UNO-DST: Leveraging Unlabelled Data in Zero-Shot Dialogue State Tracking

0
📊
Sign in to get full access
Overview
- Previous methods for dialogue state tracking (DST) in new domains relied only on transfer learning, ignoring unlabelled data in the target domain.
- This paper transforms zero-shot DST into few-shot DST by using unlabelled data in the target domain through joint and self-training methods.
- The method generates slot types as inverse prompts for the main task, creating slot values during joint training.
- Cycle consistency between these two tasks enables generating and selecting quality samples in unknown target domains for fine-tuning.
- This approach also facilitates automatic label creation, optimizing the training and fine-tuning of DST models.
- The method improves average joint goal accuracy by 8% across all domains in MultiWOZ compared to previous zero-shot approaches.
Plain English Explanation
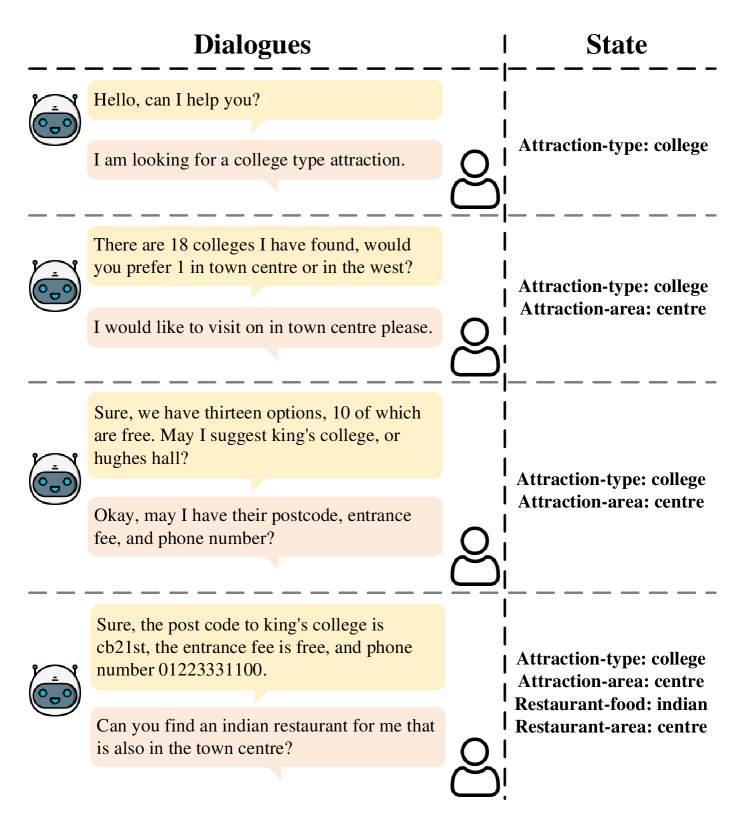
Dialogue state tracking (DST) is a crucial component of conversational AI systems, where the system needs to understand the user's current goal or intent within a conversation. Previous zero-shot DST methods, which aim to work in new domains without any labeled data, only used transfer learning, ignoring the unlabeled data available in the target domain.
This paper proposes a way to utilize that unlabeled data to improve zero-shot DST performance, effectively turning it into a few-shot learning problem. The key idea is to have the system generate plausible slot types (like "food type" or "restaurant name") as guidance for the main DST task, and then use the relationship between the slot types and slot values to identify high-quality samples for fine-tuning.
Imagine you're teaching a child about different types of animals. You might first teach them the broad categories, like "mammals," "birds," and "reptiles." Then you can use that knowledge to help them learn about specific animals within those categories. Similarly, this method first gets the system to understand the types of information it needs to track, and then uses that to learn how to actually track that information in conversations.
By creating this symbiotic relationship between the slot type generation and the main DST task, the system can automatically generate labeled data to improve its performance, without requiring extensive human annotation. This makes the approach much more scalable to new domains compared to previous zero-shot methods.
Technical Explanation
The key innovation in this paper is the use of joint and self-training to leverage unlabeled data in the target domain for zero-shot DST. The architecture consists of two main components:
-
Slot Type Generation: This module takes the conversation context as input and generates plausible slot types that the DST model should track. This acts as an "inverse prompt" for the main DST task.
-
Dialogue State Tracking: The main DST module takes the conversation context and the generated slot types as input, and predicts the corresponding slot values.
During joint training, the two modules are trained together, with the slot type generation helping to create relevant slot values for the DST model. A cycle consistency loss ensures that the generated slot types and predicted slot values are coherent.
This joint training process allows the system to automatically generate high-quality labeled samples, which are then used to fine-tune the DST model in a few-shot manner. The authors show that this approach significantly outperforms previous zero-shot DST methods on the MultiWOZ benchmark, improving average joint goal accuracy by 8%.
Critical Analysis
The paper presents a creative approach to improving zero-shot DST by leveraging unlabeled data in the target domain. The joint training of slot type generation and DST, combined with the cycle consistency loss, is a clever way to bootstrap the learning process and generate high-quality training samples.
However, the paper does not address some potential limitations of the approach. For example, the performance gains may be dependent on the quality and coverage of the slot types generated by the model. If the generated slot types do not match well with the true slot types in the target domain, the approach may not be as effective.
Additionally, the paper does not discuss the scalability of the approach to larger and more diverse target domains. The experiments are conducted on the MultiWOZ dataset, which, while a popular benchmark, may not capture the full complexity of real-world conversational domains.
Further research could explore ways to make the slot type generation more robust and adaptive, perhaps by incorporating external knowledge sources or by allowing the model to refine the slot types during the fine-tuning process. Evaluating the approach on a wider range of target domains would also help to better understand its limitations and potential for real-world application.
Conclusion
This paper presents an innovative approach to transforming zero-shot dialogue state tracking into a few-shot learning problem by utilizing unlabeled data in the target domain. The key idea of jointly training slot type generation and the main DST task, with a cycle consistency loss, allows the system to automatically create high-quality labeled samples for fine-tuning.
This method represents a significant advancement over previous zero-shot DST techniques, improving average joint goal accuracy by 8% on the MultiWOZ benchmark. By leveraging unlabeled data and automating the label creation process, the approach has the potential to make DST systems more scalable and adaptable to new domains, a crucial step towards more robust and versatile conversational AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
UNO-DST: Leveraging Unlabelled Data in Zero-Shot Dialogue State Tracking
Chuang Li, Yan Zhang, Min-Yen Kan, Haizhou Li
Previous zero-shot dialogue state tracking (DST) methods only apply transfer learning, ignoring unlabelled data in the target domain. We transform zero-shot DST into few-shot DST by utilising such unlabelled data via joint and self-training methods. Our method incorporates auxiliary tasks that generate slot types as inverse prompts for main tasks, creating slot values during joint training. Cycle consistency between these two tasks enables the generation and selection of quality samples in unknown target domains for subsequent fine-tuning. This approach also facilitates automatic label creation, thereby optimizing the training and fine-tuning of DST models. We demonstrate this method's effectiveness on general language models in zero-shot scenarios, improving average joint goal accuracy by 8% across all domains in MultiWOZ.
Read more4/4/2024

0
A Zero-Shot Open-Vocabulary Pipeline for Dialogue Understanding
Abdulfattah Safa, Gozde Gul c{S}ahin
Dialogue State Tracking (DST) is crucial for understanding user needs and executing appro- priate system actions in task-oriented dialogues. Majority of existing DST methods are designed to work within predefined ontologies and as- sume the availability of gold domain labels, struggling with adapting to new slots values. While Large Language Models (LLMs)-based systems show promising zero-shot DST perfor- mance, they either require extensive computa- tional resources or they underperform existing fully-trained systems, limiting their practical- ity. To address these limitations, we propose a zero-shot, open-vocabulary system that in- tegrates domain classification and DST in a single pipeline. Our approach includes refor- mulating DST as a question-answering task for less capable models and employing self- refining prompts for more adaptable ones. Our system does not rely on fixed slot values de- fined in the ontology allowing the system to adapt dynamically. We compare our approach with existing SOTA, and show that it provides up to 20% better Joint Goal Accuracy (JGA) over previous methods on datasets like Multi- WOZ 2.1, with up to 90% fewer requests to the LLM API.
Read more9/25/2024
📊
0
Leveraging Diverse Data Generation for Adaptable Zero-Shot Dialogue State Tracking
James D. Finch, Jinho D. Choi
We demonstrate substantial performance gains in zero-shot dialogue state tracking (DST) by enhancing training data diversity through synthetic data generation. Existing DST datasets are severely limited in the number of application domains and slot types they cover due to the high costs of data collection, restricting their adaptability to new domains. This work addresses this challenge with a novel, fully automatic data generation approach that creates synthetic zero-shot DST datasets. Distinguished from previous methods, our approach can generate dialogues across a massive range of application domains, complete with silver-standard dialogue state annotations and slot descriptions. This technique is used to create the D0T dataset for training zero-shot DST models, encompassing an unprecedented 1,000+ domains. Experiments on the MultiWOZ benchmark show that training models on diverse synthetic data improves Joint Goal Accuracy by 6.7%, achieving results competitive with models 13.5 times larger than ours.
Read more6/14/2024
0
Zero-Shot Cross-Domain Dialogue State Tracking via Dual Low-Rank Adaptation
Xiang Luo, Zhiwen Tang, Jin Wang, Xuejie Zhang
Zero-shot dialogue state tracking (DST) seeks to enable dialogue systems to transition to unfamiliar domains without manual annotation or extensive retraining. Prior research has approached this objective by embedding prompts into language models (LMs). Common methodologies include integrating prompts at the input layer or introducing learnable variables at each transformer layer. Nonetheless, each strategy exhibits inherent limitations. Prompts integrated at the input layer risk underutilization, with their impact potentially diminishing across successive transformer layers. Conversely, the addition of learnable variables to each layer can complicate the training process and increase inference latency. To tackle the issues mentioned above, this paper proposes Dual Low-Rank Adaptation (DualLoRA), a plug-and-play architecture designed for zero-shot DST. DualLoRA incorporates two distinct Low-Rank Adaptation (LoRA) components, targeting both dialogue context processing and prompt optimization, to ensure the comprehensive influence of prompts throughout the transformer model layers. This is achieved without incurring additional inference latency, showcasing an efficient integration into existing architectures. Through rigorous evaluation on the MultiWOZ and SGD datasets, DualLoRA demonstrates notable improvements across multiple domains, outperforming traditional baseline methods in zero-shot settings. Our code is accessible at: url{https://github.com/suntea233/DualLoRA}.
Read more8/1/2024