Unsupervised Gait Recognition with Selective Fusion

0
🤷
Sign in to get full access
Overview
- Previous gait recognition methods required labeled datasets, which are time-consuming to create
- Using a pre-trained model on a new dataset without fine-tuning leads to significant performance degradation
- To address this, the paper introduces a new task: Unsupervised Gait Recognition (UGR)
- The paper proposes a cluster-based baseline for UGR using cluster-level contrastive learning
- However, the paper identifies two key challenges in this task:
- Sequences of the same person in different clothes tend to cluster separately due to appearance changes
- Sequences taken from 0 and 180 degree views lack walking postures and do not cluster with other views
Plain English Explanation
Gait recognition is the process of identifying individuals based on the way they walk. Previous methods for gait recognition required labeled datasets, meaning someone had to manually go through and label each person in the dataset. This labeling process can be very time-consuming and tedious.
An alternative approach is to use a pre-trained model that has already been trained on a large dataset. However, if you try to use this pre-trained model on a new, unlabeled dataset, the performance can significantly degrade. To solve this problem, the researchers in this paper introduce a new task called Unsupervised Gait Recognition (UGR).
The core idea behind UGR is to develop a model that can learn to recognize people's gaits without needing any labeled data. The paper proposes a cluster-based baseline that uses a technique called cluster-level contrastive learning.
However, the researchers identified two key challenges with this approach:
-
Clothing changes: When the same person wears different clothes, the model tends to cluster their sequences separately, even though it's the same person. This is because the appearance changes a lot between different outfits.
-
Front/back views: Sequences of a person walking from the front or back (0 and 180 degree views) don't have the same walking postures as side views, so they don't cluster well with the other sequences.
To address these challenges, the paper proposes a "Selective Fusion" method. This includes:
- Selective Cluster Fusion (SCF): Merging the clusters of the same person wearing different clothes by updating the cluster-level memory bank.
- Selective Sample Fusion (SSF): Gradually merging the front/back view sequences with the other views using a curriculum learning approach.
The researchers show that this Selective Fusion method can significantly improve the accuracy of the gait recognition model, particularly in situations with clothing changes and front/back views.
Technical Explanation
The paper introduces a new task called Unsupervised Gait Recognition (UGR), which aims to train a gait recognition model without using any labeled data. To solve this task, the researchers propose a cluster-based baseline that uses cluster-level contrastive learning.
The key steps of the proposed method are:
- Feature Extraction: The model first extracts visual features from the input gait sequences using a pre-trained backbone network like GaitPoint.
- Clustering: The extracted features are then clustered using a standard clustering algorithm like K-Means.
- Contrastive Learning: The model performs cluster-level contrastive learning, where it tries to pull together the features of samples in the same cluster and push apart the features of samples in different clusters.
However, the researchers find that this basic approach faces two main challenges:
- Clothing Variations: When the same person wears different clothes, their gait sequences tend to be clustered separately due to the significant appearance changes.
- Front/Back Views: Gait sequences captured from the front (0 degree) or back (180 degree) views lack distinctive walking postures, and do not cluster well with sequences from other views.
To address these challenges, the paper proposes a "Selective Fusion" method:
- Selective Cluster Fusion (SCF): The model updates the cluster-level memory bank with a multi-cluster update strategy to merge the clusters of the same person wearing different clothes.
- Selective Sample Fusion (SSF): The model gradually merges the front/back view sequences with the other views using a curriculum learning approach.
The effectiveness of the proposed Selective Fusion method is demonstrated through extensive experiments, showing significant improvements in rank-1 accuracy for gait recognition in the presence of clothing changes and front/back view variations.
Critical Analysis
The paper presents a novel and practical approach to the problem of unsupervised gait recognition, which is an important step towards more practical and deployable gait recognition systems. The identification of the key challenges around clothing variations and front/back view differences is a valuable contribution, as these are real-world issues that need to be addressed.
The proposed Selective Fusion method appears to be a effective solution to these challenges, as demonstrated by the improved performance on the evaluated datasets. The use of curriculum learning in the SSF component is a particularly clever idea, as it allows the model to gradually learn to handle the more difficult front/back view samples.
That said, there are a few potential limitations and areas for further research that could be explored:
- Generalizability: While the paper shows strong results on the evaluated datasets, it would be important to test the method on a wider range of gait recognition datasets to assess its generalizability.
- Computational Efficiency: The Selective Fusion method adds additional computational complexity to the training process. It would be worth investigating ways to streamline the approach without sacrificing performance.
- Interpretability: The paper does not provide much insight into why the Selective Fusion method is effective at addressing the identified challenges. A deeper analysis of the internal workings of the approach could lead to further improvements.
Overall, this paper presents a compelling solution to an important problem in gait recognition, and the proposed ideas could have significant impact on the field. The critical analysis highlights areas for potential future research to further advance the state of the art in unsupervised gait recognition.
Conclusion
This paper introduces a new task called Unsupervised Gait Recognition (UGR), which aims to train gait recognition models without the need for labeled datasets. To solve this task, the researchers propose a cluster-based baseline with cluster-level contrastive learning, and identify two key challenges: clothing variations and front/back view differences.
To address these challenges, the paper introduces a "Selective Fusion" method, which includes Selective Cluster Fusion (SCF) to merge clusters of the same person in different clothes, and Selective Sample Fusion (SSF) to gradually integrate front/back view sequences. Extensive experiments show that this Selective Fusion approach significantly improves the rank-1 accuracy of the gait recognition model in these challenging conditions.
The ideas presented in this paper represent an important step forward for gait recognition systems, potentially enabling their deployment in real-world applications where labeled data is scarce. The critical analysis suggests several avenues for future research to further enhance the generalizability, efficiency, and interpretability of the proposed techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Unsupervised Gait Recognition with Selective Fusion
Xuqian Ren, Shaopeng Yang, Saihui Hou, Chunshui Cao, Xu Liu, Yongzhen Huang
Previous gait recognition methods primarily trained on labeled datasets, which require painful labeling effort. However, using a pre-trained model on a new dataset without fine-tuning can lead to significant performance degradation. So to make the pre-trained gait recognition model able to be fine-tuned on unlabeled datasets, we propose a new task: Unsupervised Gait Recognition (UGR). We introduce a new cluster-based baseline to solve UGR with cluster-level contrastive learning. But we further find more challenges this task meets. First, sequences of the same person in different clothes tend to cluster separately due to the significant appearance changes. Second, sequences taken from 0{deg} and 180{deg} views lack walking postures and do not cluster with sequences taken from other views. To address these challenges, we propose a Selective Fusion method, which includes Selective Cluster Fusion (SCF) and Selective Sample Fusion (SSF). With SCF, we merge matched clusters of the same person wearing different clothes by updating the cluster-level memory bank with a multi-cluster update strategy. And in SSF, we merge sequences taken from front/back views gradually with curriculum learning. Extensive experiments show the effectiveness of our method in improving the rank-1 accuracy in walking with different coats condition and front/back views conditions.
Read more4/23/2024

0
GaitMA: Pose-guided Multi-modal Feature Fusion for Gait Recognition
Fanxu Min, Shaoxiang Guo, Fan Hao, Junyu Dong
Gait recognition is a biometric technology that recognizes the identity of humans through their walking patterns. Existing appearance-based methods utilize CNN or Transformer to extract spatial and temporal features from silhouettes, while model-based methods employ GCN to focus on the special topological structure of skeleton points. However, the quality of silhouettes is limited by complex occlusions, and skeletons lack dense semantic features of the human body. To tackle these problems, we propose a novel gait recognition framework, dubbed Gait Multi-model Aggregation Network (GaitMA), which effectively combines two modalities to obtain a more robust and comprehensive gait representation for recognition. First, skeletons are represented by joint/limb-based heatmaps, and features from silhouettes and skeletons are respectively extracted using two CNN-based feature extractors. Second, a co-attention alignment module is proposed to align the features by element-wise attention. Finally, we propose a mutual learning module, which achieves feature fusion through cross-attention, Wasserstein loss is further introduced to ensure the effective fusion of two modalities. Extensive experimental results demonstrate the superiority of our model on Gait3D, OU-MVLP, and CASIA-B.
Read more7/23/2024
✨
0
Progressive Feature Learning for Realistic Cloth-Changing Gait Recognition
Xuqian Ren, Saihui Hou, Chunshui Cao, Xu Liu, Yongzhen Huang
Gait recognition is instrumental in crime prevention and social security, for it can be conducted at a long distance to figure out the identity of persons. However, existing datasets and methods cannot satisfactorily deal with the most challenging cloth-changing problem in practice. Specifically, the practical gait models are usually trained on automatically labeled data, in which the sequences' views and cloth conditions of each person have some restrictions. To be concrete, the cross-view sub-dataset only has normal walking condition without cloth-changing, while the cross-cloth sub-dataset has cloth-changing sequences but only in front views. As a result, the cloth-changing accuracy cannot meet practical requirements. In this work, we formulate the problem as Realistic Cloth-Changing Gait Recognition (abbreviated as RCC-GR) and we construct two benchmarks: CASIA-BN-RCC and OUMVLP-RCC, to simulate the above setting. Furthermore, we propose a new framework called Progressive Feature Learning that can be applied with off-the-shelf backbones to improve their performance in RCC-GR. Specifically, in our framework, we design Progressive Mapping and Progressive Uncertainty to extract cross-view features and then extract cross-cloth features on the basis. In this way, the feature from the cross-view sub-dataset can first dominate the feature space and relieve the uneven distribution caused by the adverse effect from the cross-cloth sub-dataset. The experiments on our benchmarks show that our framework can effectively improve recognition performance, especially in the cloth-changing conditions.
Read more4/23/2024
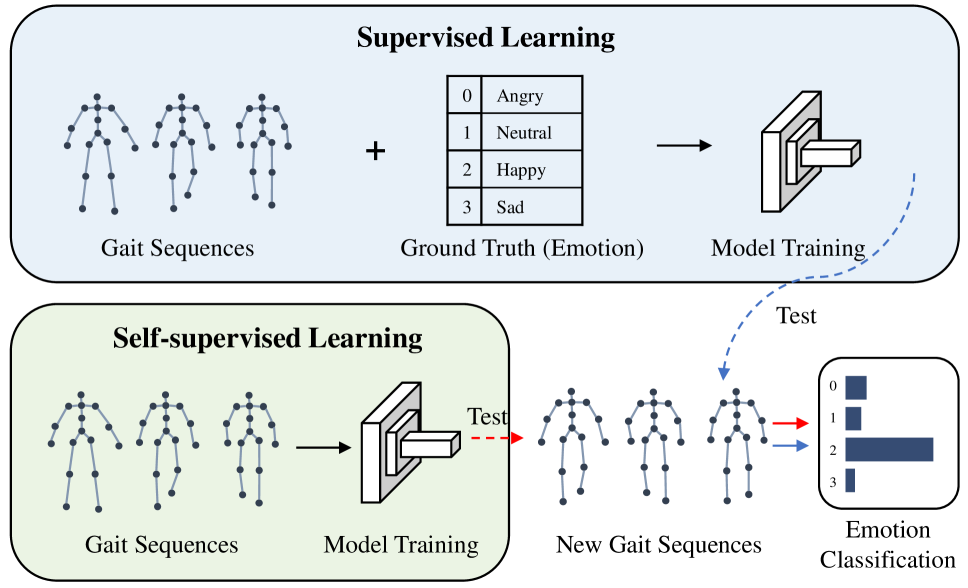
0
Self-supervised Gait-based Emotion Representation Learning from Selective Strongly Augmented Skeleton Sequences
Cheng Song, Lu Lu, Zhen Ke, Long Gao, Shuai Ding
Emotion recognition is an important part of affective computing. Extracting emotional cues from human gaits yields benefits such as natural interaction, a nonintrusive nature, and remote detection. Recently, the introduction of self-supervised learning techniques offers a practical solution to the issues arising from the scarcity of labeled data in the field of gait-based emotion recognition. However, due to the limited diversity of gaits and the incompleteness of feature representations for skeletons, the existing contrastive learning methods are usually inefficient for the acquisition of gait emotions. In this paper, we propose a contrastive learning framework utilizing selective strong augmentation (SSA) for self-supervised gait-based emotion representation, which aims to derive effective representations from limited labeled gait data. First, we propose an SSA method for the gait emotion recognition task, which includes upper body jitter and random spatiotemporal mask. The goal of SSA is to generate more diverse and targeted positive samples and prompt the model to learn more distinctive and robust feature representations. Then, we design a complementary feature fusion network (CFFN) that facilitates the integration of cross-domain information to acquire topological structural and global adaptive features. Finally, we implement the distributional divergence minimization loss to supervise the representation learning of the generally and strongly augmented queries. Our approach is validated on the Emotion-Gait (E-Gait) and Emilya datasets and outperforms the state-of-the-art methods under different evaluation protocols.
Read more5/9/2024