Unified Training of Universal Time Series Forecasting Transformers

0
🏋️
Sign in to get full access
Overview
- Deep learning for time series forecasting has traditionally focused on creating one model per dataset, limiting its ability to leverage large pre-trained models.
- The concept of "universal forecasting" aims to create a single large model capable of addressing diverse forecasting tasks by pre-training on a vast collection of time series datasets.
- However, constructing such a model poses unique challenges specific to time series data, including cross-frequency learning, accommodating multivariate time series, and addressing varying distributional properties.
Plain English Explanation
The paper discusses an approach to time series forecasting that aims to overcome the limitations of traditional deep learning models. Typically, deep learning for time series forecasting has been done by training a separate model for each dataset, which can be inefficient and makes it hard to leverage the power of large, pre-trained models.
The researchers propose the idea of "universal forecasting," where a single, large model is pre-trained on a vast collection of time series datasets. This model would then be capable of addressing a wide range of forecasting tasks, rather than being limited to a specific dataset.
However, creating such a universal model comes with its own challenges when dealing with time series data. These include:
- Cross-frequency learning: Time series data can have different sampling frequencies (e.g., daily, weekly, monthly), and the model needs to be able to handle this.
- Multivariate time series: Time series data can have multiple variables (e.g., temperature, humidity, sales), and the model needs to be able to accommodate an arbitrary number of these.
- Varying distributional properties: Large-scale time series data can have a wide range of statistical properties, and the model needs to be able to adapt to these differences.
To address these challenges, the researchers present a novel enhancement to the traditional time series Transformer architecture, resulting in a model they call "Moirai." This model is trained on a newly introduced dataset called the "Large-scale Open Time Series Archive" (LOTSA), which contains over 27 billion observations across nine different domains.
The key idea is that by pre-training Moirai on this vast and diverse dataset, it can then be used as a "zero-shot" forecaster, meaning it can be applied to new forecasting tasks without any additional training, and still achieve competitive or superior performance compared to models trained specifically for those tasks.
Technical Explanation
The paper presents a novel approach to time series forecasting that aims to overcome the limitations of traditional deep learning models. The researchers propose the concept of "universal forecasting," where a single, large model is pre-trained on a vast collection of time series datasets and is then capable of addressing a wide range of forecasting tasks.
To construct such a universal model, the researchers had to address several unique challenges specific to time series data:
- Cross-frequency learning: Time series data can have different sampling frequencies (e.g., daily, weekly, monthly), and the model needs to be able to handle this. The researchers propose a novel architecture that can learn from time series with varying frequencies.
- Accommodating multivariate time series: Time series data can have multiple variables (e.g., temperature, humidity, sales), and the model needs to be able to accommodate an arbitrary number of these. The researchers' architecture can handle an arbitrary number of input variables.
- Addressing varying distributional properties: Large-scale time series data can have a wide range of statistical properties, and the model needs to be able to adapt to these differences. The researchers' approach specifically addresses this challenge.
The researchers present a novel enhancement to the traditional time series Transformer architecture, resulting in a model they call "Moirai." Moirai is trained on a newly introduced dataset called the "Large-scale Open Time Series Archive" (LOTSA), which contains over 27 billion observations across nine different domains.
The key idea is that by pre-training Moirai on this vast and diverse dataset, it can then be used as a "zero-shot" forecaster, meaning it can be applied to new forecasting tasks without any additional training, and still achieve competitive or superior performance compared to models trained specifically for those tasks.
Critical Analysis
The researchers have presented a compelling approach to time series forecasting that aims to overcome the limitations of traditional deep learning models. By focusing on the unique challenges of time series data, such as cross-frequency learning and accommodating multivariate inputs, the researchers have developed a novel architecture that can serve as a universal forecasting model.
One potential limitation of the research is the reliance on the LOTSA dataset, which, while large and diverse, may not capture the full breadth of real-world time series data. It would be interesting to see how the Moirai model performs on additional datasets, particularly those that may have different statistical properties or come from different domains.
Additionally, the researchers mention that the Moirai model can be used as a "zero-shot" forecaster, meaning it can be applied to new tasks without any additional training. While this is an impressive capability, it would be valuable to understand the limitations of this approach and the types of tasks or datasets where it may not perform as well as models trained specifically for those scenarios.
Overall, the researchers have made a significant contribution to the field of time series forecasting by addressing key challenges and proposing a novel architecture that can serve as a universal model. Further exploration of the model's performance and limitations would help researchers and practitioners better understand the strengths and potential applications of this approach.
Conclusion
The paper presents a novel approach to time series forecasting that aims to overcome the limitations of traditional deep learning models. By introducing the concept of "universal forecasting" and addressing the unique challenges of time series data, the researchers have developed a model called Moirai that can be pre-trained on a vast collection of datasets and then applied as a "zero-shot" forecaster to new tasks.
The key contributions of this research are the architectural enhancements that enable Moirai to handle cross-frequency learning, accommodate multivariate time series, and adapt to varying distributional properties in large-scale time series data. The model's ability to achieve competitive or superior performance on new forecasting tasks without any additional training demonstrates the power of this approach and its potential to significantly impact the field of time series forecasting.
As the researchers continue to explore the capabilities and limitations of the Moirai model, it will be exciting to see how this work can be further developed and applied in real-world scenarios, ultimately leading to more accurate and efficient time series forecasting across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Unified Training of Universal Time Series Forecasting Transformers
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, Doyen Sahoo
Deep learning for time series forecasting has traditionally operated within a one-model-per-dataset framework, limiting its potential to leverage the game-changing impact of large pre-trained models. The concept of universal forecasting, emerging from pre-training on a vast collection of time series datasets, envisions a single Large Time Series Model capable of addressing diverse downstream forecasting tasks. However, constructing such a model poses unique challenges specific to time series data: i) cross-frequency learning, ii) accommodating an arbitrary number of variates for multivariate time series, and iii) addressing the varying distributional properties inherent in large-scale data. To address these challenges, we present novel enhancements to the conventional time series Transformer architecture, resulting in our proposed Masked Encoder-based Universal Time Series Forecasting Transformer (Moirai). Trained on our newly introduced Large-scale Open Time Series Archive (LOTSA) featuring over 27B observations across nine domains, Moirai achieves competitive or superior performance as a zero-shot forecaster when compared to full-shot models. Code, data, and model weights can be found at https://github.com/SalesforceAIResearch/uni2ts.
Read more5/24/2024

0
UNITS: A Unified Multi-Task Time Series Model
Shanghua Gao, Teddy Koker, Owen Queen, Thomas Hartvigsen, Theodoros Tsiligkaridis, Marinka Zitnik
Advances in time series models are driving a shift from conventional deep learning methods to pre-trained foundational models. While pre-trained transformers and reprogrammed text-based LLMs report state-of-the-art results, the best-performing architectures vary significantly across tasks, and models often have limited scope, such as focusing only on time series forecasting. Models that unify predictive and generative time series tasks under a single framework remain challenging to achieve. We introduce UniTS, a multi-task time series model that uses task tokenization to express predictive and generative tasks within a single model. UniTS leverages a modified transformer block designed to obtain universal time series representations. This design induces transferability from a heterogeneous, multi-domain pre-training dataset-often with diverse dynamic patterns, sampling rates, and temporal scales-to many downstream datasets, which can also be diverse in task specifications and data domains. Across 38 datasets spanning human activity sensors, healthcare, engineering, and finance domains, UniTS model performs favorably against 12 forecasting models, 20 classification models, 18 anomaly detection models, and 16 imputation models, including repurposed text-based LLMs. UniTS demonstrates effective few-shot and prompt learning capabilities when evaluated on new data domains and tasks. In the conventional single-task setting, UniTS outperforms strong task-specialized time series models. The source code and datasets are available at https://github.com/mims-harvard/UniTS.
Read more5/31/2024
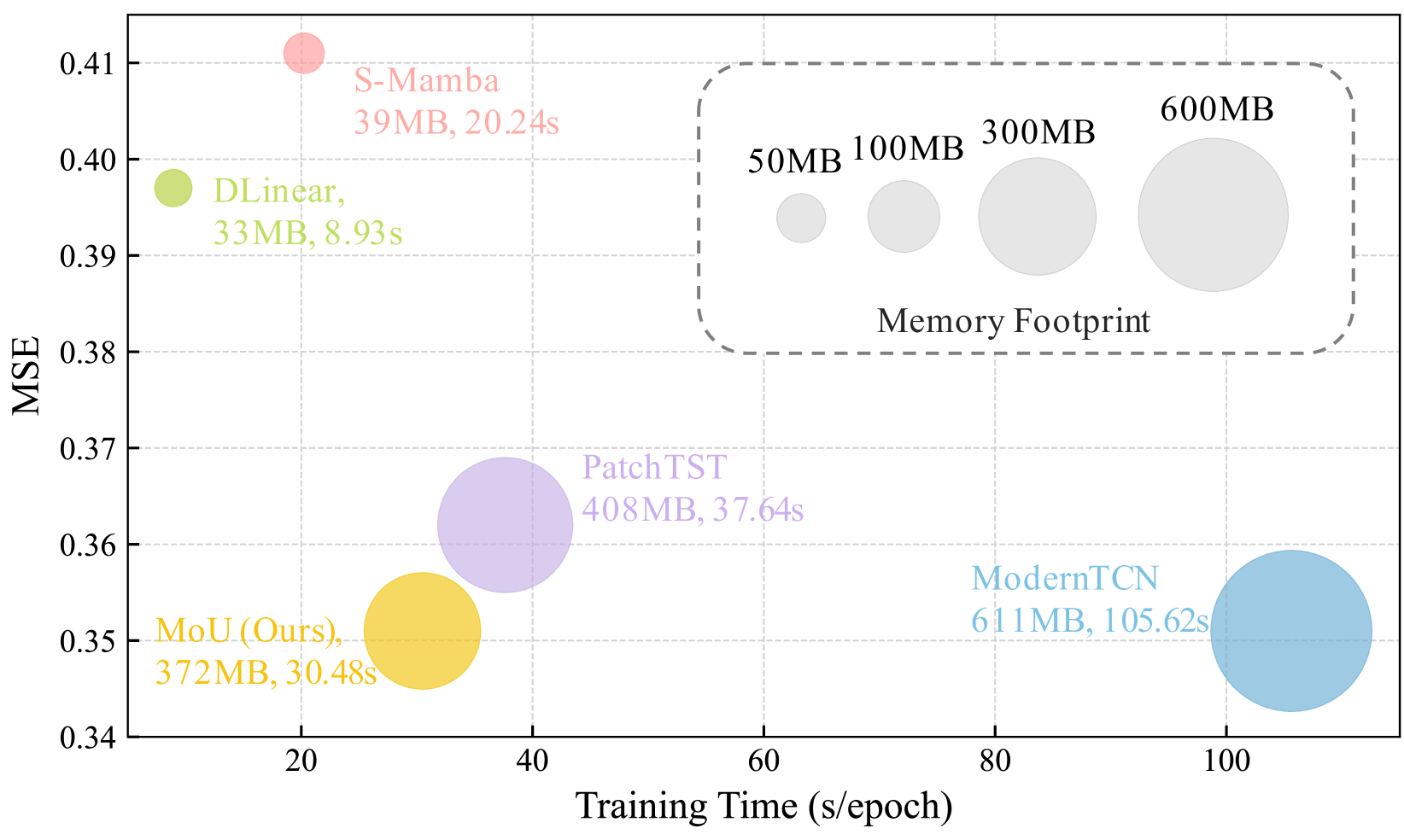
0
Mamba or Transformer for Time Series Forecasting? Mixture of Universals (MoU) Is All You Need
Sijia Peng, Yun Xiong, Yangyong Zhu, Zhiqiang Shen
Time series forecasting requires balancing short-term and long-term dependencies for accurate predictions. Existing methods mainly focus on long-term dependency modeling, neglecting the complexities of short-term dynamics, which may hinder performance. Transformers are superior in modeling long-term dependencies but are criticized for their quadratic computational cost. Mamba provides a near-linear alternative but is reported less effective in time series longterm forecasting due to potential information loss. Current architectures fall short in offering both high efficiency and strong performance for long-term dependency modeling. To address these challenges, we introduce Mixture of Universals (MoU), a versatile model to capture both short-term and long-term dependencies for enhancing performance in time series forecasting. MoU is composed of two novel designs: Mixture of Feature Extractors (MoF), an adaptive method designed to improve time series patch representations for short-term dependency, and Mixture of Architectures (MoA), which hierarchically integrates Mamba, FeedForward, Convolution, and Self-Attention architectures in a specialized order to model long-term dependency from a hybrid perspective. The proposed approach achieves state-of-the-art performance while maintaining relatively low computational costs. Extensive experiments on seven real-world datasets demonstrate the superiority of MoU. Code is available at https://github.com/lunaaa95/mou/.
Read more8/29/2024

0
UniTST: Effectively Modeling Inter-Series and Intra-Series Dependencies for Multivariate Time Series Forecasting
Juncheng Liu, Chenghao Liu, Gerald Woo, Yiwei Wang, Bryan Hooi, Caiming Xiong, Doyen Sahoo
Transformer-based models have emerged as powerful tools for multivariate time series forecasting (MTSF). However, existing Transformer models often fall short of capturing both intricate dependencies across variate and temporal dimensions in MTS data. Some recent models are proposed to separately capture variate and temporal dependencies through either two sequential or parallel attention mechanisms. However, these methods cannot directly and explicitly learn the intricate inter-series and intra-series dependencies. In this work, we first demonstrate that these dependencies are very important as they usually exist in real-world data. To directly model these dependencies, we propose a transformer-based model UniTST containing a unified attention mechanism on the flattened patch tokens. Additionally, we add a dispatcher module which reduces the complexity and makes the model feasible for a potentially large number of variates. Although our proposed model employs a simple architecture, it offers compelling performance as shown in our extensive experiments on several datasets for time series forecasting.
Read more6/10/2024