A Unified Framework for 3D Scene Understanding

0
Sign in to get full access
Overview
- This paper presents a unified framework for 3D scene understanding that can handle multiple tasks, including object detection, semantic segmentation, and instance segmentation, in a single model.
- The framework is designed to be modality-agnostic, meaning it can work with different types of 3D data, such as point clouds, RGB-D images, and multi-view images.
- The model is also able to handle a large vocabulary of object classes, making it more versatile and applicable to a wider range of real-world scenarios.
Plain English Explanation
The paper describes a new approach to understanding 3D scenes, which are the three-dimensional environments we move through in the real world. This approach is designed to be a "one-stop shop" for different tasks related to 3D scene understanding, such as identifying objects, labeling the different parts of a scene, and separating individual objects within a scene.
The key innovation is that this framework can work with different types of 3D data, like point clouds (data points representing the 3D shape of objects) or multi-view images (multiple 2D images of a scene from different angles). This makes the framework more flexible and able to handle a wider range of real-world situations.
Another important aspect is that the framework can recognize a large number of different object classes, going beyond the relatively small set of objects that many previous 3D understanding systems could handle. This allows the system to be more useful in complex, real-world environments.
Technical Explanation
The key components of the proposed framework are:
- A modality-agnostic backbone that can process different types of 3D data, such as point clouds, RGB-D images, and multi-view images.
- A unified head that can perform multiple 3D understanding tasks, including object detection, semantic segmentation, and instance segmentation, in a single model.
- An open-vocabulary object detection module that can recognize a large number of object classes, going beyond the typical 80-100 classes used in many previous systems.
The authors demonstrate the effectiveness of their framework on several benchmark datasets, showing that it can outperform specialized models for individual tasks while maintaining the ability to handle multiple tasks simultaneously.
Critical Analysis
One potential limitation of the framework is that it may not be as efficient or optimized for individual tasks as specialized models. The authors acknowledge this trade-off in the paper, noting that the unified approach sacrifices some performance on individual tasks in order to achieve the versatility of handling multiple tasks.
Additionally, the open-vocabulary object detection module, while a valuable capability, may struggle with rare or novel object classes that are not well-represented in the training data. The paper does not provide a detailed analysis of the framework's performance on such edge cases.
Further research could explore ways to improve the efficiency and robustness of the unified framework, perhaps by incorporating more sophisticated task-specific components or adaptive mechanisms to handle a wider range of 3D data and object classes.
Conclusion
This paper presents a promising step towards a more comprehensive and versatile approach to 3D scene understanding. By unifying multiple tasks into a single modality-agnostic framework, the authors have created a system that can handle a wide range of real-world scenarios, with the potential to have a significant impact on applications such as robotics, autonomous vehicles, and augmented reality.
The ability to recognize a large vocabulary of object classes is a particularly noteworthy feature, as it allows the framework to be more widely applicable in complex environments. While the framework may not be as optimized for individual tasks as specialized models, its versatility and potential for future improvements make it an exciting development in the field of 3D scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Unified Framework for 3D Scene Understanding
Wei Xu, Chunsheng Shi, Sifan Tu, Xin Zhou, Dingkang Liang, Xiang Bai
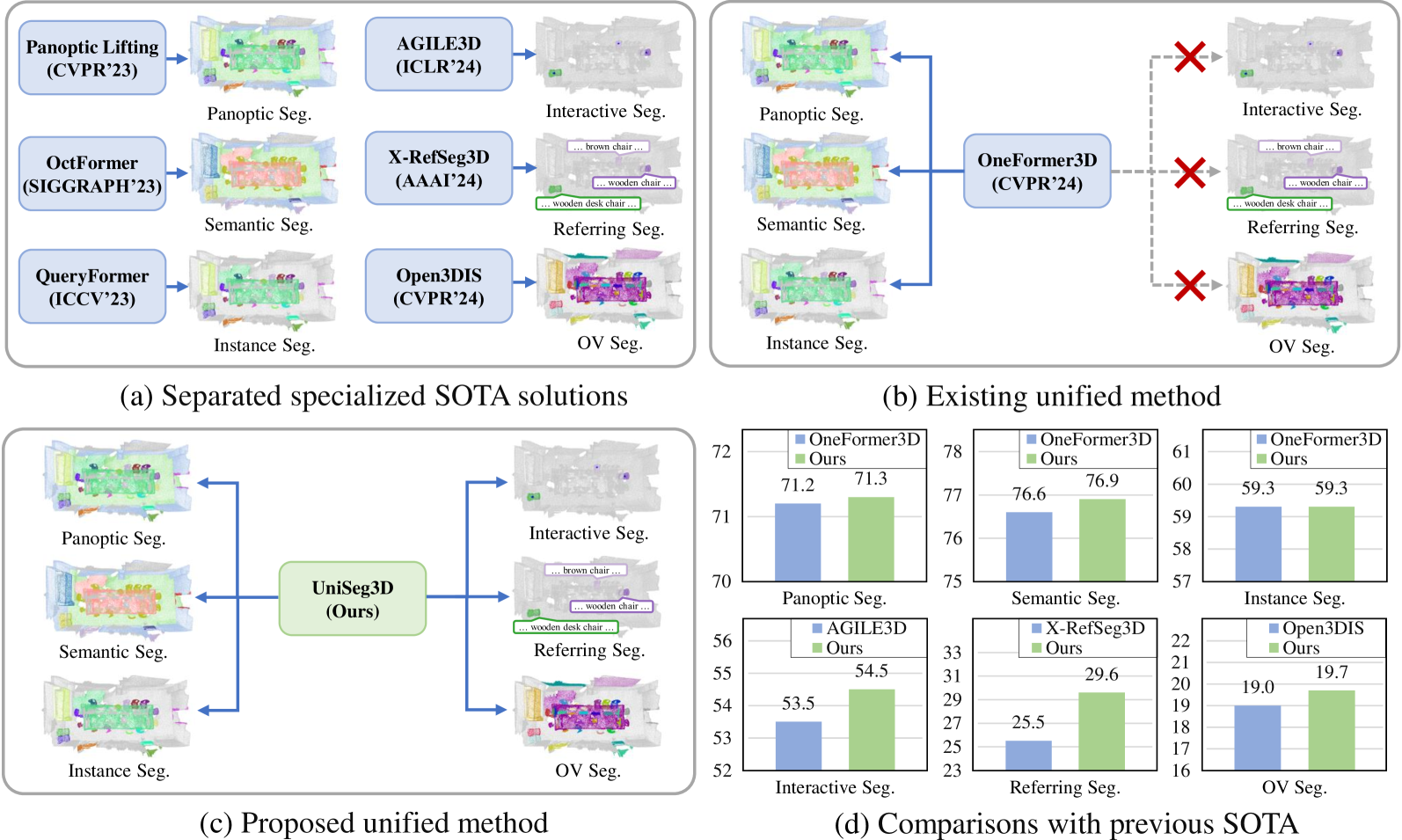
We propose UniSeg3D, a unified 3D segmentation framework that achieves panoptic, semantic, instance, interactive, referring, and open-vocabulary semantic segmentation tasks within a single model. Most previous 3D segmentation approaches are specialized for a specific task, thereby limiting their understanding of 3D scenes to a task-specific perspective. In contrast, the proposed method unifies six tasks into unified representations processed by the same Transformer. It facilitates inter-task knowledge sharing and, therefore, promotes comprehensive 3D scene understanding. To take advantage of multi-task unification, we enhance the performance by leveraging task connections. Specifically, we design a knowledge distillation method and a contrastive learning method to transfer task-specific knowledge across different tasks. Benefiting from extensive inter-task knowledge sharing, our UniSeg3D becomes more powerful. Experiments on three benchmarks, including the ScanNet20, ScanRefer, and ScanNet200, demonstrate that the UniSeg3D consistently outperforms current SOTA methods, even those specialized for individual tasks. We hope UniSeg3D can serve as a solid unified baseline and inspire future work. The code will be available at https://dk-liang.github.io/UniSeg3D/.
Read more7/4/2024

0
UniM-OV3D: Uni-Modality Open-Vocabulary 3D Scene Understanding with Fine-Grained Feature Representation
Qingdong He, Jinlong Peng, Zhengkai Jiang, Kai Wu, Xiaozhong Ji, Jiangning Zhang, Yabiao Wang, Chengjie Wang, Mingang Chen, Yunsheng Wu
3D open-vocabulary scene understanding aims to recognize arbitrary novel categories beyond the base label space. However, existing works not only fail to fully utilize all the available modal information in the 3D domain but also lack sufficient granularity in representing the features of each modality. In this paper, we propose a unified multimodal 3D open-vocabulary scene understanding network, namely UniM-OV3D, which aligns point clouds with image, language and depth. To better integrate global and local features of the point clouds, we design a hierarchical point cloud feature extraction module that learns comprehensive fine-grained feature representations. Further, to facilitate the learning of coarse-to-fine point-semantic representations from captions, we propose the utilization of hierarchical 3D caption pairs, capitalizing on geometric constraints across various viewpoints of 3D scenes. Extensive experimental results demonstrate the effectiveness and superiority of our method in open-vocabulary semantic and instance segmentation, which achieves state-of-the-art performance on both indoor and outdoor benchmarks such as ScanNet, ScanNet200, S3IDS and nuScenes. Code is available at https://github.com/hithqd/UniM-OV3D.
Read more4/23/2024

0
Building a Strong Pre-Training Baseline for Universal 3D Large-Scale Perception
Haoming Chen, Zhizhong Zhang, Yanyun Qu, Ruixin Zhang, Xin Tan, Yuan Xie
An effective pre-training framework with universal 3D representations is extremely desired in perceiving large-scale dynamic scenes. However, establishing such an ideal framework that is both task-generic and label-efficient poses a challenge in unifying the representation of the same primitive across diverse scenes. The current contrastive 3D pre-training methods typically follow a frame-level consistency, which focuses on the 2D-3D relationships in each detached image. Such inconsiderate consistency greatly hampers the promising path of reaching an universal pre-training framework: (1) The cross-scene semantic self-conflict, i.e., the intense collision between primitive segments of the same semantics from different scenes; (2) Lacking a globally unified bond that pushes the cross-scene semantic consistency into 3D representation learning. To address above challenges, we propose a CSC framework that puts a scene-level semantic consistency in the heart, bridging the connection of the similar semantic segments across various scenes. To achieve this goal, we combine the coherent semantic cues provided by the vision foundation model and the knowledge-rich cross-scene prototypes derived from the complementary multi-modality information. These allow us to train a universal 3D pre-training model that facilitates various downstream tasks with less fine-tuning efforts. Empirically, we achieve consistent improvements over SOTA pre-training approaches in semantic segmentation (+1.4% mIoU), object detection (+1.0% mAP), and panoptic segmentation (+3.0% PQ) using their task-specific 3D network on nuScenes. Code is released at https://github.com/chenhaomingbob/CSC, hoping to inspire future research.
Read more5/14/2024
🤷
0
UnScene3D: Unsupervised 3D Instance Segmentation for Indoor Scenes
David Rozenberszki, Or Litany, Angela Dai
3D instance segmentation is fundamental to geometric understanding of the world around us. Existing methods for instance segmentation of 3D scenes rely on supervision from expensive, manual 3D annotations. We propose UnScene3D, the first fully unsupervised 3D learning approach for class-agnostic 3D instance segmentation of indoor scans. UnScene3D first generates pseudo masks by leveraging self-supervised color and geometry features to find potential object regions. We operate on a basis of geometric oversegmentation, enabling efficient representation and learning on high-resolution 3D data. The coarse proposals are then refined through self-training our model on its predictions. Our approach improves over state-of-the-art unsupervised 3D instance segmentation methods by more than 300% Average Precision score, demonstrating effective instance segmentation even in challenging, cluttered 3D scenes.
Read more5/1/2024