UniGraph: Learning a Unified Cross-Domain Foundation Model for Text-Attributed Graphs

0
Sign in to get full access
Overview
- UniGraph is a research paper that presents a new approach to learning a cross-domain graph foundation model from natural language.
- The goal is to create a model that can effectively represent and reason about various types of graph-structured data, such as knowledge graphs, social networks, and biological networks.
- The proposed approach involves pre-training a large language model on a diverse corpus of text-attributed graphs, allowing the model to learn rich representations that can be applied to a wide range of graph-related tasks.
Plain English Explanation
UniGraph is a new technique that helps computers understand the relationships between different things, like people, places, and ideas. It starts by teaching a computer model to read and understand a lot of text that describes these relationships. Then, the model can use what it's learned to make sense of graphs, which are visual representations of how things are connected.
The key idea is that by learning from a diverse set of text-based data, the model can develop a rich understanding of how different entities and their connections work. This allows the model to be applied to a wide variety of graph-related tasks, such as knowledge graph completion, social network analysis, and biological network modeling.
By creating a "universal" graph model that can handle many different types of data, the researchers hope to make it easier for computers to understand and work with the complex, interconnected world around us. This could have important applications in fields like natural language processing, knowledge representation, and data analysis.
Technical Explanation
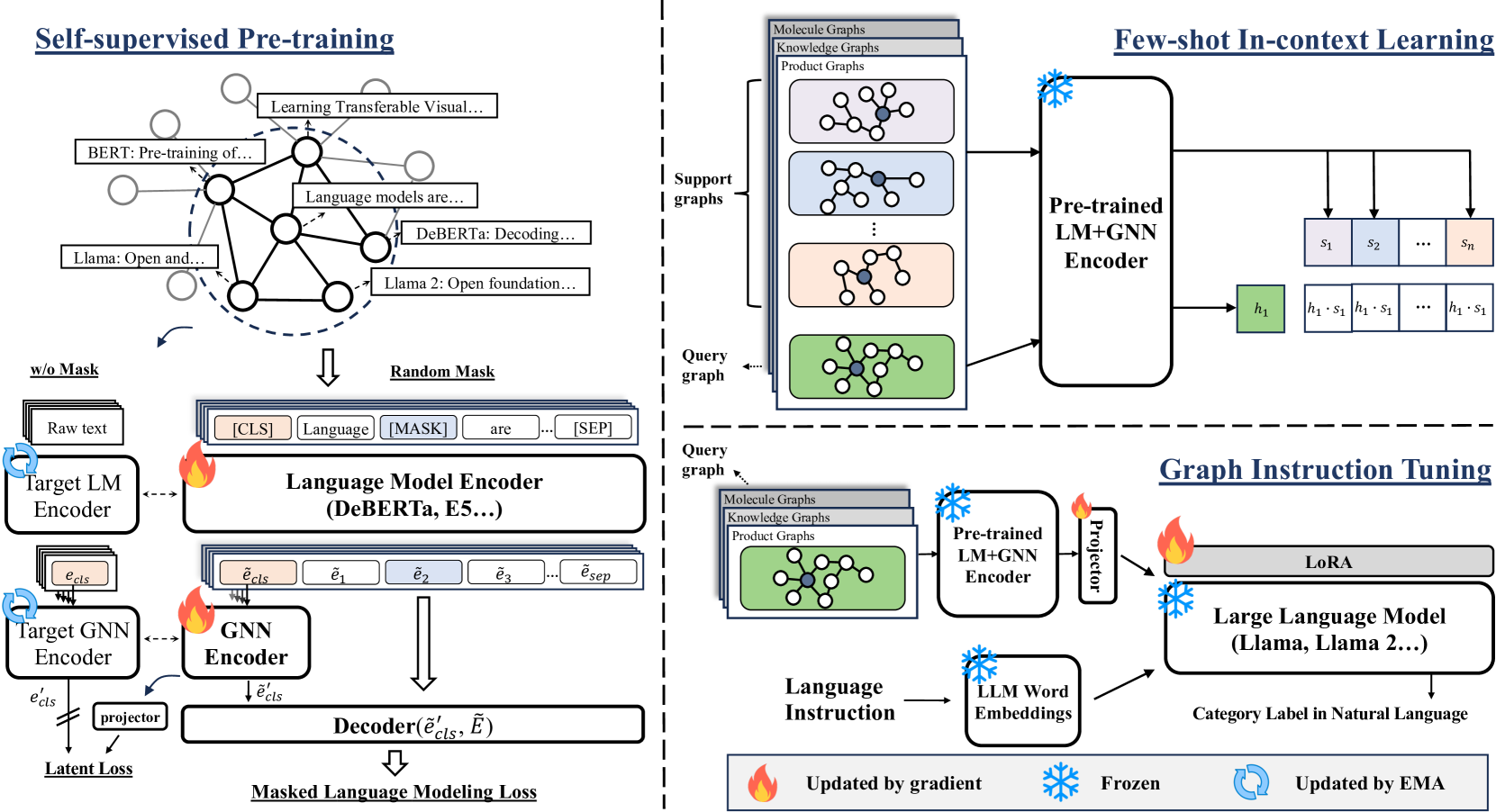
The UniGraph approach involves pre-training a large language model, such as a transformer-based architecture, on a diverse corpus of text-attributed graphs. The model is trained to learn representations that capture the rich semantics and structural information embedded in the graph data, as well as the natural language descriptions associated with the graph entities and relationships.
The key components of the UniGraph framework include:
-
Text-Attributed Graph Pre-Training: The researchers construct a large-scale dataset of text-attributed graphs by combining information from various sources, such as knowledge graphs, social networks, and biological networks. The model is then pre-trained on this diverse dataset to learn general-purpose graph representations.
-
Cross-Domain Transfer Learning: The pre-trained UniGraph model can be fine-tuned on specific graph-related tasks, such as node classification, link prediction, or graph generation, across a variety of domains. This transfer learning approach allows the model to leverage its rich graph understanding to perform well on target tasks, even with limited task-specific data.
-
Multimodal Reasoning: The UniGraph model integrates both textual and structural information, enabling it to engage in multimodal reasoning. This allows the model to understand the semantic context and relational patterns in the graph data, leading to improved performance on tasks that require jointly reasoning about text and graph structures.
The researchers evaluate the UniGraph model on a range of benchmark datasets and tasks, demonstrating its superior performance compared to specialized graph neural network models and language models trained on text-only data. The results highlight the benefits of the proposed approach in learning a cross-domain graph foundation model that can be effectively applied to various graph-related applications.
Critical Analysis
The UniGraph paper presents a promising approach to learning a general-purpose graph foundation model from natural language data. By leveraging the rich semantics and structural information captured in text-attributed graphs, the model is able to develop a versatile understanding of graph-structured data that can be applied across different domains.
One potential limitation of the UniGraph approach is the reliance on the availability and quality of the text-attributed graph dataset used for pre-training. The researchers note that the performance of the model may be sensitive to the coverage and diversity of the training data, which could vary across different application areas.
Additionally, the paper does not provide a detailed analysis of the model's robustness to noisy or incomplete graph data, which is a common challenge in real-world graph-based applications. Further investigation into the model's ability to handle such scenarios would be valuable.
Another area for further research could be exploring the interpretability and explainability of the UniGraph model's representations and decision-making processes. Understanding the internal workings of the model could help researchers and practitioners better understand its strengths, limitations, and potential biases.
Despite these potential areas for improvement, the UniGraph paper represents a significant step forward in the development of cross-domain graph foundation models that can leverage natural language information. The approach has the potential to enable more effective and versatile graph-based reasoning and problem-solving across a wide range of applications.
Conclusion
The UniGraph paper presents a novel approach to learning a cross-domain graph foundation model from natural language data. By pre-training a large language model on a diverse corpus of text-attributed graphs, the researchers have developed a versatile model that can effectively represent and reason about various types of graph-structured data.
The key innovations of the UniGraph framework include its ability to capture rich semantics and structural information through multimodal learning, as well as its potential for cross-domain transfer learning. These capabilities make the UniGraph model a promising tool for a wide range of graph-related applications, such as knowledge representation, social network analysis, and biological network modeling.
While the paper identifies some potential limitations and areas for further research, the UniGraph approach represents an important step forward in the field of graph representation learning. By leveraging natural language data to develop a general-purpose graph foundation model, the researchers have opened up new avenues for computers to understand and navigate the complex, interconnected world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UniGraph: Learning a Unified Cross-Domain Foundation Model for Text-Attributed Graphs
Yufei He, Yuan Sui, Xiaoxin He, Bryan Hooi
Foundation models like ChatGPT and GPT-4 have revolutionized artificial intelligence, exhibiting remarkable abilities to generalize across a wide array of tasks and applications beyond their initial training objectives. However, graph learning has predominantly focused on single-graph models, tailored to specific tasks or datasets, lacking the ability to transfer learned knowledge to different domains. This limitation stems from the inherent complexity and diversity of graph structures, along with the different feature and label spaces specific to graph data. In this paper, we recognize text as an effective unifying medium and employ Text-Attributed Graphs (TAGs) to leverage this potential. We present our UniGraph framework, designed to learn a foundation model for TAGs, which is capable of generalizing to unseen graphs and tasks across diverse domains. Unlike single-graph models that use pre-computed node features of varying dimensions as input, our approach leverages textual features for unifying node representations, even for graphs such as molecular graphs that do not naturally have textual features. We propose a novel cascaded architecture of Language Models (LMs) and Graph Neural Networks (GNNs) as backbone networks. Additionally, we propose the first pre-training algorithm specifically designed for large-scale self-supervised learning on TAGs, based on Masked Graph Modeling. We introduce graph instruction tuning using Large Language Models (LLMs) to enable zero-shot prediction ability. Our comprehensive experiments across various graph learning tasks and domains demonstrate the model's effectiveness in self-supervised representation learning on unseen graphs, few-shot in-context transfer, and zero-shot transfer, even surpassing or matching the performance of GNNs that have undergone supervised training on target datasets.
Read more8/27/2024
0
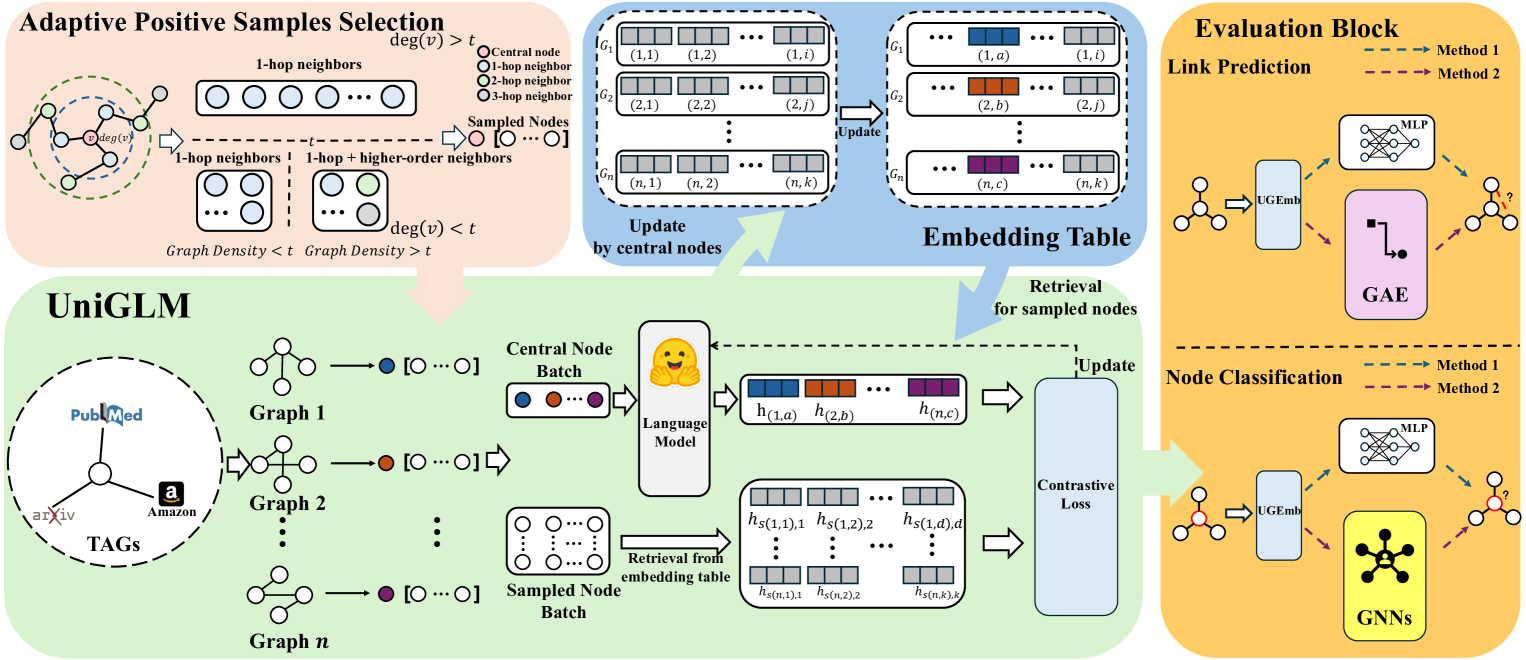
UniGLM: Training One Unified Language Model for Text-Attributed Graphs
Yi Fang, Dongzhe Fan, Sirui Ding, Ninghao Liu, Qiaoyu Tan
Representation learning on text-attributed graphs (TAGs), where nodes are represented by textual descriptions, is crucial for textual and relational knowledge systems and recommendation systems. Currently, state-of-the-art embedding methods for TAGs primarily focus on fine-tuning language models (e.g., BERT) using structure-aware training signals. While effective, these methods are tailored for individual TAG and cannot generalize across various graph scenarios. Given the shared textual space, leveraging multiple TAGs for joint fine-tuning, aligning text and graph structure from different aspects, would be more beneficial. Motivated by this, we introduce a novel Unified Graph Language Model (UniGLM) framework, the first graph embedding model that generalizes well to both in-domain and cross-domain TAGs. Specifically, UniGLM is trained over multiple TAGs with different domains and scales using self-supervised contrastive learning. UniGLM includes an adaptive positive sample selection technique for identifying structurally similar nodes and a lazy contrastive module that is devised to accelerate training by minimizing repetitive encoding calculations. Extensive empirical results across 9 benchmark TAGs demonstrate UniGLM's efficacy against leading embedding baselines in terms of generalization (various downstream tasks and backbones) and transfer learning (in and out of domain scenarios). The code is available at https://github.com/NYUSHCS/UniGLM.
Read more6/19/2024
👨🏫
0
Text-Free Multi-domain Graph Pre-training:Toward Graph Foundation Models
Xingtong Yu, Chang Zhou, Yuan Fang, Xinming Zhang
Given the ubiquity of graph data, it is intriguing to ask: Is it possible to train a graph foundation model on a broad range of graph data across diverse domains? A major hurdle toward this goal lies in the fact that graphs from different domains often exhibit profoundly divergent characteristics. Although there have been some initial efforts in integrating multi-domain graphs for pre-training, they primarily rely on textual descriptions to align the graphs, limiting their application to text-attributed graphs. Moreover, different source domains may conflict or interfere with each other, and their relevance to the target domain can vary significantly. To address these issues, we propose MDGPT, a text free Multi-Domain Graph Pre-Training and adaptation framework designed to exploit multi-domain knowledge for graph learning. First, we propose a set of domain tokens to to align features across source domains for synergistic pre-training. Second, we propose a dual prompts, consisting of a unifying prompt and a mixing prompt, to further adapt the target domain with unified multi-domain knowledge and a tailored mixture of domain-specific knowledge. Finally, we conduct extensive experiments involving six public datasets to evaluate and analyze MDGPT, which outperforms prior art by up to 37.9%.
Read more5/29/2024
💬
0
Distilling Large Language Models for Text-Attributed Graph Learning
Bo Pan, Zheng Zhang, Yifei Zhang, Yuntong Hu, Liang Zhao
Text-Attributed Graphs (TAGs) are graphs of connected textual documents. Graph models can efficiently learn TAGs, but their training heavily relies on human-annotated labels, which are scarce or even unavailable in many applications. Large language models (LLMs) have recently demonstrated remarkable capabilities in few-shot and zero-shot TAG learning, but they suffer from scalability, cost, and privacy issues. Therefore, in this work, we focus on synergizing LLMs and graph models with their complementary strengths by distilling the power of LLMs to a local graph model on TAG learning. To address the inherent gaps between LLMs (generative models for texts) and graph models (discriminative models for graphs), we propose first to let LLMs teach an interpreter with rich textual rationale and then let a student model mimic the interpreter's reasoning without LLMs' textual rationale. Extensive experiments validate the efficacy of our proposed framework.
Read more8/7/2024