UFO: A UI-Focused Agent for Windows OS Interaction

0
Sign in to get full access
Overview
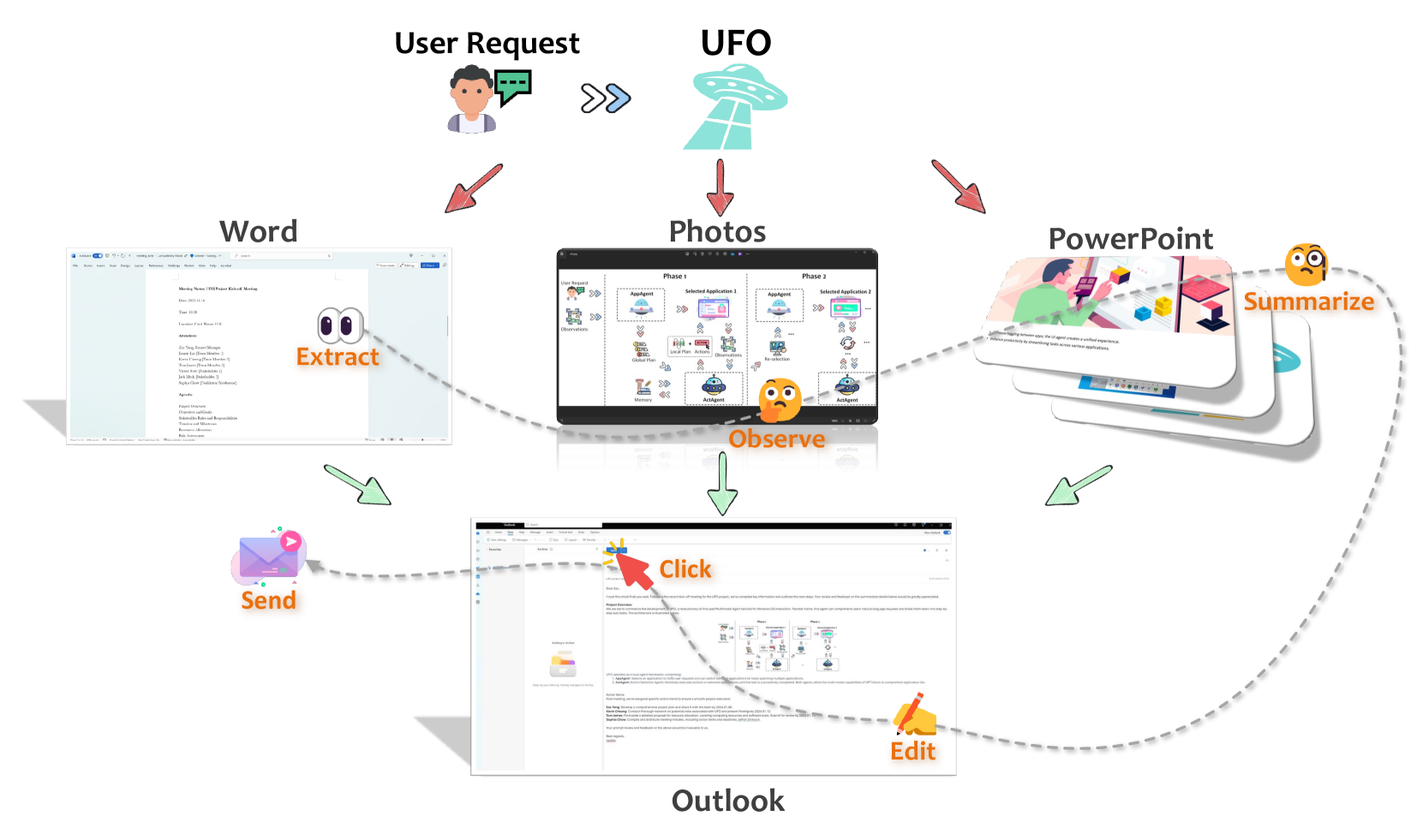
- This paper presents UFO, a user interface (UI)-focused agent for interacting with the Windows operating system.
- UFO leverages large language models (LLMs) to enable natural language interactions with UI elements, automating common tasks and enhancing user productivity.
- The system is designed to seamlessly integrate with the user's existing workflow, providing a more intuitive and efficient way to navigate and control their computer.
Plain English Explanation
The researchers have developed a new tool called UFO that allows users to control their Windows computers using natural language commands, similar to how one might talk to a digital assistant like Siri or Alexa. UFO uses advanced AI models, known as large language models (LLMs), to understand the user's requests and then perform the requested actions on the computer's user interface.
For example, rather than navigating through menus and clicking on various buttons to accomplish a task, a user could simply say "UFO, open my email and draft a new message to my boss." UFO would then interpret the command, locate the relevant email application, open a new message, and start composing the email - all without the user needing to manually interact with the computer's interface.
The key advantage of UFO is that it can make common computing tasks more efficient and user-friendly, especially for those who may not be as comfortable with traditional point-and-click interfaces. By allowing users to issue voice commands or type in natural language instructions, UFO aims to streamline the process of controlling a Windows computer and performing everyday tasks.
Technical Explanation
The UFO system leverages advancements in large language models (LLMs) to enable natural language interactions with a user's Windows operating system. The agents are trained on a large corpus of text data, allowing them to understand and respond to a wide variety of user requests.
To interact with the computer's user interface, UFO utilizes computer vision techniques to detect and identify on-screen elements, such as buttons, menus, and application windows. This allows the system to interpret the user's commands and then execute the corresponding actions by programmatically interacting with the relevant UI components.
The researchers also incorporate multimodal approaches that combine language understanding with visual perception to enhance the agent's capabilities. This includes the ability to understand context-dependent references (e.g., "open that file" while pointing to an on-screen element) and perform complex, multi-step tasks.
Through user studies, the authors demonstrate the effectiveness of UFO in improving user productivity and reducing the cognitive load associated with traditional computer interactions. The system is designed to seamlessly integrate with the user's existing workflow, providing a more natural and efficient way to control their Windows environment.
Critical Analysis
While the UFO system shows promising results, the researchers acknowledge several potential limitations and areas for future work. For instance, the current system is limited to the Windows operating system, and expanding its capabilities to other platforms, such as mobile devices or industrial control systems, would be a valuable avenue for further research.
Additionally, the paper does not provide a thorough evaluation of the system's performance in real-world, long-term usage scenarios. Assessing the system's reliability, scalability, and adaptability to diverse user preferences and computing environments would be important to ensure its practical viability.
The researchers also note the potential for privacy and security concerns, as the system's ability to interpret and interact with on-screen elements could raise risks related to the unintended exposure or manipulation of sensitive information. Addressing these issues through robust security and privacy-preserving measures would be crucial for the widespread adoption of such a system.
Conclusion
The UFO system represents a significant step towards more natural and efficient human-computer interactions, leveraging the power of large language models and computer vision to bridge the gap between user requests and UI-level actions. By allowing users to control their Windows environments through natural language commands, the system has the potential to enhance productivity, accessibility, and the overall user experience.
However, the research also highlights the need for further advancements in areas such as cross-platform compatibility, long-term reliability, and robust security and privacy safeguards. As AI-powered user interfaces continue to evolve, addressing these challenges will be crucial to ensure the widespread adoption and responsible deployment of such transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UFO: A UI-Focused Agent for Windows OS Interaction
Chaoyun Zhang, Liqun Li, Shilin He, Xu Zhang, Bo Qiao, Si Qin, Minghua Ma, Yu Kang, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, Qi Zhang
We introduce UFO, an innovative UI-Focused agent to fulfill user requests tailored to applications on Windows OS, harnessing the capabilities of GPT-Vision. UFO employs a dual-agent framework to meticulously observe and analyze the graphical user interface (GUI) and control information of Windows applications. This enables the agent to seamlessly navigate and operate within individual applications and across them to fulfill user requests, even when spanning multiple applications. The framework incorporates a control interaction module, facilitating action grounding without human intervention and enabling fully automated execution. Consequently, UFO transforms arduous and time-consuming processes into simple tasks achievable solely through natural language commands. We conducted testing of UFO across 9 popular Windows applications, encompassing a variety of scenarios reflective of users' daily usage. The results, derived from both quantitative metrics and real-case studies, underscore the superior effectiveness of UFO in fulfilling user requests. To the best of our knowledge, UFO stands as the first UI agent specifically tailored for task completion within the Windows OS environment. The open-source code for UFO is available on https://github.com/microsoft/UFO.
Read more5/24/2024
0
Identifying User Goals from UI Trajectories
Omri Berkovitch, Sapir Caduri, Noam Kahlon, Anatoly Efros, Avi Caciularu, Ido Dagan
Autonomous agents that interact with graphical user interfaces (GUIs) hold significant potential for enhancing user experiences. To further improve these experiences, agents need to be personalized and proactive. By effectively comprehending user intentions through their actions and interactions with GUIs, agents will be better positioned to achieve these goals. This paper introduces the task of goal identification from observed UI trajectories, aiming to infer the user's intended task based on their GUI interactions. We propose a novel evaluation metric to assess whether two task descriptions are paraphrases within a specific UI environment. By Leveraging the inverse relation with the UI automation task, we utilized the Android-In-The-Wild and Mind2Web datasets for our experiments. Using our metric and these datasets, we conducted several experiments comparing the performance of humans and state-of-the-art models, specifically GPT-4 and Gemini-1.5 Pro. Our results show that Gemini performs better than GPT but still underperforms compared to humans, indicating significant room for improvement.
Read more7/2/2024
👁️
0
You Only Look at Screens: Multimodal Chain-of-Action Agents
Zhuosheng Zhang, Aston Zhang
Autonomous graphical user interface (GUI) agents aim to facilitate task automation by interacting with the user interface without manual intervention. Recent studies have investigated eliciting the capabilities of large language models (LLMs) for effective engagement in diverse environments. To align with the input-output requirement of LLMs, most existing approaches are developed under a sandbox setting where they rely on external tools and application-specific APIs to parse the environment into textual elements and interpret the predicted actions. Consequently, those approaches often grapple with inference inefficiency and error propagation risks. To mitigate the challenges, we introduce Auto-GUI, a multimodal solution that directly interacts with the interface, bypassing the need for environment parsing or reliance on application-dependent APIs. Moreover, we propose a chain-of-action technique -- leveraging a series of intermediate previous action histories and future action plans -- to help the agent decide what action to execute. We evaluate our approach on a new device-control benchmark AITW with 30$K$ unique instructions, spanning multi-step tasks such as application operation, web searching, and web shopping. Experimental results show that Auto-GUI achieves state-of-the-art performance with an action type prediction accuracy of 90% and an overall action success rate of 74%. Code is publicly available at https://github.com/cooelf/Auto-GUI.
Read more6/10/2024

0
GUICourse: From General Vision Language Models to Versatile GUI Agents
Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, Yuan Yao, Yankai Lin, Zhiyuan Liu, Maosong Sun
Utilizing Graphic User Interface (GUI) for human-computer interaction is essential for accessing a wide range of digital tools. Recent advancements in Vision Language Models (VLMs) highlight the compelling potential to develop versatile agents to help humans finish GUI navigation tasks. However, current VLMs are challenged in terms of fundamental abilities (OCR and grounding) and GUI knowledge (the functions and control methods of GUI elements), preventing them from becoming practical GUI agents. To solve these challenges, we contribute GUICourse, a suite of datasets to train visual-based GUI agents from general VLMs. First, we introduce the GUIEnv dataset to strengthen the OCR and grounding capabilities of VLMs. Then, we introduce the GUIAct and GUIChat datasets to enrich their knowledge of GUI components and interactions. Experiments demonstrate that our GUI agents have better performance on common GUI tasks than their baseline VLMs. Even the small-size GUI agent (with 3.1B parameters) can still work well on single-step and multi-step GUI tasks. Finally, we analyze the different varieties in the training stage of this agent by ablation study. Our source codes and datasets are released at https://github.com/yiye3/GUICourse.
Read more6/18/2024