UDON: A case for offloading to general purpose compute on CXL memory

0
Sign in to get full access
Overview
- This paper explores the potential benefits of offloading computations to general-purpose compute resources connected via Compute Express Link (CXL) memory, rather than relying solely on specialized accelerators.
- The proposed approach, called UDON, aims to address the performance and efficiency challenges faced by current machine learning inference systems.
- The paper presents a detailed evaluation of UDON's performance and energy efficiency, demonstrating its advantages over traditional GPU-based inference.
Plain English Explanation
The paper discusses a new way to handle the computations required for machine learning (ML) tasks, such as image recognition or language processing. Current systems often rely on specialized hardware accelerators, like graphics processing units (GPUs), to speed up these computations. However, the authors argue that there are potential benefits to offloading some of this work to general-purpose compute resources that are connected to the system's memory using a technology called Compute Express Link (CXL).
The proposed approach, called UDON, aims to take advantage of the flexibility and efficiency of these general-purpose compute resources, rather than solely relying on specialized accelerators. The researchers conducted a thorough evaluation of UDON's performance and energy efficiency, comparing it to traditional GPU-based inference systems. Their results suggest that UDON can offer significant improvements in these areas, making it a potentially useful alternative for handling the growing computational demands of modern ML applications.
Technical Explanation
The paper begins by highlighting the increasing computational demands of machine learning inference, driven by the rise of large, complex models and the need for real-time processing. This has led to a heavy reliance on specialized hardware accelerators, such as GPUs, to handle these workloads.
However, the authors argue that this approach has limitations in terms of performance, energy efficiency, and flexibility. They propose an alternative approach, called UDON, which leverages the Compute Express Link (CXL) standard to offload computations to general-purpose compute resources that are directly connected to the system's memory.
The UDON architecture consists of a host CPU, a CXL-connected compute module, and a CXL-connected memory module. The compute module is a general-purpose processor that can be used to accelerate various ML inference tasks, while the memory module provides high-bandwidth, low-latency access to the data required for these computations.
The paper presents a detailed evaluation of UDON's performance and energy efficiency, comparing it to a traditional GPU-based inference system. The results demonstrate that UDON can achieve significant improvements in both areas, with up to 2.1x better performance and 1.8x better energy efficiency for certain workloads.
The authors attribute these benefits to the flexibility and efficiency of the general-purpose compute resources in UDON, as well as the low-latency, high-bandwidth access to memory provided by the CXL interconnect.
Critical Analysis
The paper presents a compelling case for the use of general-purpose compute resources in ML inference systems, as opposed to relying solely on specialized accelerators. The authors have done a thorough job of evaluating the performance and energy efficiency of their proposed UDON architecture, and the results suggest that it can offer meaningful improvements over traditional GPU-based approaches.
However, the paper does not delve into some potential limitations or challenges that may need to be addressed. For example, the authors do not discuss the potential complexity or overhead of managing the offloading of computations between the host CPU, the CXL-connected compute module, and the CXL-connected memory module. Additionally, the paper does not address the scalability of the UDON approach or how it might perform in the context of larger, more complex ML models and workloads.
Furthermore, the paper could have provided more insight into the specific use cases or application domains where the UDON approach would be most beneficial. While the performance and efficiency improvements are compelling, it would be helpful to understand the types of ML inference tasks or scenarios where UDON is likely to offer the greatest advantages.
Overall, the paper presents a well-designed and thoroughly evaluated alternative to traditional GPU-based ML inference systems. However, further research and analysis may be needed to fully understand the broader implications and applicability of the UDON approach.
Conclusion
The UDON paper presents a novel approach to handling the growing computational demands of machine learning inference by offloading computations to general-purpose compute resources connected via Compute Express Link (CXL) memory. The researchers' detailed evaluation of UDON's performance and energy efficiency suggests that this approach can offer significant improvements over traditional GPU-based inference systems.
The key insight of the UDON approach is the recognition that specialized accelerators may not be the optimal solution for all ML inference tasks, and that leveraging the flexibility and efficiency of general-purpose compute resources can provide tangible benefits. As the computational requirements of ML continue to evolve, the UDON approach may represent an important step towards more versatile and efficient inference systems that can better adapt to the changing landscape of machine learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UDON: A case for offloading to general purpose compute on CXL memory
Jon Hermes, Josh Minor, Minjun Wu, Adarsh Patil, Eric Van Hensbergen
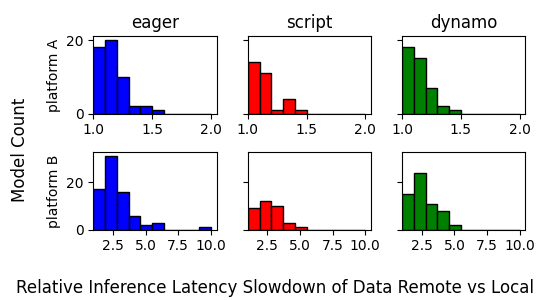
Upcoming CXL-based disaggregated memory devices feature special purpose units to offload compute to near-memory. In this paper, we explore opportunities for offloading compute to general purpose cores on CXL memory devices, thereby enabling a greater utility and diversity of offload. We study two classes of popular memory intensive applications: ML inference and vector database as candidates for computational offload. The study uses Arm AArch64-based dual-socket NUMA systems to emulate CXL type-2 devices. Our study shows promising results. With our ML inference model partitioning strategy for compute offload, we can place up to 90% data in remote memory with just 20% performance trade-off. Offloading Hierarchical Navigable Small World (HNSW) kernels in vector databases can provide upto 6.87$times$ performance improvement with under 10% offload overhead.
Read more4/4/2024
0
emucxl: an emulation framework for CXL-based disaggregated memory applications
Raja Gond, Purushottam Kulkarni
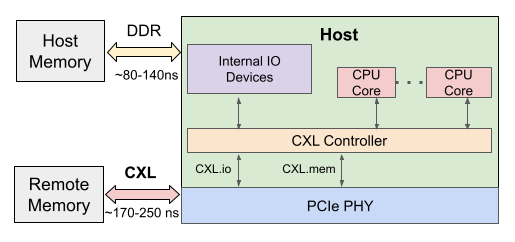
The emergence of CXL (Compute Express Link) promises to transform the status of interconnects between host and devices and in turn impact the design of all software layers. With its low overhead, low latency, and memory coherency capabilities, CXL has the potential to improve the performance of existing devices while making viable new operational use cases (e.g., disaggregated memory pools, cache coherent memory across devices etc.). The focus of this work is design of applications and middleware with use of CXL for supporting disaggregated memory. A vital building block for solutions in this space is the availability of a standard CXL hardware and software platform. Currently, CXL devices are not commercially available, and researchers often rely on custom-built hardware or emulation techniques and/or use customized software interfaces and abstractions. These techniques do not provide a standard usage model and abstraction layer for CXL usage, and developers and researchers have to reinvent the CXL setup to design and test their solutions, our work aims to provide a standardized view of the CXL emulation platform and the software interfaces and abstractions for disaggregated memory. This standardization is designed and implemented as a user space library, emucxl and is available as a virtual appliance. The library provides a user space API and is coupled with a NUMA-based CXL emulation backend. Further, we demonstrate usage of the standardized API for different use cases relying on disaggregated memory and show that generalized functionality can be built using the open source emucxl library.
Read more4/15/2024
0
Optimizing Offload Performance in Heterogeneous MPSoCs
Luca Colagrande, Luca Benini
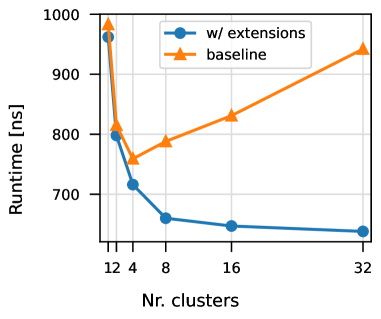
Heterogeneous multi-core architectures combine a few host cores, optimized for single-thread performance, with many small energy-efficient accelerator cores for data-parallel processing, on a single chip. Offloading a computation to the many-core acceleration fabric introduces a communication and synchronization cost which reduces the speedup attainable on the accelerator, particularly for small and fine-grained parallel tasks. We demonstrate that by co-designing the hardware and offload routines, we can increase the speedup of an offloaded DAXPY kernel by as much as 47.9%. Furthermore, we show that it is possible to accurately model the runtime of an offloaded application, accounting for the offload overheads, with as low as 1% MAPE error, enabling optimal offload decisions under offload execution time constraints.
Read more4/3/2024
0
Streamlining CXL Adoption for Hyperscale Efficiency
Angelos Arelakis, Nilesh Shah, Yiannis Nikolakopoulos, Dimitrios Palyvos-Giannas
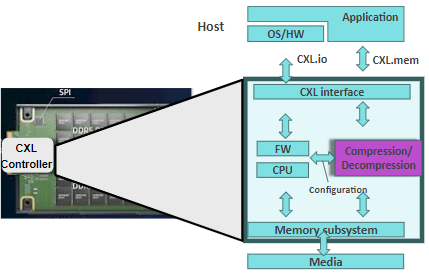
In our exploration of Composable Memory systems utilizing CXL, we focus on overcoming adoption barriers at Hyperscale, underscored by economic models demonstrating Total Cost of Ownership (TCO). While CXL addresses the pressing memory capacity needs of emerging Hyperscale applications, the escalating demands from evolving use cases such as AI outpace the capabilities of current CXL solutions. Hyperscalers resort to software-based memory (de)compression technology, alleviating memory capacity, storage, and network constraints but incurring a notable Tax on Compute CPU cycles. As a pivotal guide to the CXL community, Hyperscalers have formulated the groundbreaking Open Compute Project (OCP) Hyperscale CXL Tiered Memory Expander specification. If implemented, this specification lowers TCO adoption barriers, enabling diverse CXL deployments at both Hyperscaler and Enterprise levels. We present a CXL integrated solution, aligning with the aforementioned specification, introducing an energy-efficient, scalable, hardware-accelerated, Lossless Compressed Memory CXL Tier. This solution, slated for mid-2024 production and open for integration with Memory Expander controller manufacturers, offers 2-3X CXL memory compression in nanoseconds, delivering a 20-25% reduction in TCO for end customers without requiring additional physical slots. In our discussion, we pinpoint areas for collaborative innovation within the CXL Community to expedite software/hardware advancements for CXL Tiered Memory Expansion. Furthermore, we delve into unresolved challenges in Pooled deployment and explore potential solutions, collectively aiming to make CXL adoption a No Brainer at Hyperscale.
Read more4/5/2024