3D Unsupervised Learning by Distilling 2D Open-Vocabulary Segmentation Models for Autonomous Driving
2405.15286
0
0

Abstract
Point cloud data labeling is considered a time-consuming and expensive task in autonomous driving, whereas unsupervised learning can avoid it by learning point cloud representations from unannotated data. In this paper, we propose UOV, a novel 3D Unsupervised framework assisted by 2D Open-Vocabulary segmentation models. It consists of two stages: In the first stage, we innovatively integrate high-quality textual and image features of 2D open-vocabulary models and propose the Tri-Modal contrastive Pre-training (TMP). In the second stage, spatial mapping between point clouds and images is utilized to generate pseudo-labels, enabling cross-modal knowledge distillation. Besides, we introduce the Approximate Flat Interaction (AFI) to address the noise during alignment and label confusion. To validate the superiority of UOV, extensive experiments are conducted on multiple related datasets. We achieved a record-breaking 47.73% mIoU on the annotation-free point cloud segmentation task in nuScenes, surpassing the previous best model by 10.70% mIoU. Meanwhile, the performance of fine-tuning with 1% data on nuScenes and SemanticKITTI reached a remarkable 51.75% mIoU and 48.14% mIoU, outperforming all previous pre-trained models.
Create account to get full access
Overview
• This research paper presents a novel 3D unsupervised learning approach that distills knowledge from 2D open-vocabulary segmentation models to enable more efficient and robust 3D perception for autonomous driving.
• The proposed method, called UNIM-OV3D, leverages pre-trained 2D open-vocabulary segmentation models to generate pseudo-labels for 3D point cloud data, which are then used to train a 3D model in an unsupervised manner.
• The paper also introduces other related techniques, such as 3D Open-Vocabulary Panoptic Segmentation, Applying Unsupervised Semantic Segmentation to High Resolution, UnScene3D, and Segment Any 3D Object, which aim to address various challenges in 3D perception for autonomous driving.
Plain English Explanation
The research paper describes a new way to teach 3D vision models to understand the world without having to manually label vast amounts of 3D data. The key idea is to use 2D image segmentation models that can recognize all sorts of objects, and then use those models to automatically generate labels for 3D point cloud data.
The researchers found that by "distilling" the knowledge from these powerful 2D models into a 3D model, they could train the 3D model to perceive the world in a much more sophisticated way, without needing expensive human labeling. This could be a major breakthrough for autonomous driving, where having robust 3D understanding of the environment is crucial for safe navigation.
The paper also introduces several other related techniques that build on this core idea, tackling challenges like segmenting 3D scenes with open-ended vocabularies, applying unsupervised methods to high-resolution data, and learning to segment any 3D object from just language descriptions. Together, these advances could pave the way for more capable and versatile 3D perception systems for self-driving cars and other robotic applications.
Technical Explanation
The UNIM-OV3D method presented in this paper leverages pre-trained 2D open-vocabulary segmentation models to generate pseudo-labels for 3D point cloud data. Specifically, the 2D models are used to produce semantic segmentation maps for 2D images, which are then projected onto the corresponding 3D point clouds to obtain pseudo-labels.
These pseudo-labels are then used to train a 3D model in an unsupervised manner, allowing the 3D model to learn robust 3D perception capabilities without the need for expensive 3D annotations. The authors demonstrate that this approach outperforms fully-supervised 3D segmentation models on several benchmark datasets.
The paper also introduces several related techniques:
-
3D Open-Vocabulary Panoptic Segmentation: This method extends the open-vocabulary segmentation idea to 3D panoptic segmentation, which aims to simultaneously identify and segment all objects in a 3D scene.
-
Applying Unsupervised Semantic Segmentation to High Resolution: This work explores how unsupervised semantic segmentation techniques can be applied to high-resolution data, which is important for real-world autonomous driving applications.
-
UnScene3D: This method focuses on unsupervised 3D instance segmentation of indoor scenes, which is a crucial capability for robots operating in human environments.
-
Segment Any 3D Object: This technique allows users to segment any 3D object in a scene simply by describing it in natural language, without the need for manual annotation.
Together, these advances represent significant progress towards more capable and versatile 3D perception systems for autonomous driving and other robotic applications.
Critical Analysis
The research presented in this paper is a promising step forward in enabling more efficient and robust 3D perception for autonomous driving. By leveraging pre-trained 2D open-vocabulary segmentation models, the UNIM-OV3D method can generate high-quality pseudo-labels for 3D point cloud data without the need for expensive human annotation.
However, the paper does acknowledge some potential limitations and areas for further research. For example, the performance of the 3D model is still somewhat dependent on the quality of the 2D pseudo-labels, and the method may struggle in cases where the 2D and 3D data distributions differ significantly.
Additionally, the paper does not provide a comprehensive analysis of the computational and memory requirements of the proposed approach, which could be an important consideration for real-world deployment in resource-constrained autonomous vehicles.
Further research could also explore ways to better align the 2D and 3D representations, potentially through techniques like cross-modal distillation or joint training. Investigating the robustness of the approach to domain shifts and noisy 2D inputs could also be valuable.
Overall, the research presented in this paper represents an important step forward in 3D perception for autonomous driving, and the related techniques introduced in the paper provide a solid foundation for continued advancements in this critical area.
Conclusion
This research paper introduces a novel 3D unsupervised learning approach called UNIM-OV3D that leverages pre-trained 2D open-vocabulary segmentation models to enable more efficient and robust 3D perception for autonomous driving. By using these powerful 2D models to automatically generate pseudo-labels for 3D point cloud data, the researchers were able to train a 3D model without the need for expensive manual annotation.
The paper also presents several related techniques, such as 3D open-vocabulary panoptic segmentation, unsupervised semantic segmentation of high-resolution data, and language-guided 3D object segmentation. Together, these advances could significantly improve the capabilities of 3D perception systems for self-driving cars and other robotic applications.
While the research has some limitations and areas for further exploration, the core idea of leveraging 2D open-vocabulary models to bootstrap 3D learning represents an important step forward in the field of autonomous driving. As the technology continues to evolve, we can expect to see even more sophisticated and versatile 3D perception systems that can navigate the complex environments of the real world with greater safety and reliability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Auto-Vocabulary Segmentation for LiDAR Points
Weijie Wei, Osman Ulger, Fatemeh Karimi Najadasl, Theo Gevers, Martin R. Oswald
0
0
Existing perception methods for autonomous driving fall short of recognizing unknown entities not covered in the training data. Open-vocabulary methods offer promising capabilities in detecting any object but are limited by user-specified queries representing target classes. We propose AutoVoc3D, a framework for automatic object class recognition and open-ended segmentation. Evaluation on nuScenes showcases AutoVoc3D's ability to generate precise semantic classes and accurate point-wise segmentation. Moreover, we introduce Text-Point Semantic Similarity, a new metric to assess the semantic similarity between text and point cloud without eliminating novel classes.
6/14/2024

UniM-OV3D: Uni-Modality Open-Vocabulary 3D Scene Understanding with Fine-Grained Feature Representation
Qingdong He, Jinlong Peng, Zhengkai Jiang, Kai Wu, Xiaozhong Ji, Jiangning Zhang, Yabiao Wang, Chengjie Wang, Mingang Chen, Yunsheng Wu
0
0
3D open-vocabulary scene understanding aims to recognize arbitrary novel categories beyond the base label space. However, existing works not only fail to fully utilize all the available modal information in the 3D domain but also lack sufficient granularity in representing the features of each modality. In this paper, we propose a unified multimodal 3D open-vocabulary scene understanding network, namely UniM-OV3D, which aligns point clouds with image, language and depth. To better integrate global and local features of the point clouds, we design a hierarchical point cloud feature extraction module that learns comprehensive fine-grained feature representations. Further, to facilitate the learning of coarse-to-fine point-semantic representations from captions, we propose the utilization of hierarchical 3D caption pairs, capitalizing on geometric constraints across various viewpoints of 3D scenes. Extensive experimental results demonstrate the effectiveness and superiority of our method in open-vocabulary semantic and instance segmentation, which achieves state-of-the-art performance on both indoor and outdoor benchmarks such as ScanNet, ScanNet200, S3IDS and nuScenes. Code is available at https://github.com/hithqd/UniM-OV3D.
4/23/2024
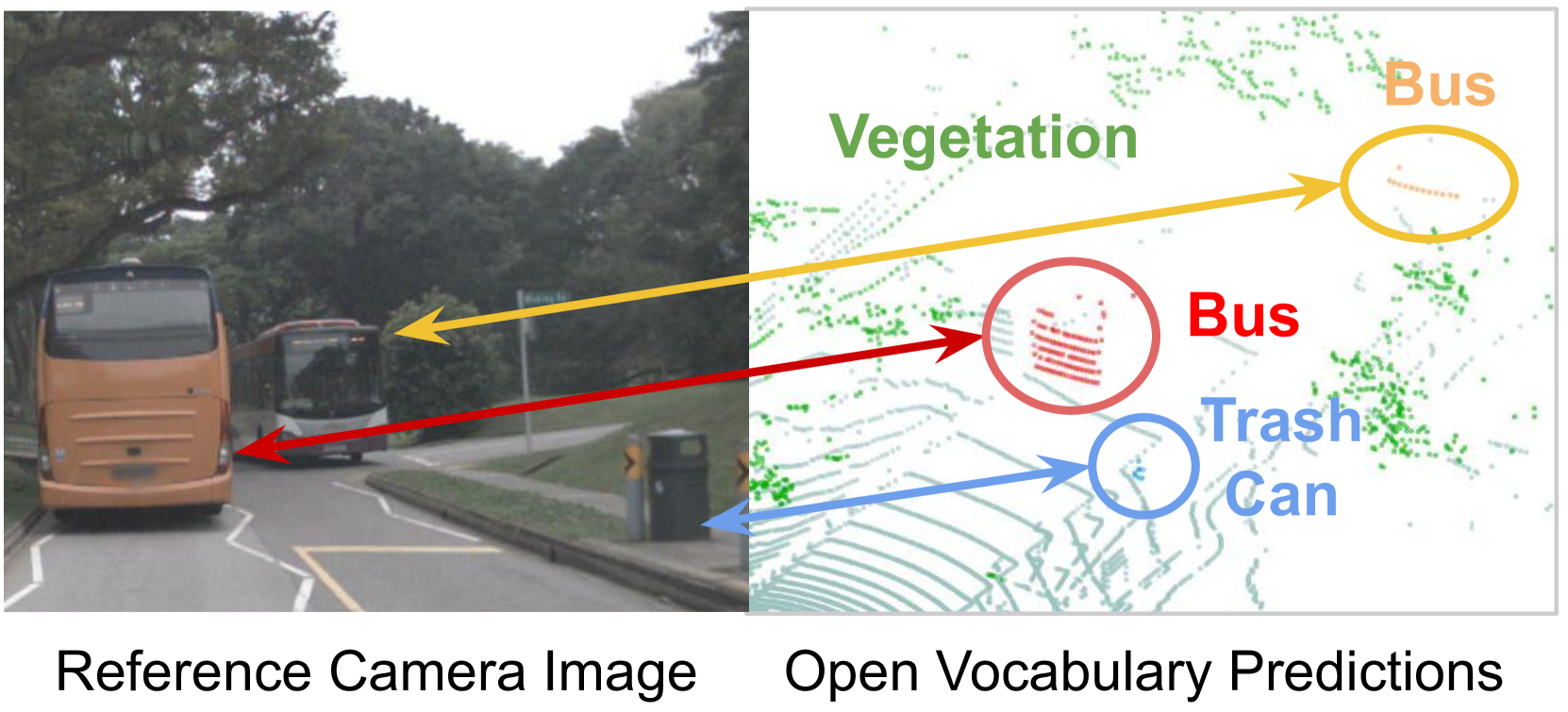
3D Open-Vocabulary Panoptic Segmentation with 2D-3D Vision-Language Distillation
Zihao Xiao, Longlong Jing, Shangxuan Wu, Alex Zihao Zhu, Jingwei Ji, Chiyu Max Jiang, Wei-Chih Hung, Thomas Funkhouser, Weicheng Kuo, Anelia Angelova, Yin Zhou, Shiwei Sheng
0
0
3D panoptic segmentation is a challenging perception task, especially in autonomous driving. It aims to predict both semantic and instance annotations for 3D points in a scene. Although prior 3D panoptic segmentation approaches have achieved great performance on closed-set benchmarks, generalizing these approaches to unseen things and unseen stuff categories remains an open problem. For unseen object categories, 2D open-vocabulary segmentation has achieved promising results that solely rely on frozen CLIP backbones and ensembling multiple classification outputs. However, we find that simply extending these 2D models to 3D does not guarantee good performance due to poor per-mask classification quality, especially for novel stuff categories. In this paper, we propose the first method to tackle 3D open-vocabulary panoptic segmentation. Our model takes advantage of the fusion between learnable LiDAR features and dense frozen vision CLIP features, using a single classification head to make predictions for both base and novel classes. To further improve the classification performance on novel classes and leverage the CLIP model, we propose two novel loss functions: object-level distillation loss and voxel-level distillation loss. Our experiments on the nuScenes and SemanticKITTI datasets show that our method outperforms the strong baseline by a large margin.
4/4/2024
🤷
Applying Unsupervised Semantic Segmentation to High-Resolution UAV Imagery for Enhanced Road Scene Parsing
Zihan Ma, Yongshang Li, Ronggui Ma, Chen Liang
0
0
There are two challenges presented in parsing road scenes from UAV images: the complexity of processing high-resolution images and the dependency on extensive manual annotations required by traditional supervised deep learning methods to train robust and accurate models. In this paper, a novel unsupervised road parsing framework that leverages advancements in vision language models with fundamental computer vision techniques is introduced to address these critical challenges. Our approach initiates with a vision language model that efficiently processes ultra-high resolution images to rapidly identify road regions of interest. Subsequent application of the vision foundation model, SAM, generates masks for these regions without requiring category information. A self-supervised learning network then processes these masked regions to extract feature representations, which are clustered using an unsupervised algorithm that assigns unique IDs to each feature cluster. The masked regions are combined with the corresponding IDs to generate initial pseudo-labels, which initiate an iterative self-training process for regular semantic segmentation. Remarkably, the proposed method achieves a mean Intersection over Union (mIoU) of 89.96% on the development dataset without any manual annotation, demonstrating extraordinary flexibility by surpassing the limitations of human-defined categories, and autonomously acquiring knowledge of new categories from the dataset itself.
4/30/2024