A Unified Framework for Human-centric Point Cloud Video Understanding
2403.20031
0
0
Abstract
Human-centric Point Cloud Video Understanding (PVU) is an emerging field focused on extracting and interpreting human-related features from sequences of human point clouds, further advancing downstream human-centric tasks and applications. Previous works usually focus on tackling one specific task and rely on huge labeled data, which has poor generalization capability. Considering that human has specific characteristics, including the structural semantics of human body and the dynamics of human motions, we propose a unified framework to make full use of the prior knowledge and explore the inherent features in the data itself for generalized human-centric point cloud video understanding. Extensive experiments demonstrate that our method achieves state-of-the-art performance on various human-related tasks, including action recognition and 3D pose estimation. All datasets and code will be released soon.
Create account to get full access
Introduction
This text discusses human-centric point cloud video understanding (PVU), a field focused on analyzing and interpreting human-related information in sequences of human point clouds captured by LiDAR. PVU has gained significant attention due to its critical role in enabling various downstream tasks like human action recognition, 3D pose estimation, and motion capture, which can drive progress in real-world applications such as intelligent surveillance and human-robot collaboration.
Current PVU methods rely on extensive labeled data and generic point cloud feature extraction models, but obtaining the necessary data and annotations is challenging and expensive. These fully supervised techniques also tend to overfit to specific datasets or tasks, limiting their generalization capabilities. Additionally, existing feature extraction networks are not well-suited for human-centric data as they do not account for human-specific characteristics.
The text highlights the importance of self-supervised learning in enhancing the generalization of PVU algorithms. It also suggests the development of a human-specific feature extractor that leverages prior human-related knowledge as a promising approach to improve the effectiveness of PVU methods for downstream tasks.
The paper discusses recent progress in self-supervised learning for point cloud video understanding (PVU). While existing methods leverage contrastive learning techniques to capture spatio-temporal features, they face challenges due to irregular point distributions from varying capture distances, occlusions, and noise. The latest work exploits mask prediction but flattens the point cloud tubes, compromising semantic and dynamic consistency.
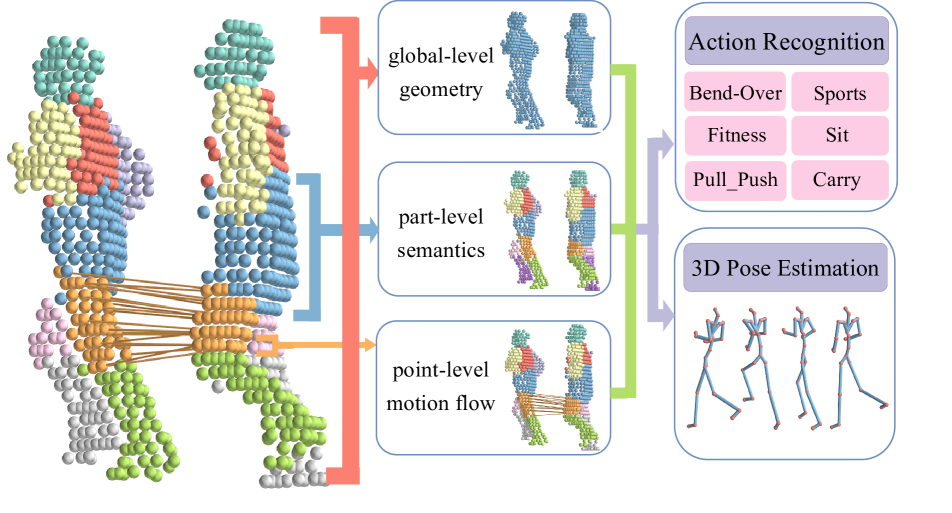
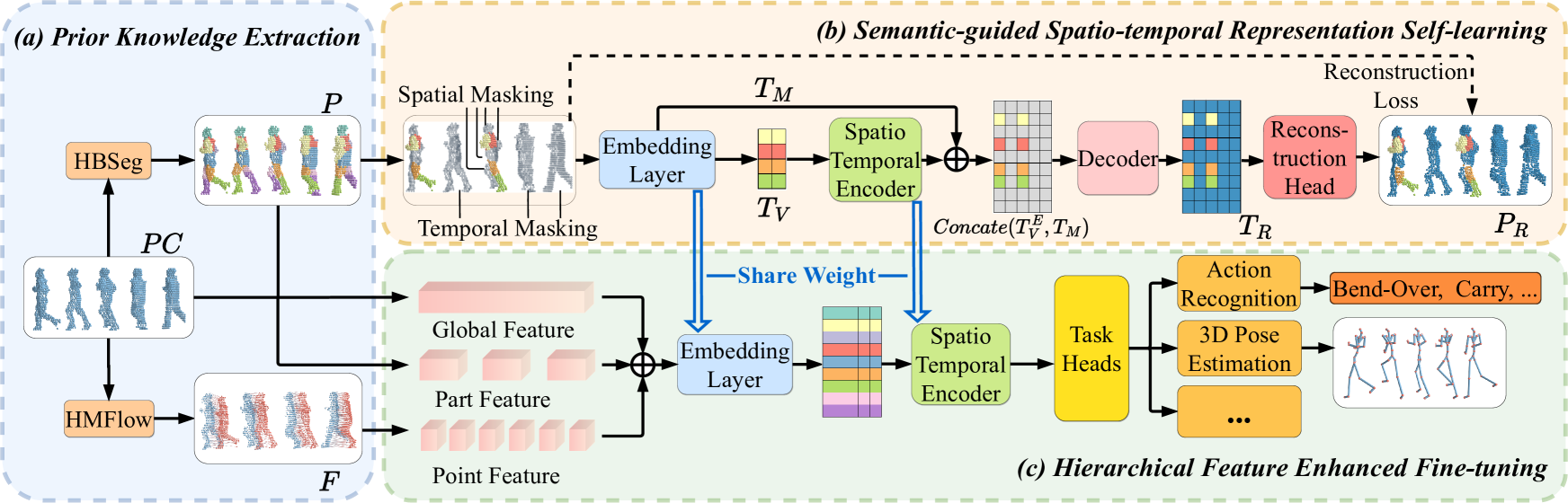
The paper proposes UniPVU-Human, a unified framework for human-centric PVU. It addresses two key questions: 1) what human-related prior knowledge can be extracted, and 2) how can this knowledge enhance human-centric representation learning. The framework utilizes the structural semantics of the human body and motion dynamics to facilitate the acquisition of human-specific features. It includes two novel stages:
-
Semantic-guided spatio-temporal representation self-learning, which incorporates a body-part-based mask prediction mechanism to learn geometric and dynamic representations without annotations.
-
Hierarchical feature enhanced fine-tuning, which integrates and adapts global, part-level, and point-level point cloud features for downstream tasks.
The proposed method, UniPVU-Human, achieves state-of-the-art performance on datasets for human action recognition and pose estimation. Detailed ablation studies are provided to verify the effectiveness of each stage and technical design.
Related Work
The provided text discusses several key aspects of feature learning for point cloud data, with a focus on understanding human-centric point cloud videos.
Point clouds are an important representation for 3D scenes and objects. Existing methods like PointNet, PointNet++, and PointNeXt have developed ways to extract features from point clouds, including capturing local geometric structures. More recent approaches like PCT and PointTransformer leverage attention mechanisms. Some methods extend these to process dynamic point cloud videos.
However, the text notes that these generic approaches lack consideration of human-specific characteristics when processing human point cloud data. This has led to the emergence of new datasets and benchmarks focused on human-centric point cloud understanding, such as LiDARCap, LIP, and HuCenLife.
The text also discusses self-supervised learning methods for point cloud representation learning. While prior work has explored self-supervised approaches for static and dynamic point clouds, the text notes challenges like sparse and incomplete LiDAR data that make these methods unstable. A recent approach using masked point cloud prediction is discussed, but it is noted that this method can impact the semantic and dynamic consistency of the 4D point cloud videos.
Overall, the text highlights the need for feature learning approaches specifically tailored to human-centric point cloud data, which remains an open challenge.
Method
This paper presents a method for extracting and utilizing prior knowledge about human body structure and motion to enhance representations for various human-centric tasks. The key components are:
-
Prior Knowledge Extraction: The authors train two networks - Human Body Segmentation (HBSeg) and Human Motion Flow (HMFlow) - on synthetic data to provide geometric and motion information about human bodies as prior knowledge.
-
Semantic-guided Spatio-temporal Representation Self-learning: This module learns essential human features by masking and predicting body part patches in the spatial and temporal dimensions. It extracts latent representations that capture the structure and dynamics of the human body.
-
Hierarchical Feature Enhanced Fine-tuning: The method integrates global-level, part-level, and point-level features from the pre-trained networks to enable effective and robust human-centric representation learning for downstream tasks.
The paper demonstrates the effectiveness of leveraging prior human-specific knowledge to enhance the generalization and performance of models on various human-centric tasks.
Experiments
The paper presents an extensive evaluation of the authors' proposed method, UniPVU-Human, on open datasets for human action recognition and human pose estimation tasks. Key points:
-
The authors created two synthetic datasets for evaluating body segmentation and motion flow estimation. They also used the HuCenLife and LIP datasets for action recognition and 3D pose estimation, respectively.
-
UniPVU-Human outperformed previous methods on both action recognition and 3D pose estimation tasks, showing its effectiveness at leveraging human body priors and modeling spatio-temporal dynamics.
-
Ablation studies demonstrated the benefits of UniPVU-Human's key design choices, including using human body parts as semantic tokens, self-learning in both spatial and temporal dimensions, and incorporating hierarchical human-related features.
-
The self-learning mechanism in UniPVU-Human was shown to be effective in semi-supervised settings, where the model exhibited smaller performance declines when fine-tuned on reduced training data compared to other methods.
Overall, the results highlight the strong performance and generalization capabilities of the UniPVU-Human approach for human-centric computer vision tasks.
Conclusion
This paper introduces a novel method for understanding human-centric point cloud videos. The researchers leverage the unique characteristics of the human body and human motion to extract intrinsic features from the data. Their unified framework is designed specifically for tasks involving humans. Extensive experiments show the method achieves state-of-the-art performance across various tasks.
Appendix A Overview
The supplementary materials provide detailed information on the generation of the two datasets used to train HMFlow and HBSeg, including corresponding benchmarks and evaluation metrics to facilitate their use and assessment in future research. Additionally, the implementation details of the Tokenizer in both Self-learning and Fine-tuning stages are included. The comparison experiments on HuCenLife [40] have been expanded to include methods tailored for modeling dynamic point cloud videos, demonstrating the superiority of the method in capturing human motion representations. Finally, additional details regarding the size of the UniPVU-Human model and comparisons with others are provided.
Appendix B Human Motion Flow (HMFlow)
The paper describes the implementation details for generating the flow from previous point cloud to the next point cloud. Due to rotation or occlusion, point clouds may flow in and out between consecutive frames, resulting in a lack of temporal correspondence. To address this, the authors create a large-scale synthetic dataset, LiDARFlow-Human, by scanning the SMPL mesh surfaces of consecutive frames using a simulated LiDAR to generate simulated LiDAR point clouds. Each simulated LiDAR point is matched with its nearest SMPL vertex, allowing the use of SMPL vertices as a medium to match simulated LiDAR points between frames. The point-wise motion flow is then obtained by subtracting coordinates. A threshold is set to filter the distance and build bidirectional connections to ensure the accuracy of the matching.
The paper also describes the dataset and evaluation metrics used. The LiDARFlow-Human dataset is contributed to the community for training the Human Motion Flow Estimator (HMFlow) and corresponding benchmarks. The evaluation metrics used include End Point Error (EPE), acc_strict, acc_relax, and outlier, which measure the accuracy of the predicted motion flow compared to the ground truth.
Appendix C Human Body Segmentation (HBSeg)

The paper describes the creation of a synthetic dataset of 1 million LiDAR human point cloud instances, called LiDARPart-Human, to address the lack of 3D human body part segmentation datasets based on LiDAR point clouds. The dataset uses the AMASS dataset for 3D human meshes and simulates LiDAR scans from various perspectives and distances, incorporating random occlusions and noise to reduce the gap between synthetic and real data. The SMPL mesh vertices provide 24 human body part labels, which are simplified to 9 main categories for the LiDAR point cloud. Each LiDAR point is automatically labeled with the nearest vertex's body part label.
The paper also establishes a benchmark on the LiDARPart-Human dataset and will make it publicly available. The evaluation metric for this dataset is the mean Intersection over Union (mIoU), which is the average of the IoUs calculated for each of the 9 human body parts.
Appendix D The Network Design Details for the Tokenizer

The text describes the network design details for the Tokenizer module. During self-learning, the part patches features P are mapped to feature vectors using shared MLPs. The max-pooled features are then concatenated to each feature vector and processed through MLPs to expand the dimension to 384.
During fine-tuning, the same operation is applied to the motion flow features F. The P and F features are then fused through element-wise addition, and a max-pooling layer is applied to derive the part token T.
The design prevents premature leakage of location information of masked tokens to the STEncoder.
Appendix E Supplementary Comparison Experiments on HuCenLife [40]
The paper compares the authors' method, UniPVU-Human, to other methods designed for modeling dynamic point cloud videos. The results in Table 7 show that while the other methods perform better in categories that require modeling motion features, there is still a significant performance gap compared to UniPVU-Human. This confirms the superiority of UniPVU-Human in capturing human motion representations. The paper also compares UniPVU-Human to self-learning approaches based on contrastive learning, and the experimental results demonstrate the superiority of UniPVU-Human's self-learning mechanism.
Appendix F Comparative Analysis of Model Parameter Numbers
The provided text summarizes that transformer-based methods have achieved strong performance in point cloud feature extraction, but typically require large models with high computational demands. In contrast, the UniPVU-Human model maintains a parameter count comparable to ResNet-50, while still achieving better performance. This makes UniPVU-Human a lightweight and effective model well-suited for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Cross-view and Cross-pose Completion for 3D Human Understanding
Matthieu Armando, Salma Galaaoui, Fabien Baradel, Thomas Lucas, Vincent Leroy, Romain Br'egier, Philippe Weinzaepfel, Gr'egory Rogez
0
0
Human perception and understanding is a major domain of computer vision which, like many other vision subdomains recently, stands to gain from the use of large models pre-trained on large datasets. We hypothesize that the most common pre-training strategy of relying on general purpose, object-centric image datasets such as ImageNet, is limited by an important domain shift. On the other hand, collecting domain-specific ground truth such as 2D or 3D labels does not scale well. Therefore, we propose a pre-training approach based on self-supervised learning that works on human-centric data using only images. Our method uses pairs of images of humans: the first is partially masked and the model is trained to reconstruct the masked parts given the visible ones and a second image. It relies on both stereoscopic (cross-view) pairs, and temporal (cross-pose) pairs taken from videos, in order to learn priors about 3D as well as human motion. We pre-train a model for body-centric tasks and one for hand-centric tasks. With a generic transformer architecture, these models outperform existing self-supervised pre-training methods on a wide set of human-centric downstream tasks, and obtain state-of-the-art performance for instance when fine-tuning for model-based and model-free human mesh recovery.
4/19/2024

3D Unsupervised Learning by Distilling 2D Open-Vocabulary Segmentation Models for Autonomous Driving
Boyi Sun, Yuhang Liu, Xingxia Wang, Bin Tian, Long Chen, Fei-Yue Wang
0
0
Point cloud data labeling is considered a time-consuming and expensive task in autonomous driving, whereas unsupervised learning can avoid it by learning point cloud representations from unannotated data. In this paper, we propose UOV, a novel 3D Unsupervised framework assisted by 2D Open-Vocabulary segmentation models. It consists of two stages: In the first stage, we innovatively integrate high-quality textual and image features of 2D open-vocabulary models and propose the Tri-Modal contrastive Pre-training (TMP). In the second stage, spatial mapping between point clouds and images is utilized to generate pseudo-labels, enabling cross-modal knowledge distillation. Besides, we introduce the Approximate Flat Interaction (AFI) to address the noise during alignment and label confusion. To validate the superiority of UOV, extensive experiments are conducted on multiple related datasets. We achieved a record-breaking 47.73% mIoU on the annotation-free point cloud segmentation task in nuScenes, surpassing the previous best model by 10.70% mIoU. Meanwhile, the performance of fine-tuning with 1% data on nuScenes and SemanticKITTI reached a remarkable 51.75% mIoU and 48.14% mIoU, outperforming all previous pre-trained models.
5/27/2024

Semi-supervised Video Semantic Segmentation Using Unreliable Pseudo Labels for PVUW2024
Biao Wu, Diankai Zhang, Si Gao, Chengjian Zheng, Shaoli Liu, Ning Wang
0
0
Pixel-level Scene Understanding is one of the fundamental problems in computer vision, which aims at recognizing object classes, masks and semantics of each pixel in the given image. Compared with image scene parsing, video scene parsing introduces temporal information, which can effectively improve the consistency and accuracy of prediction,because the real-world is actually video-based rather than a static state. In this paper, we adopt semi-supervised video semantic segmentation method based on unreliable pseudo labels. Then, We ensemble the teacher network model with the student network model to generate pseudo labels and retrain the student network. Our method achieves the mIoU scores of 63.71% and 67.83% on development test and final test respectively. Finally, we obtain the 1st place in the Video Scene Parsing in the Wild Challenge at CVPR 2024.
6/4/2024

PKU-DyMVHumans: A Multi-View Video Benchmark for High-Fidelity Dynamic Human Modeling
Xiaoyun Zheng, Liwei Liao, Xufeng Li, Jianbo Jiao, Rongjie Wang, Feng Gao, Shiqi Wang, Ronggang Wang
0
0
High-quality human reconstruction and photo-realistic rendering of a dynamic scene is a long-standing problem in computer vision and graphics. Despite considerable efforts invested in developing various capture systems and reconstruction algorithms, recent advancements still struggle with loose or oversized clothing and overly complex poses. In part, this is due to the challenges of acquiring high-quality human datasets. To facilitate the development of these fields, in this paper, we present PKU-DyMVHumans, a versatile human-centric dataset for high-fidelity reconstruction and rendering of dynamic human scenarios from dense multi-view videos. It comprises 8.2 million frames captured by more than 56 synchronized cameras across diverse scenarios. These sequences comprise 32 human subjects across 45 different scenarios, each with a high-detailed appearance and realistic human motion. Inspired by recent advancements in neural radiance field (NeRF)-based scene representations, we carefully set up an off-the-shelf framework that is easy to provide those state-of-the-art NeRF-based implementations and benchmark on PKU-DyMVHumans dataset. It is paving the way for various applications like fine-grained foreground/background decomposition, high-quality human reconstruction and photo-realistic novel view synthesis of a dynamic scene. Extensive studies are performed on the benchmark, demonstrating new observations and challenges that emerge from using such high-fidelity dynamic data.
4/3/2024