Ukrainian Texts Classification: Exploration of Cross-lingual Knowledge Transfer Approaches
2404.02043
0
0
Abstract
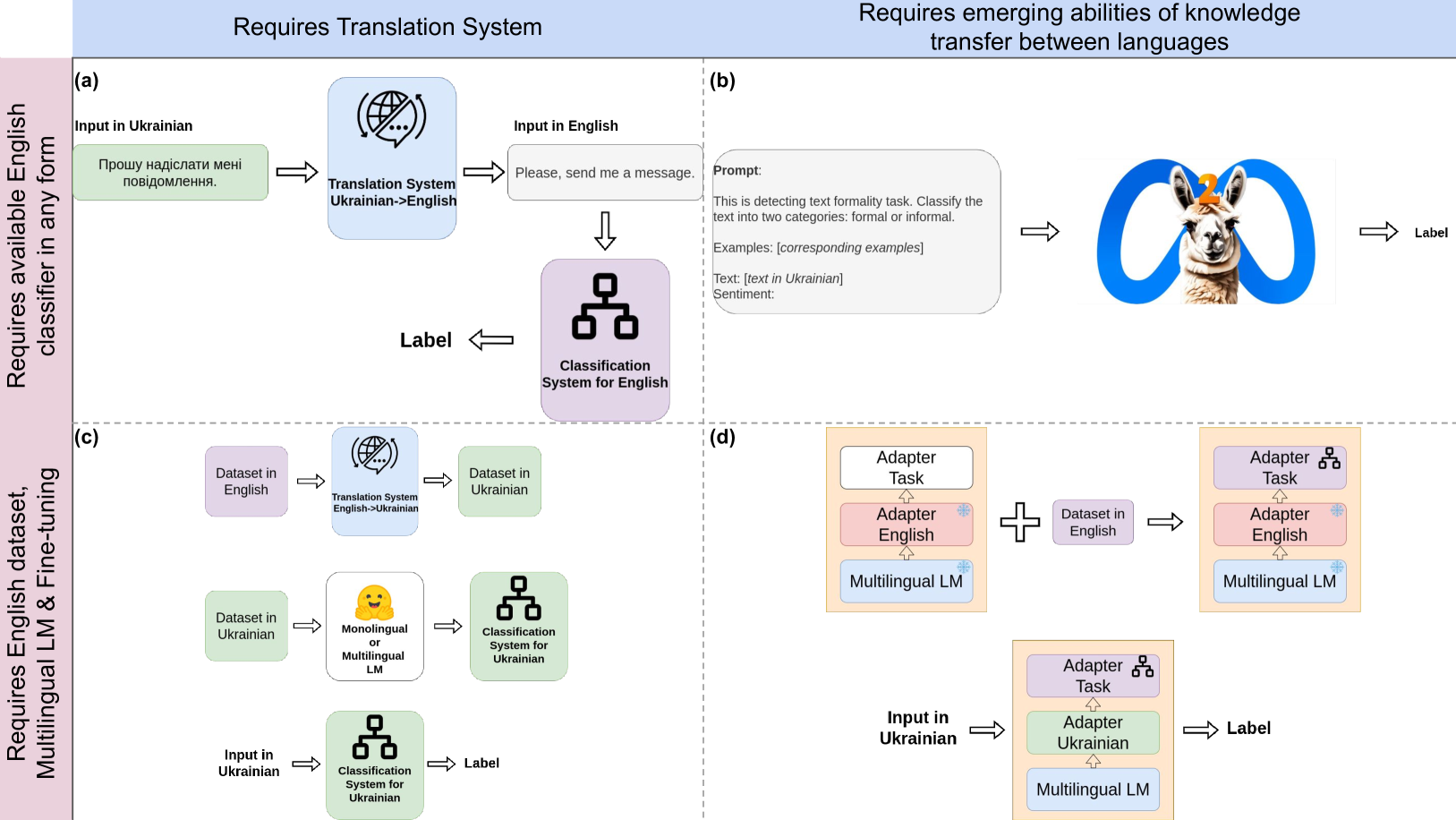
Despite the extensive amount of labeled datasets in the NLP text classification field, the persistent imbalance in data availability across various languages remains evident. Ukrainian, in particular, stands as a language that still can benefit from the continued refinement of cross-lingual methodologies. Due to our knowledge, there is a tremendous lack of Ukrainian corpora for typical text classification tasks. In this work, we leverage the state-of-the-art advances in NLP, exploring cross-lingual knowledge transfer methods avoiding manual data curation: large multilingual encoders and translation systems, LLMs, and language adapters. We test the approaches on three text classification tasks -- toxicity classification, formality classification, and natural language inference -- providing the recipe for the optimal setups.
Create account to get full access
Overview
- This paper explores using cross-lingual knowledge transfer to improve the classification of Ukrainian texts.
- The researchers investigate techniques for leveraging existing models trained on other languages to boost performance on Ukrainian text classification tasks.
- The paper presents experiments with various cross-lingual transfer learning approaches and evaluates their effectiveness.
Plain English Explanation
The researchers are trying to make it easier to automatically categorize Ukrainian text, such as news articles or social media posts. This is a valuable task for organizations that need to quickly process large amounts of Ukrainian language content.
However, building accurate text classification models for a language like Ukrainian can be challenging, as there may not be as much labeled training data available compared to more widely-spoken languages.
The key idea in this paper is to take advantage of existing machine learning models that have been trained on other languages, and adapt them to work well on Ukrainian text. This "cross-lingual transfer learning" approach could help overcome the data scarcity issue.
The researchers tested out different ways of transferring knowledge from models trained on languages like English, Russian, and Polish to improve the performance on Ukrainian text classification. They evaluated how well these transfer learning techniques performed compared to training a model solely on limited Ukrainian data.
Technical Explanation
The paper explores several cross-lingual transfer learning techniques for Ukrainian text classification:
-
Multilingual BERT (mBERT) fine-tuning: The researchers fine-tuned the multilingual BERT language model on Ukrainian text, leveraging its knowledge of multiple languages.
-
Multilingual classifier training: They trained a single classifier model using data from multiple languages, including Ukrainian, to benefit from cross-lingual knowledge.
-
Adversarial training: An adversarial training approach was used to learn language-agnostic features that could generalize better to Ukrainian.
-
Knowledge distillation: The researchers distilled knowledge from high-performing multilingual models into a more compact model tailored for Ukrainian.
The experiments were conducted on two Ukrainian text classification datasets - news articles and social media posts. The transfer learning approaches were evaluated against models trained solely on the limited Ukrainian data.
Critical Analysis
The paper provides a thorough exploration of cross-lingual transfer learning techniques for Ukrainian text classification. The results demonstrate the potential benefits of leveraging knowledge from other languages to improve performance on Ukrainian tasks.
However, the paper does not deeply analyze the limitations of the tested approaches. For example, it is unclear how the transfer learning methods would scale to larger Ukrainian datasets, or how the models would perform on more fine-grained classification tasks.
Additionally, the paper does not discuss potential ethical considerations around using multilingual models, such as potential biases or fairness issues that could arise.
Further research could investigate the robustness of these cross-lingual transfer learning techniques, as well as their applicability to other low-resource languages beyond Ukrainian.
Conclusion
This paper presents a valuable exploration of cross-lingual knowledge transfer approaches to enhance Ukrainian text classification. The results indicate that leveraging models trained on other languages can help overcome data scarcity issues and improve performance on Ukrainian tasks.
The findings have implications for building robust natural language processing systems for low-resource languages, which is an important goal for making AI technologies more inclusive and accessible globally. Further research in this direction could yield important advancements in multilingual and cross-lingual learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
Toxicity Classification in Ukrainian
Daryna Dementieva, Valeriia Khylenko, Nikolay Babakov, Georg Groh
0
0
The task of toxicity detection is still a relevant task, especially in the context of safe and fair LMs development. Nevertheless, labeled binary toxicity classification corpora are not available for all languages, which is understandable given the resource-intensive nature of the annotation process. Ukrainian, in particular, is among the languages lacking such resources. To our knowledge, there has been no existing toxicity classification corpus in Ukrainian. In this study, we aim to fill this gap by investigating cross-lingual knowledge transfer techniques and creating labeled corpora by: (i)~translating from an English corpus, (ii)~filtering toxic samples using keywords, and (iii)~annotating with crowdsourcing. We compare LLMs prompting and other cross-lingual transfer approaches with and without fine-tuning offering insights into the most robust and efficient baselines.
4/30/2024

Universal Cross-Lingual Text Classification
Riya Savant, Anushka Shelke, Sakshi Todmal, Sanskruti Kanphade, Ananya Joshi, Raviraj Joshi
0
0
Text classification, an integral task in natural language processing, involves the automatic categorization of text into predefined classes. Creating supervised labeled datasets for low-resource languages poses a considerable challenge. Unlocking the language potential of low-resource languages requires robust datasets with supervised labels. However, such datasets are scarce, and the label space is often limited. In our pursuit to address this gap, we aim to optimize existing labels/datasets in different languages. This research proposes a novel perspective on Universal Cross-Lingual Text Classification, leveraging a unified model across languages. Our approach involves blending supervised data from different languages during training to create a universal model. The supervised data for a target classification task might come from different languages covering different labels. The primary goal is to enhance label and language coverage, aiming for a label set that represents a union of labels from various languages. We propose the usage of a strong multilingual SBERT as our base model, making our novel training strategy feasible. This strategy contributes to the adaptability and effectiveness of the model in cross-lingual language transfer scenarios, where it can categorize text in languages not encountered during training. Thus, the paper delves into the intricacies of cross-lingual text classification, with a particular focus on its application for low-resource languages, exploring methodologies and implications for the development of a robust and adaptable universal cross-lingual model.
6/18/2024
Cross-lingual Named Entity Corpus for Slavic Languages
Jakub Piskorski, Micha{l} Marci'nczuk, Roman Yangarber
0
0
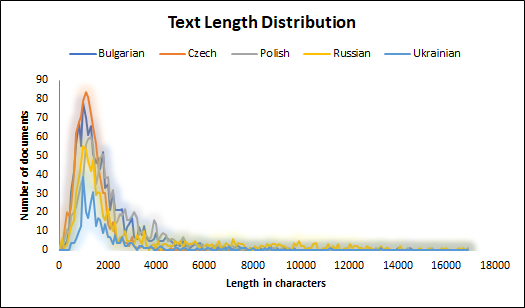
This paper presents a corpus manually annotated with named entities for six Slavic languages - Bulgarian, Czech, Polish, Slovenian, Russian, and Ukrainian. This work is the result of a series of shared tasks, conducted in 2017-2023 as a part of the Workshops on Slavic Natural Language Processing. The corpus consists of 5 017 documents on seven topics. The documents are annotated with five classes of named entities. Each entity is described by a category, a lemma, and a unique cross-lingual identifier. We provide two train-tune dataset splits - single topic out and cross topics. For each split, we set benchmarks using a transformer-based neural network architecture with the pre-trained multilingual models - XLM-RoBERTa-large for named entity mention recognition and categorization, and mT5-large for named entity lemmatization and linking.
4/9/2024

Crosslingual Capabilities and Knowledge Barriers in Multilingual Large Language Models
Lynn Chua, Badih Ghazi, Yangsibo Huang, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, Amer Sinha, Chulin Xie, Chiyuan Zhang
0
0
Large language models (LLMs) are typically multilingual due to pretraining on diverse multilingual corpora. But can these models relate corresponding concepts across languages, effectively being crosslingual? This study evaluates six state-of-the-art LLMs on inherently crosslingual tasks. We observe that while these models show promising surface-level crosslingual abilities on machine translation and embedding space analyses, they struggle with deeper crosslingual knowledge transfer, revealing a crosslingual knowledge barrier in both general (MMLU benchmark) and domain-specific (Harry Potter quiz) contexts. We observe that simple inference-time mitigation methods offer only limited improvement. On the other hand, we propose fine-tuning of LLMs on mixed-language data, which effectively reduces these gaps, even when using out-of-domain datasets like WikiText. Our findings suggest the need for explicit optimization to unlock the full crosslingual potential of LLMs. Our code is publicly available at https://github.com/google-research/crosslingual-knowledge-barriers.
6/26/2024