ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding
2305.08275
0
0
🤔
Abstract
Recent advancements in multimodal pre-training have shown promising efficacy in 3D representation learning by aligning multimodal features across 3D shapes, their 2D counterparts, and language descriptions. However, the methods used by existing frameworks to curate such multimodal data, in particular language descriptions for 3D shapes, are not scalable, and the collected language descriptions are not diverse. To address this, we introduce ULIP-2, a simple yet effective tri-modal pre-training framework that leverages large multimodal models to automatically generate holistic language descriptions for 3D shapes. It only needs 3D data as input, eliminating the need for any manual 3D annotations, and is therefore scalable to large datasets. ULIP-2 is also equipped with scaled-up backbones for better multimodal representation learning. We conduct experiments on two large-scale 3D datasets, Objaverse and ShapeNet, and augment them with tri-modal datasets of 3D point clouds, images, and language for training ULIP-2. Experiments show that ULIP-2 demonstrates substantial benefits in three downstream tasks: zero-shot 3D classification, standard 3D classification with fine-tuning, and 3D captioning (3D-to-language generation). It achieves a new SOTA of 50.6% (top-1) on Objaverse-LVIS and 84.7% (top-1) on ModelNet40 in zero-shot classification. In the ScanObjectNN benchmark for standard fine-tuning, ULIP-2 reaches an overall accuracy of 91.5% with a compact model of only 1.4 million parameters. ULIP-2 sheds light on a new paradigm for scalable multimodal 3D representation learning without human annotations and shows significant improvements over existing baselines. The code and datasets are released at https://github.com/salesforce/ULIP.
Create account to get full access
Overview
- This paper introduces ULIP-2, a new framework for scalable multimodal 3D representation learning without the need for manual 3D annotations.
- ULIP-2 uses large pre-trained language models to automatically generate diverse language descriptions for 3D shapes, eliminating the bottleneck of manual data collection.
- The framework demonstrates substantial benefits in downstream tasks like zero-shot 3D classification, standard 3D classification, and 3D captioning, outperforming existing methods.
Plain English Explanation
The paper discusses a new approach called ULIP-2 that can automatically generate detailed language descriptions for 3D objects, like the ones you might see in a video game or virtual reality experience. This is an important problem because existing methods for collecting these language descriptions are time-consuming and don't produce very diverse or high-quality descriptions.
ULIP-2 solves this problem by leveraging large language models that have been pre-trained on huge amounts of text data. These models are able to generate coherent and informative descriptions for 3D shapes without any manual annotation. This makes the process of creating these 3D-language datasets much more scalable and efficient.
The researchers show that this approach leads to significant improvements in various 3D understanding tasks, like being able to classify 3D objects without any prior training (zero-shot classification) and generating captions that describe 3D scenes. This suggests that ULIP-2 is able to learn richer and more useful 3D representations by leveraging the power of language.
Overall, this work represents an important step towards more unified and holistic 3D representation learning that can benefit a wide range of 3D-related applications and move us closer to more natural and intuitive 3D-language interactions.
Technical Explanation
The key idea behind ULIP-2 is to leverage large pre-trained language models, such as GPT-3, to automatically generate high-quality language descriptions for 3D shapes. This eliminates the need for manual 3D annotations, which is a major bottleneck in existing multimodal 3D representation learning frameworks.
ULIP-2 is a tri-modal pre-training framework that aligns representations across 3D point clouds, 2D images, and language. The authors show that by pre-training on large-scale datasets with this tri-modal data, ULIP-2 is able to learn rich 3D representations that generalize well to downstream tasks.
The researchers evaluate ULIP-2 on two large-scale 3D datasets, Objaverse and ShapeNet, and demonstrate its superiority over existing methods in three key benchmarks: zero-shot 3D classification, standard 3D classification with fine-tuning, and 3D captioning. For example, ULIP-2 achieves a new state-of-the-art of 50.6% top-1 accuracy on the Objaverse-LVIS zero-shot classification task.
The authors also provide an in-depth analysis of the multimodal representations learned by ULIP-2, showing that the framework is able to capture rich semantic and geometric information about 3D shapes.
Critical Analysis
The paper presents a compelling approach to scalable multimodal 3D representation learning, but there are a few potential limitations and areas for further research:
-
Generalization to Diverse 3D Data: While the authors evaluate ULIP-2 on two large-scale 3D datasets, it would be interesting to see how the framework performs on an even wider variety of 3D shapes, including more complex, real-world 3D objects and scenes.
-
Qualitative Evaluation of Generated Descriptions: The paper focuses primarily on quantitative performance metrics, but a deeper qualitative analysis of the generated language descriptions could provide additional insights into the strengths and weaknesses of the approach.
-
Efficiency and Deployment Considerations: The authors mention that ULIP-2 uses "scaled-up backbones", which could make the model computationally intensive and challenging to deploy in real-world applications. Exploring more efficient model architectures or compression techniques could be an area for future work.
-
Bias and Ethical Considerations: As with any large language model-based system, there are potential concerns around biases and ethical implications that should be carefully considered, especially when deploying such systems in real-world applications.
Despite these potential areas for improvement, the paper presents a compelling and impactful approach to multimodal 3D representation learning that could have significant implications for a wide range of 3D-related applications.
Conclusion
The ULIP-2 framework introduced in this paper represents a significant advancement in the field of multimodal 3D representation learning. By leveraging large language models to automatically generate diverse and informative language descriptions for 3D shapes, ULIP-2 eliminates the bottleneck of manual data collection and enables more scalable and effective multimodal training.
The framework's strong performance on a range of 3D understanding tasks, including zero-shot classification and 3D captioning, suggests that the learned representations are rich and generalizable, paving the way for more natural and intuitive 3D-language interactions in a variety of applications.
Overall, this work represents an important step towards more unified and holistic 3D representation learning that can benefit a wide range of 3D-related domains, from virtual reality and gaming to robotics and design.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Language-Image Models with 3D Understanding
Jang Hyun Cho, Boris Ivanovic, Yulong Cao, Edward Schmerling, Yue Wang, Xinshuo Weng, Boyi Li, Yurong You, Philipp Krahenbuhl, Yan Wang, Marco Pavone
0
0
Multi-modal large language models (MLLMs) have shown incredible capabilities in a variety of 2D vision and language tasks. We extend MLLMs' perceptual capabilities to ground and reason about images in 3-dimensional space. To that end, we first develop a large-scale pre-training dataset for 2D and 3D called LV3D by combining multiple existing 2D and 3D recognition datasets under a common task formulation: as multi-turn question-answering. Next, we introduce a new MLLM named Cube-LLM and pre-train it on LV3D. We show that pure data scaling makes a strong 3D perception capability without 3D specific architectural design or training objective. Cube-LLM exhibits intriguing properties similar to LLMs: (1) Cube-LLM can apply chain-of-thought prompting to improve 3D understanding from 2D context information. (2) Cube-LLM can follow complex and diverse instructions and adapt to versatile input and output formats. (3) Cube-LLM can be visually prompted such as 2D box or a set of candidate 3D boxes from specialists. Our experiments on outdoor benchmarks demonstrate that Cube-LLM significantly outperforms existing baselines by 21.3 points of AP-BEV on the Talk2Car dataset for 3D grounded reasoning and 17.7 points on the DriveLM dataset for complex reasoning about driving scenarios, respectively. Cube-LLM also shows competitive results in general MLLM benchmarks such as refCOCO for 2D grounding with (87.0) average score, as well as visual question answering benchmarks such as VQAv2, GQA, SQA, POPE, etc. for complex reasoning. Our project is available at https://janghyuncho.github.io/Cube-LLM.
5/7/2024
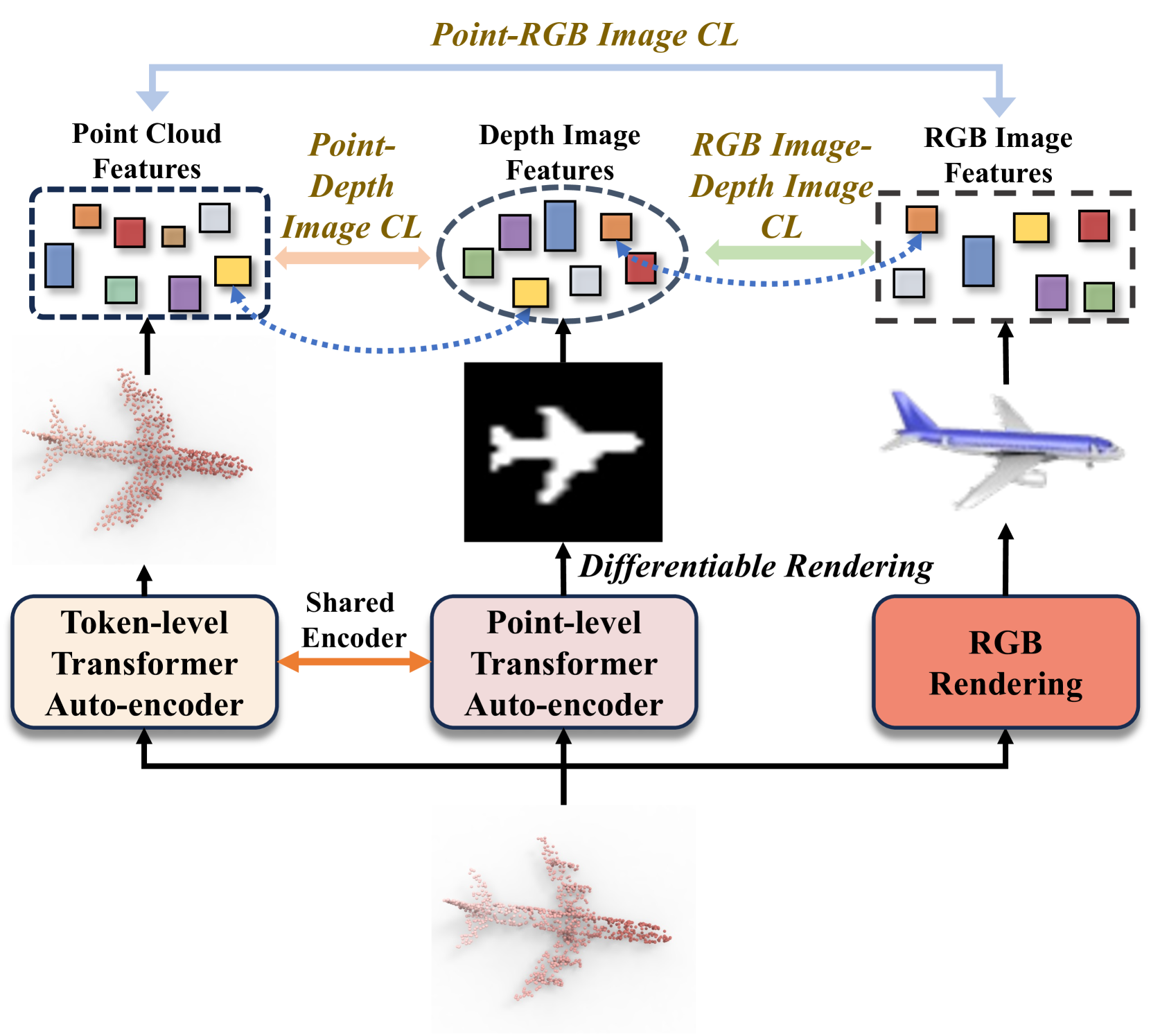
Towards Unified Representation of Multi-Modal Pre-training for 3D Understanding via Differentiable Rendering
Ben Fei, Yixuan Li, Weidong Yang, Lipeng Ma, Ying He
0
0
State-of-the-art 3D models, which excel in recognition tasks, typically depend on large-scale datasets and well-defined category sets. Recent advances in multi-modal pre-training have demonstrated potential in learning 3D representations by aligning features from 3D shapes with their 2D RGB or depth counterparts. However, these existing frameworks often rely solely on either RGB or depth images, limiting their effectiveness in harnessing a comprehensive range of multi-modal data for 3D applications. To tackle this challenge, we present DR-Point, a tri-modal pre-training framework that learns a unified representation of RGB images, depth images, and 3D point clouds by pre-training with object triplets garnered from each modality. To address the scarcity of such triplets, DR-Point employs differentiable rendering to obtain various depth images. This approach not only augments the supply of depth images but also enhances the accuracy of reconstructed point clouds, thereby promoting the representative learning of the Transformer backbone. Subsequently, using a limited number of synthetically generated triplets, DR-Point effectively learns a 3D representation space that aligns seamlessly with the RGB-Depth image space. Our extensive experiments demonstrate that DR-Point outperforms existing self-supervised learning methods in a wide range of downstream tasks, including 3D object classification, part segmentation, point cloud completion, semantic segmentation, and detection. Additionally, our ablation studies validate the effectiveness of DR-Point in enhancing point cloud understanding.
4/23/2024
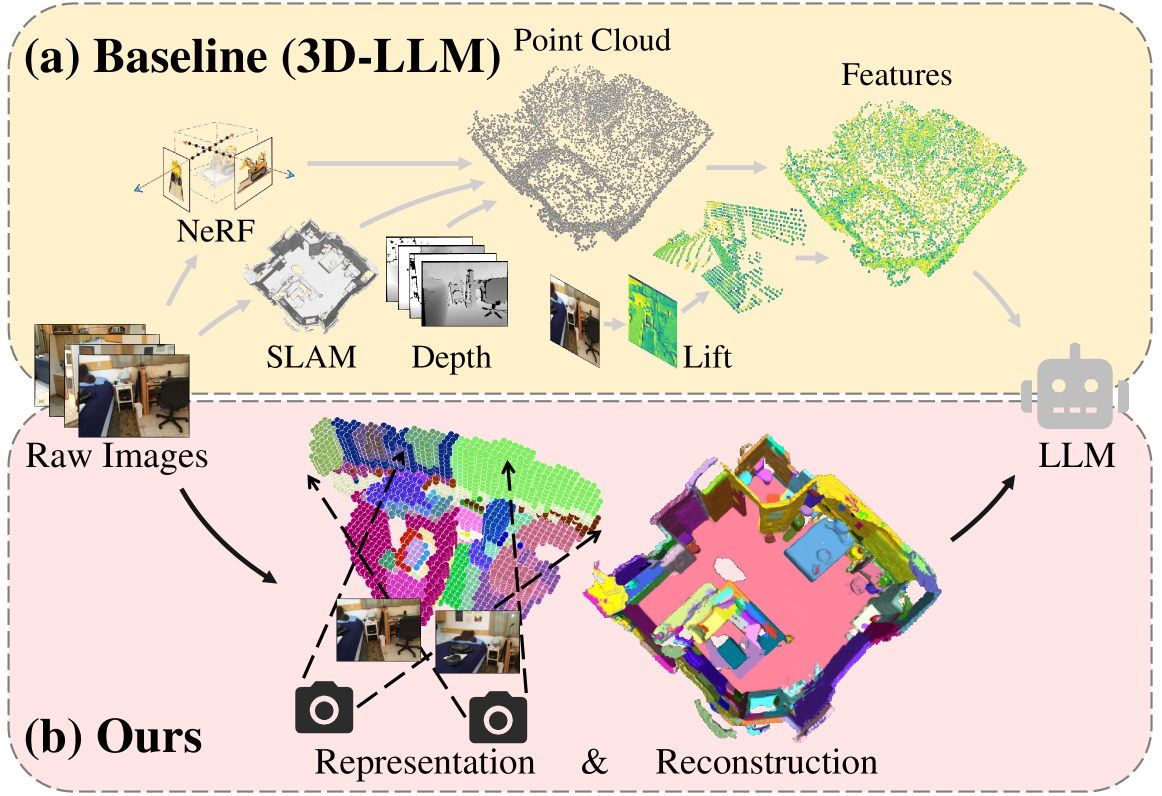
Unified Scene Representation and Reconstruction for 3D Large Language Models
Tao Chu, Pan Zhang, Xiaoyi Dong, Yuhang Zang, Qiong Liu, Jiaqi Wang
0
0
Enabling Large Language Models (LLMs) to interact with 3D environments is challenging. Existing approaches extract point clouds either from ground truth (GT) geometry or 3D scenes reconstructed by auxiliary models. Text-image aligned 2D features from CLIP are then lifted to point clouds, which serve as inputs for LLMs. However, this solution lacks the establishment of 3D point-to-point connections, leading to a deficiency of spatial structure information. Concurrently, the absence of integration and unification between the geometric and semantic representations of the scene culminates in a diminished level of 3D scene understanding. In this paper, we demonstrate the importance of having a unified scene representation and reconstruction framework, which is essential for LLMs in 3D scenes. Specifically, we introduce Uni3DR^2 extracts 3D geometric and semantic aware representation features via the frozen pre-trained 2D foundation models (e.g., CLIP and SAM) and a multi-scale aggregate 3D decoder. Our learned 3D representations not only contribute to the reconstruction process but also provide valuable knowledge for LLMs. Experimental results validate that our Uni3DR^2 yields convincing gains over the baseline on the 3D reconstruction dataset ScanNet (increasing F-Score by +1.8%). When applied to LLMs, our Uni3DR^2-LLM exhibits superior performance over the baseline on the 3D vision-language understanding dataset ScanQA (increasing BLEU-1 by +4.0% and +4.2% on the val set and test set, respectively). Furthermore, it outperforms the state-of-the-art method that uses additional GT point clouds on both ScanQA and 3DMV-VQA.
4/22/2024

Building a Strong Pre-Training Baseline for Universal 3D Large-Scale Perception
Haoming Chen, Zhizhong Zhang, Yanyun Qu, Ruixin Zhang, Xin Tan, Yuan Xie
0
0
An effective pre-training framework with universal 3D representations is extremely desired in perceiving large-scale dynamic scenes. However, establishing such an ideal framework that is both task-generic and label-efficient poses a challenge in unifying the representation of the same primitive across diverse scenes. The current contrastive 3D pre-training methods typically follow a frame-level consistency, which focuses on the 2D-3D relationships in each detached image. Such inconsiderate consistency greatly hampers the promising path of reaching an universal pre-training framework: (1) The cross-scene semantic self-conflict, i.e., the intense collision between primitive segments of the same semantics from different scenes; (2) Lacking a globally unified bond that pushes the cross-scene semantic consistency into 3D representation learning. To address above challenges, we propose a CSC framework that puts a scene-level semantic consistency in the heart, bridging the connection of the similar semantic segments across various scenes. To achieve this goal, we combine the coherent semantic cues provided by the vision foundation model and the knowledge-rich cross-scene prototypes derived from the complementary multi-modality information. These allow us to train a universal 3D pre-training model that facilitates various downstream tasks with less fine-tuning efforts. Empirically, we achieve consistent improvements over SOTA pre-training approaches in semantic segmentation (+1.4% mIoU), object detection (+1.0% mAP), and panoptic segmentation (+3.0% PQ) using their task-specific 3D network on nuScenes. Code is released at https://github.com/chenhaomingbob/CSC, hoping to inspire future research.
5/14/2024