model itself to discover the optimal equilibrium in multimodal fusion and introduce U3M: An Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation. Specifically, this method involves an unbiased integration of multimodal visual data. Additionally, we employ feature fusion at multiple scales to ensure the effective extraction and integration of both global and local features. Experimental results demonstrate that our approach achieves superior performance across multiple datasets, verifing its efficacy in enhancing the robustness and versatility of semantic segmentation in diverse settings. Our code is available at U3M-multimodal-semantic-segmentation.
Create account to get full access
Overview
- This paper introduces the Unbiased Multiscale Modal Fusion Model (U3M), a novel approach for multimodal semantic segmentation.
- Multimodal semantic segmentation combines information from multiple data modalities, such as RGB images and depth maps, to accurately identify and label objects in a scene.
- U3M addresses the problem of modal bias, where certain modalities dominate the fusion process, by using an unbiased fusion mechanism that adaptively weights each modality's contribution.
- The model also incorporates a multiscale fusion strategy to capture features at different resolutions, improving the overall segmentation performance.
Plain English Explanation
Multimodal semantic segmentation is a powerful technique that uses information from multiple data sources, like images and depth sensors, to identify and label objects in a scene. [U3M: Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation] introduces a new approach called the Unbiased Multiscale Modal Fusion Model (U3M) that aims to improve on existing methods.
The key challenge in multimodal fusion is that some data sources, or "modalities," can dominate the process, leading to biased results. U3M addresses this by using an "unbiased" fusion mechanism that dynamically adjusts the contribution of each modality, ensuring no single source overwhelms the others.
Additionally, U3M incorporates a "multiscale" fusion strategy, which means it combines information at different resolutions or scales. This allows the model to capture both fine-grained details and broader contextual information, leading to more accurate and comprehensive segmentation.
By addressing modal bias and leveraging multiscale fusion, U3M represents an important advancement in the field of multimodal semantic segmentation, with potential applications in areas like autonomous driving, robotics, and augmented reality. The plain English explanation helps make the technical concepts more accessible to a general audience.
Technical Explanation
The Unbiased Multiscale Modal Fusion Model (U3M) proposed in [U3M: Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation] addresses two key challenges in multimodal semantic segmentation: modal bias and multiscale feature extraction.
Modal bias refers to the tendency of certain modalities, such as RGB images, to dominate the fusion process, leading to suboptimal performance. U3M introduces an unbiased fusion mechanism that adaptively weights the contribution of each modality based on its relevance to the task, ensuring no single modality overwhelms the others.
To capture features at different resolutions, U3M employs a multiscale fusion strategy. The model extracts features at multiple scales and then fuses them together, allowing it to leverage both fine-grained details and broader contextual information. This multiscale fusion approach improves the model's ability to accurately segment objects of varying sizes and shapes.
The U3M architecture consists of several key components:
- Modality-specific encoders: These encode the input modalities (e.g., RGB, depth) into feature representations.
- Unbiased fusion module: This dynamically weights the contribution of each modality's features based on their relevance to the task.
- Multiscale fusion module: This combines features at different scales to capture both local and global information.
- Segmentation head: This produces the final segmentation output based on the fused features.
Through extensive experiments on benchmark datasets, the authors demonstrate that U3M outperforms state-of-the-art multimodal segmentation approaches, highlighting the benefits of the unbiased fusion mechanism and multiscale feature extraction.
Critical Analysis
The [U3M: Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation] paper presents a well-designed and effective solution to the problem of multimodal semantic segmentation. The authors' focus on addressing modal bias and incorporating multiscale fusion is a significant contribution to the field.
One potential limitation of the study is the reliance on specific benchmark datasets, which may not fully capture the diversity of real-world scenarios. [mmsformer-multimodal-transformer-material-semantic-segmentation] and [trustworthy-multimodal-fusion-sentiment-analysis-ordinal-sentiment] have also explored multimodal fusion for different tasks, and it would be interesting to see how U3M performs in those contexts.
Additionally, while the unbiased fusion mechanism is a notable innovation, the paper does not provide a deep exploration of the factors that contribute to modal bias in the first place. [unim-ov3d-uni-modality-open-vocabulary-3d] and [unsupervised-multimodal-clustering-semantics-discovery-multimodal-utterances] have investigated the nature of multimodal interactions, and their insights could potentially inform future refinements of the U3M approach.
Overall, the [U3M: Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation] paper represents a significant advancement in multimodal semantic segmentation. The authors' focus on addressing modal bias and leveraging multiscale fusion is a valuable contribution to the field, and the strong experimental results demonstrate the practical utility of the U3M model. As the research in this area continues to evolve, it will be interesting to see how the U3M approach can be further refined and applied to an even broader range of multimodal applications.
Conclusion
The [U3M: Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation] paper introduces a novel approach to multimodal semantic segmentation that addresses two key challenges: modal bias and multiscale feature extraction. By using an unbiased fusion mechanism to dynamically weight each modality's contribution and a multiscale fusion strategy to capture features at different resolutions, the U3M model demonstrates significant improvements over existing state-of-the-art methods.
This research represents an important advancement in the field of multimodal perception, with potential applications in areas like autonomous driving, robotics, and augmented reality, where accurately identifying and labeling objects in a scene is crucial. The authors' focus on addressing modal bias and leveraging multiscale fusion is a valuable contribution that can inspire further innovations in multimodal machine learning and computer vision.
As the research in this area continues to evolve, it will be interesting to see how the U3M approach can be further refined and applied to an even broader range of multimodal tasks and scenarios. The plain English explanation and critical analysis provided in this blog post aim to make the technical concepts more accessible and encourage readers to think critically about the research and its implications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
Unsupervised Multimodal Clustering for Semantics Discovery in Multimodal Utterances
Hanlei Zhang, Hua Xu, Fei Long, Xin Wang, Kai Gao
0
0
Discovering the semantics of multimodal utterances is essential for understanding human language and enhancing human-machine interactions. Existing methods manifest limitations in leveraging nonverbal information for discerning complex semantics in unsupervised scenarios. This paper introduces a novel unsupervised multimodal clustering method (UMC), making a pioneering contribution to this field. UMC introduces a unique approach to constructing augmentation views for multimodal data, which are then used to perform pre-training to establish well-initialized representations for subsequent clustering. An innovative strategy is proposed to dynamically select high-quality samples as guidance for representation learning, gauged by the density of each sample's nearest neighbors. Besides, it is equipped to automatically determine the optimal value for the top-$K$ parameter in each cluster to refine sample selection. Finally, both high- and low-quality samples are used to learn representations conducive to effective clustering. We build baselines on benchmark multimodal intent and dialogue act datasets. UMC shows remarkable improvements of 2-6% scores in clustering metrics over state-of-the-art methods, marking the first successful endeavor in this domain. The complete code and data are available at https://github.com/thuiar/UMC.
5/22/2024
👨🏫
Unified Modeling Enhanced Multimodal Learning for Precision Neuro-Oncology
Huahui Yi, Xiaofei Wang, Kang Li, Chao Li
0
0
Multimodal learning, integrating histology images and genomics, promises to enhance precision oncology with comprehensive views at microscopic and molecular levels. However, existing methods may not sufficiently model the shared or complementary information for more effective integration. In this study, we introduce a Unified Modeling Enhanced Multimodal Learning (UMEML) framework that employs a hierarchical attention structure to effectively leverage shared and complementary features of both modalities of histology and genomics. Specifically, to mitigate unimodal bias from modality imbalance, we utilize a query-based cross-attention mechanism for prototype clustering in the pathology encoder. Our prototype assignment and modularity strategy are designed to align shared features and minimizes modality gaps. An additional registration mechanism with learnable tokens is introduced to enhance cross-modal feature integration and robustness in multimodal unified modeling. Our experiments demonstrate that our method surpasses previous state-of-the-art approaches in glioma diagnosis and prognosis tasks, underscoring its superiority in precision neuro-Oncology.
6/12/2024
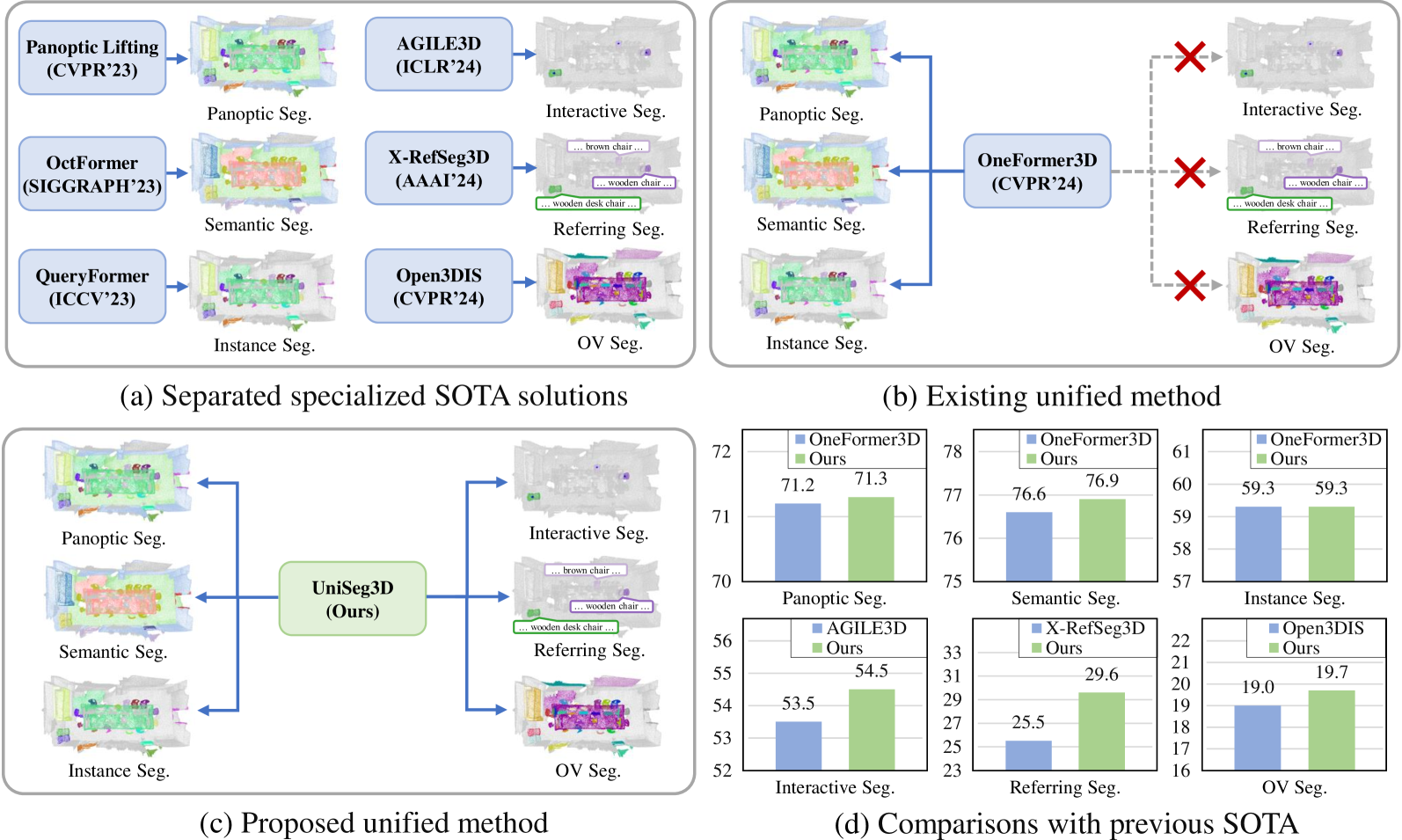
New!A Unified Framework for 3D Scene Understanding
Wei Xu, Chunsheng Shi, Sifan Tu, Xin Zhou, Dingkang Liang, Xiang Bai
0
0
We propose UniSeg3D, a unified 3D segmentation framework that achieves panoptic, semantic, instance, interactive, referring, and open-vocabulary semantic segmentation tasks within a single model. Most previous 3D segmentation approaches are specialized for a specific task, thereby limiting their understanding of 3D scenes to a task-specific perspective. In contrast, the proposed method unifies six tasks into unified representations processed by the same Transformer. It facilitates inter-task knowledge sharing and, therefore, promotes comprehensive 3D scene understanding. To take advantage of multi-task unification, we enhance the performance by leveraging task connections. Specifically, we design a knowledge distillation method and a contrastive learning method to transfer task-specific knowledge across different tasks. Benefiting from extensive inter-task knowledge sharing, our UniSeg3D becomes more powerful. Experiments on three benchmarks, including the ScanNet20, ScanRefer, and ScanNet200, demonstrate that the UniSeg3D consistently outperforms current SOTA methods, even those specialized for individual tasks. We hope UniSeg3D can serve as a solid unified baseline and inspire future work. The code will be available at https://dk-liang.github.io/UniSeg3D/.
7/4/2024
🤖
MMSFormer: Multimodal Transformer for Material and Semantic Segmentation
Md Kaykobad Reza, Ashley Prater-Bennette, M. Salman Asif
0
0
Leveraging information across diverse modalities is known to enhance performance on multimodal segmentation tasks. However, effectively fusing information from different modalities remains challenging due to the unique characteristics of each modality. In this paper, we propose a novel fusion strategy that can effectively fuse information from different modality combinations. We also propose a new model named Multi-Modal Segmentation TransFormer (MMSFormer) that incorporates the proposed fusion strategy to perform multimodal material and semantic segmentation tasks. MMSFormer outperforms current state-of-the-art models on three different datasets. As we begin with only one input modality, performance improves progressively as additional modalities are incorporated, showcasing the effectiveness of the fusion block in combining useful information from diverse input modalities. Ablation studies show that different modules in the fusion block are crucial for overall model performance. Furthermore, our ablation studies also highlight the capacity of different input modalities to improve performance in the identification of different types of materials. The code and pretrained models will be made available at https://github.com/csiplab/MMSFormer.
4/9/2024