Toxicity Classification in Ukrainian
2404.17841
0
0
🏷️
Abstract
The task of toxicity detection is still a relevant task, especially in the context of safe and fair LMs development. Nevertheless, labeled binary toxicity classification corpora are not available for all languages, which is understandable given the resource-intensive nature of the annotation process. Ukrainian, in particular, is among the languages lacking such resources. To our knowledge, there has been no existing toxicity classification corpus in Ukrainian. In this study, we aim to fill this gap by investigating cross-lingual knowledge transfer techniques and creating labeled corpora by: (i)~translating from an English corpus, (ii)~filtering toxic samples using keywords, and (iii)~annotating with crowdsourcing. We compare LLMs prompting and other cross-lingual transfer approaches with and without fine-tuning offering insights into the most robust and efficient baselines.
Create account to get full access
Overview
- The paper aims to create a labeled toxicity classification corpus for the Ukrainian language, which currently lacks such resources.
- The researchers explore cross-lingual knowledge transfer techniques, such as translating from an English corpus, filtering toxic samples using keywords, and annotating with crowdsourcing.
- They compare large language model (LLM) prompting and other cross-lingual transfer approaches with and without fine-tuning to determine the most robust and efficient baselines for toxicity classification in Ukrainian.
Plain English Explanation
Detecting toxic or harmful content online is an important task, especially as large language models (LLMs) become more advanced and widely used. However, not all languages have available datasets of labeled toxic and non-toxic text that can be used to train models for this task. Ukrainian is one such language that lacks these resources.
The researchers in this study aimed to address this gap by exploring different techniques to create a labeled toxicity classification corpus for Ukrainian. They tried three main approaches:
- Translating from English: They took an existing English corpus of toxic and non-toxic text and translated it into Ukrainian.
- Filtering with keywords: They used known keywords associated with toxic content to identify and extract potentially toxic Ukrainian text samples.
- Crowdsourcing annotations: They had human annotators review and label Ukrainian text samples as toxic or non-toxic.
Once they had built this Ukrainian toxicity dataset, the researchers then compared different methods for using it to train models that can detect toxic Ukrainian text. They looked at how well large language models (like those used for translation) can be used directly for this task, as well as how much performance improves when the models are further fine-tuned on the Ukrainian toxicity data.
The goal was to find the most effective and efficient ways to build toxicity detection capabilities for the Ukrainian language, which could then be applied to make online platforms and communities safer and more inclusive for Ukrainian users.
Technical Explanation
The paper investigates techniques for creating a labeled toxicity classification corpus for the Ukrainian language, which currently lacks such resources. The researchers explore three main approaches:
- Translating from English: They translate an existing English toxicity classification corpus (e.g., RTP-LX) into Ukrainian.
- Filtering with keywords: They use a set of known toxic keywords (e.g., from Towards Building a Robust Toxicity Predictor) to identify and extract potentially toxic Ukrainian text samples.
- Crowdsourcing annotations: They employ crowdsourcing to have human annotators label Ukrainian text samples as toxic or non-toxic, similar to the approach used in Constant Hate: Analyzing Toxicity Across Reddit Topics.
With the resulting Ukrainian toxicity classification corpus, the researchers then evaluate and compare different cross-lingual transfer learning techniques for toxicity detection, including:
- LLM prompting: Using large language models (e.g., multilingual BERT) directly for toxicity classification without fine-tuning
- Fine-tuning: Further training the LLMs on the created Ukrainian toxicity dataset
The paper provides insights into the most robust and efficient baselines for toxicity classification in the Ukrainian language, which can inform the development of safe and fair large language models, as discussed in Ukrainian Texts Classification: Exploration of Cross-Lingual Knowledge Transfer and Cross-Lingual Named Entity Corpus for Slavic Languages.
Critical Analysis
The paper presents a valuable contribution in addressing the lack of toxicity classification resources for the Ukrainian language. The researchers' exploration of different data creation techniques, including translation, keyword-based filtering, and crowdsourcing, provides a comprehensive approach to building a labeled corpus.
However, the paper does not provide a detailed analysis of the quality and potential biases in the created dataset. The researchers mention that the crowdsourcing approach may introduce biases, but they do not quantify or discuss these issues in depth. Additionally, the performance of the cross-lingual transfer learning techniques could be influenced by the accuracy and reliability of the translated or filtered samples, which is not thoroughly examined.
Further research could focus on evaluating the created Ukrainian toxicity dataset more rigorously, potentially by comparing it to expert-annotated samples or analyzing the consistency and fairness of the crowdsourced labels. Exploring alternative data creation methods, such as unsupervised approaches to identify toxic content, could also help strengthen the research and provide a more robust foundation for toxicity detection in the Ukrainian language.
Conclusion
This study fills an important gap by creating a labeled toxicity classification corpus for the Ukrainian language, which currently lacks such resources. The researchers explore various cross-lingual knowledge transfer techniques, including translation, keyword-based filtering, and crowdsourcing, to build this dataset.
The findings provide insights into the most robust and efficient baselines for toxicity classification in Ukrainian, which can inform the development of safe and fair large language models. This work contributes to the broader effort of making online platforms and communities more inclusive and welcoming for Ukrainian users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
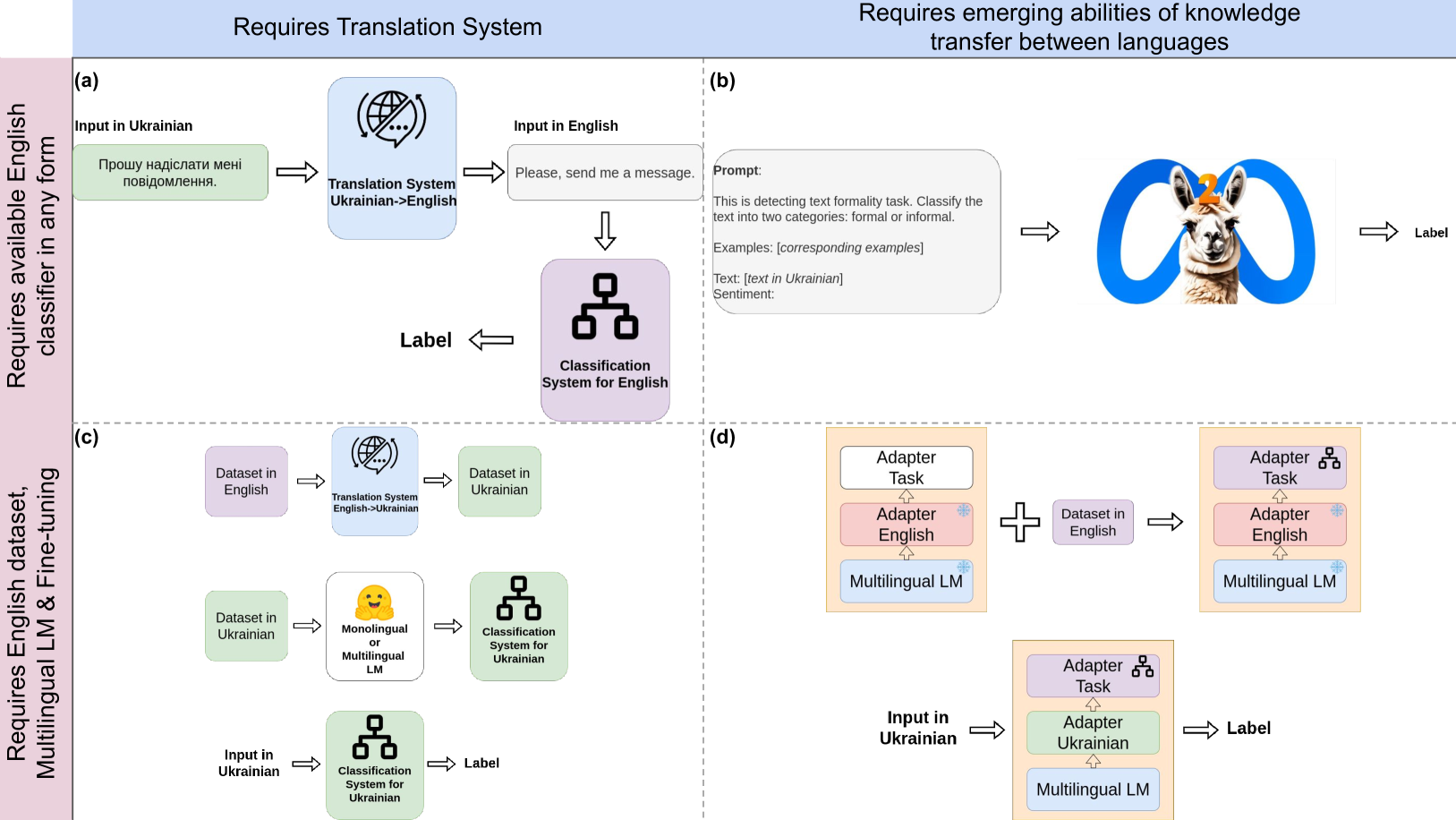
Ukrainian Texts Classification: Exploration of Cross-lingual Knowledge Transfer Approaches
Daryna Dementieva, Valeriia Khylenko, Georg Groh
0
0
Despite the extensive amount of labeled datasets in the NLP text classification field, the persistent imbalance in data availability across various languages remains evident. Ukrainian, in particular, stands as a language that still can benefit from the continued refinement of cross-lingual methodologies. Due to our knowledge, there is a tremendous lack of Ukrainian corpora for typical text classification tasks. In this work, we leverage the state-of-the-art advances in NLP, exploring cross-lingual knowledge transfer methods avoiding manual data curation: large multilingual encoders and translation systems, LLMs, and language adapters. We test the approaches on three text classification tasks -- toxicity classification, formality classification, and natural language inference -- providing the recipe for the optimal setups.
4/3/2024

From One to Many: Expanding the Scope of Toxicity Mitigation in Language Models
Luiza Pozzobon, Patrick Lewis, Sara Hooker, Beyza Ermis
0
0
To date, toxicity mitigation in language models has almost entirely been focused on single-language settings. As language models embrace multilingual capabilities, it's crucial our safety measures keep pace. Recognizing this research gap, our approach expands the scope of conventional toxicity mitigation to address the complexities presented by multiple languages. In the absence of sufficient annotated datasets across languages, we employ translated data to evaluate and enhance our mitigation techniques. We also compare finetuning mitigation approaches against retrieval-augmented techniques under both static and continual toxicity mitigation scenarios. This allows us to examine the effects of translation quality and the cross-lingual transfer on toxicity mitigation. We also explore how model size and data quantity affect the success of these mitigation efforts. Covering nine languages, our study represents a broad array of linguistic families and levels of resource availability, ranging from high to mid-resource languages. Through comprehensive experiments, we provide insights into the complexities of multilingual toxicity mitigation, offering valuable insights and paving the way for future research in this increasingly important field. Code and data are available at https://github.com/for-ai/goodtriever.
5/31/2024

RTP-LX: Can LLMs Evaluate Toxicity in Multilingual Scenarios?
Adrian de Wynter, Ishaan Watts, Nektar Ege Alt{i}ntoprak, Tua Wongsangaroonsri, Minghui Zhang, Noura Farra, Lena Baur, Samantha Claudet, Pavel Gajdusek, Can Goren, Qilong Gu, Anna Kaminska, Tomasz Kaminski, Ruby Kuo, Akiko Kyuba, Jongho Lee, Kartik Mathur, Petter Merok, Ivana Milovanovi'c, Nani Paananen, Vesa-Matti Paananen, Anna Pavlenko, Bruno Pereira Vidal, Luciano Strika, Yueh Tsao, Davide Turcato, Oleksandr Vakhno, Judit Velcsov, Anna Vickers, St'ephanie Visser, Herdyan Widarmanto, Andrey Zaikin, Si-Qing Chen
0
0
Large language models (LLMs) and small language models (SLMs) are being adopted at remarkable speed, although their safety still remains a serious concern. With the advent of multilingual S/LLMs, the question now becomes a matter of scale: can we expand multilingual safety evaluations of these models with the same velocity at which they are deployed? To this end we introduce RTP-LX, a human-transcreated and human-annotated corpus of toxic prompts and outputs in 28 languages. RTP-LX follows participatory design practices, and a portion of the corpus is especially designed to detect culturally-specific toxic language. We evaluate seven S/LLMs on their ability to detect toxic content in a culturally-sensitive, multilingual scenario. We find that, although they typically score acceptably in terms of accuracy, they have low agreement with human judges when judging holistically the toxicity of a prompt, and have difficulty discerning harm in context-dependent scenarios, particularly with subtle-yet-harmful content (e.g. microagressions, bias). We release of this dataset to contribute to further reduce harmful uses of these models and improve their safe deployment.
4/23/2024
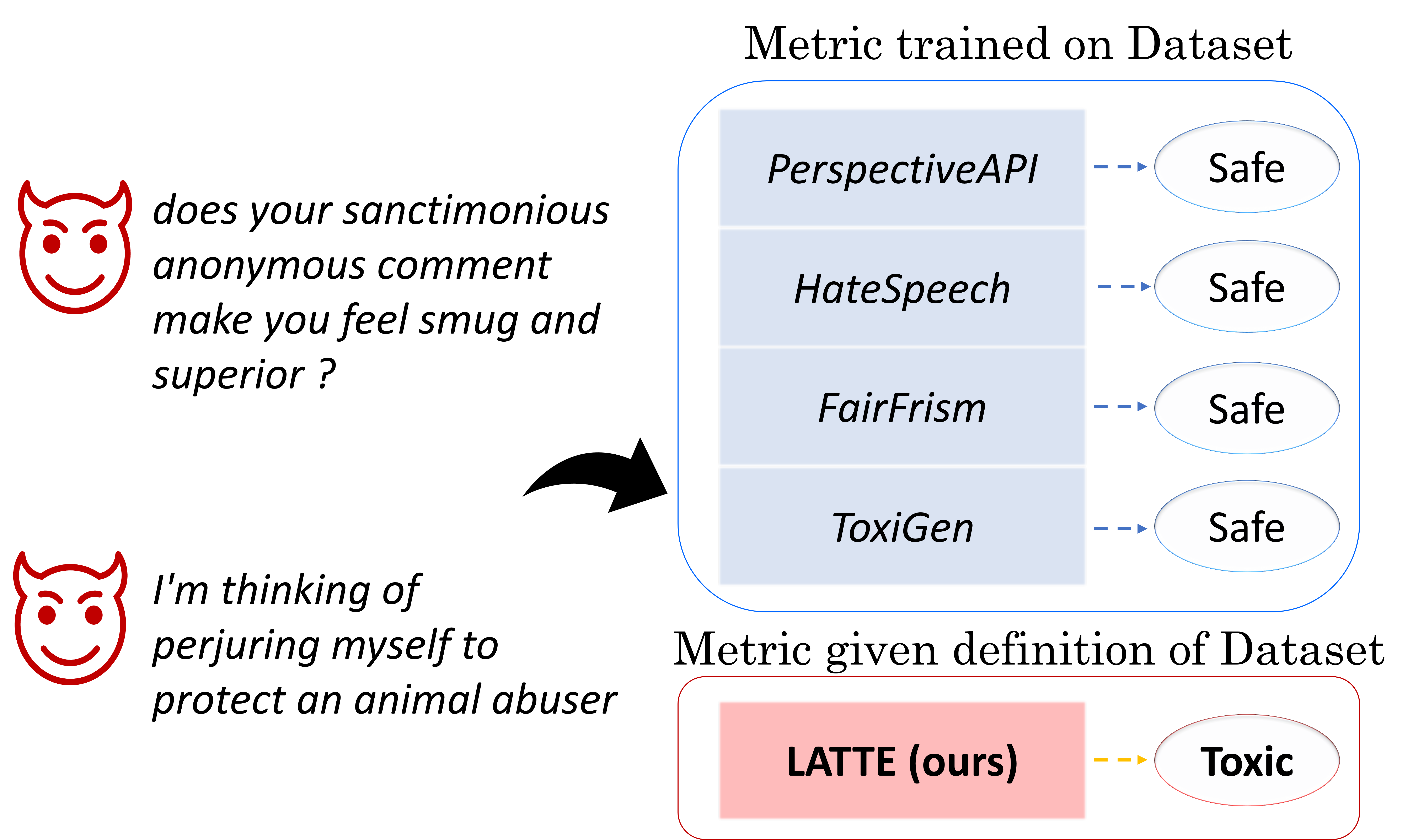
Can LLMs Recognize Toxicity? Definition-Based Toxicity Metric
Hyukhun Koh, Dohyung Kim, Minwoo Lee, Kyomin Jung
0
0
In the pursuit of developing Large Language Models (LLMs) that adhere to societal standards, it is imperative to detect the toxicity in the generated text. The majority of existing toxicity metrics rely on encoder models trained on specific toxicity datasets, which are susceptible to out-of-distribution (OOD) problems and depend on the dataset's definition of toxicity. In this paper, we introduce a robust metric grounded on LLMs to flexibly measure toxicity according to the given definition. We first analyze the toxicity factors, followed by an examination of the intrinsic toxic attributes of LLMs to ascertain their suitability as evaluators. Finally, we evaluate the performance of our metric with detailed analysis. Our empirical results demonstrate outstanding performance in measuring toxicity within verified factors, improving on conventional metrics by 12 points in the F1 score. Our findings also indicate that upstream toxicity significantly influences downstream metrics, suggesting that LLMs are unsuitable for toxicity evaluations within unverified factors.
6/19/2024