Unsupervised Latent Stain Adaption for Digital Pathology

0

Sign in to get full access
Overview
- Unsupervised method for adapting digital pathology image stains
- Leverages latent representation learning to align stain distributions across datasets
- Enables cross-dataset transfer learning for tasks like segmentation and classification
Plain English Explanation
This paper proposes an unsupervised method for adapting the appearance of digital pathology images, known as "stains," across different datasets. Stains are a crucial aspect of pathology imaging, as they highlight specific tissue structures and properties that aid in disease diagnosis and analysis. However, stain appearance can vary significantly between imaging devices, preparation protocols, and other factors, making it challenging to apply machine learning models trained on one dataset to new data.
The key idea behind this work is to learn a latent representation of the image stains that captures the essential features while abstracting away the specific stain characteristics. By aligning these latent representations across datasets, the method can effectively "translate" the stains, enabling the transfer of machine learning models trained on one set of stained images to be applied to new data with different stain appearances. This can be particularly valuable for low-resource settings where obtaining labeled data for tasks like tissue segmentation or disease classification can be challenging.
The authors demonstrate the effectiveness of their approach through experiments on several digital pathology datasets, showing improved performance on cross-dataset transfer learning tasks compared to previous methods. This work represents an important step towards making machine learning more robust and accessible for digital pathology, a field that is increasingly reliant on automated image analysis to support clinical decision-making.
Technical Explanation
The proposed method, called "Unsupervised Latent Stain Adaption" (ULSA), consists of two main components: a stain normalization module and a task-specific model. The stain normalization module learns a latent representation of the stain characteristics in an unsupervised manner, using adversarial training to align the stain distributions across datasets. This latent representation is then used to transform the input images to a common stain appearance, enabling the task-specific model (e.g., for segmentation or classification) to be trained on the normalized data.
The stain normalization module is based on a Variational Autoencoder (VAE) architecture, where the encoder learns a low-dimensional latent representation of the input image, and the decoder reconstructs the image from this latent code. An adversarial discriminator is used to ensure that the latent representations from different datasets have similar distributions, effectively aligning the stain characteristics.
The task-specific model is trained in a semi-supervised manner, leveraging both the normalized images from the stain normalization module and any available labeled data for the target task. This allows the model to learn robust features that are invariant to stain variations, enabling effective cross-dataset transfer learning.
The authors evaluate their approach on several digital pathology datasets, including tasks such as nuclei segmentation and breast cancer classification. They demonstrate significant performance improvements over previous unsupervised and semi-supervised stain adaptation methods, highlighting the benefits of their latent representation-based approach.
Critical Analysis
The paper presents a well-designed and thorough study, with clear experimental setups and comprehensive evaluations. One potential limitation is the reliance on adversarial training, which can be notoriously difficult to stabilize and optimize. The authors do not provide a detailed analysis of the training dynamics and convergence of the adversarial components, which could be an area for further investigation.
Additionally, while the authors demonstrate the effectiveness of their approach on several datasets, it would be valuable to see how the method performs on a broader range of pathology datasets, especially those with more substantial stain variations or more challenging tasks. This could help assess the generalizability and robustness of the proposed technique.
Another area for further research could be the integration of the stain normalization module with more advanced task-specific models, such as those leveraging self-supervised learning or weakly-supervised techniques. Exploring these avenues could lead to even more powerful and versatile solutions for cross-dataset transfer learning in digital pathology.
Conclusion
The "Unsupervised Latent Stain Adaption" method presented in this paper represents a significant advancement in addressing the challenge of stain variation in digital pathology imaging. By learning a latent representation of stain characteristics and aligning these representations across datasets, the proposed approach enables effective cross-dataset transfer learning for crucial tasks like tissue segmentation and disease classification.
This work has the potential to greatly improve the accessibility and robustness of machine learning models in digital pathology, particularly in low-resource settings where labeled data may be scarce. The authors have demonstrated the efficacy of their method, and further research in this direction could lead to even more powerful and versatile solutions for leveraging machine learning to support clinical decision-making in the field of digital pathology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unsupervised Latent Stain Adaption for Digital Pathology
Daniel Reisenbuchler, Lucas Luttner, Nadine S. Schaadt, Friedrich Feuerhake, Dorit Merhof
In computational pathology, deep learning (DL) models for tasks such as segmentation or tissue classification are known to suffer from domain shifts due to different staining techniques. Stain adaptation aims to reduce the generalization error between different stains by training a model on source stains that generalizes to target stains. Despite the abundance of target stain data, a key challenge is the lack of annotations. To address this, we propose a joint training between artificially labeled and unlabeled data including all available stained images called Unsupervised Latent Stain Adaptation (ULSA). Our method uses stain translation to enrich labeled source images with synthetic target images in order to increase the supervised signals. Moreover, we leverage unlabeled target stain images using stain-invariant feature consistency learning. With ULSA we present a semi-supervised strategy for efficient stain adaptation without access to annotated target stain data. Remarkably, ULSA is task agnostic in patch-level analysis for whole slide images (WSIs). Through extensive evaluation on external datasets, we demonstrate that ULSA achieves state-of-the-art (SOTA) performance in kidney tissue segmentation and breast cancer classification across a spectrum of staining variations. Our findings suggest that ULSA is an important framework for stain adaptation in computational pathology.
Read more7/4/2024
0
Achieving Reliable and Fair Skin Lesion Diagnosis via Unsupervised Domain Adaptation
Janet Wang, Yunbei Zhang, Zhengming Ding, Jihun Hamm
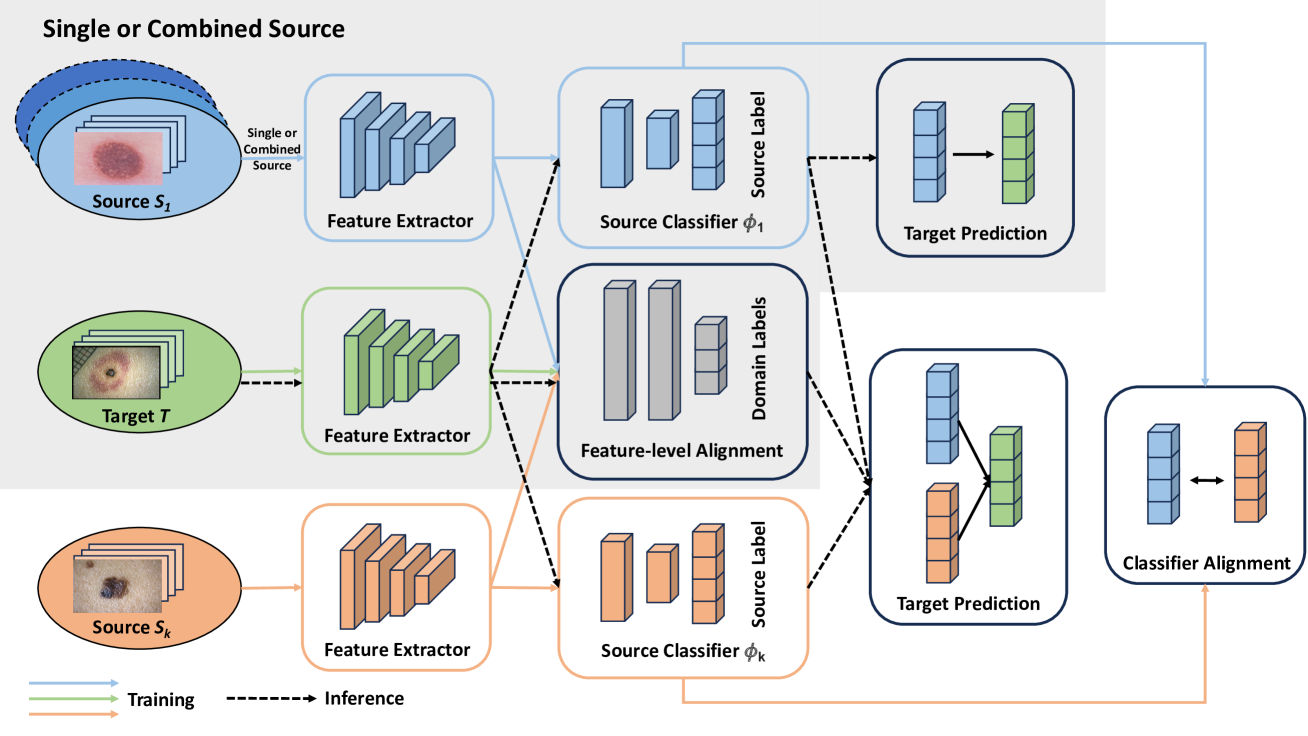
The development of reliable and fair diagnostic systems is often constrained by the scarcity of labeled data. To address this challenge, our work explores the feasibility of unsupervised domain adaptation (UDA) to integrate large external datasets for developing reliable classifiers. The adoption of UDA with multiple sources can simultaneously enrich the training set and bridge the domain gap between different skin lesion datasets, which vary due to distinct acquisition protocols. Particularly, UDA shows practical promise for improving diagnostic reliability when training with a custom skin lesion dataset, where only limited labeled data are available from the target domain. In this study, we investigate three UDA training schemes based on source data utilization: single-source, combined-source, and multi-source UDA. Our findings demonstrate the effectiveness of applying UDA on multiple sources for binary and multi-class classification. A strong correlation between test error and label shift in multi-class tasks has been observed in the experiment. Crucially, our study shows that UDA can effectively mitigate bias against minority groups and enhance fairness in diagnostic systems, while maintaining superior classification performance. This is achieved even without directly implementing fairness-focused techniques. This success is potentially attributed to the increased and well-adapted demographic information obtained from multiple sources.
Read more4/17/2024

0
Source-Free Domain Adaptation of Weakly-Supervised Object Localization Models for Histology
Alexis Guichemerre, Soufiane Belharbi, Tsiry Mayet, Shakeeb Murtaza, Pourya Shamsolmoali, Luke McCaffrey, Eric Granger
Given the emergence of deep learning, digital pathology has gained popularity for cancer diagnosis based on histology images. Deep weakly supervised object localization (WSOL) models can be trained to classify histology images according to cancer grade and identify regions of interest (ROIs) for interpretation, using inexpensive global image-class annotations. A WSOL model initially trained on some labeled source image data can be adapted using unlabeled target data in cases of significant domain shifts caused by variations in staining, scanners, and cancer type. In this paper, we focus on source-free (unsupervised) domain adaptation (SFDA), a challenging problem where a pre-trained source model is adapted to a new target domain without using any source domain data for privacy and efficiency reasons. SFDA of WSOL models raises several challenges in histology, most notably because they are not intended to adapt for both classification and localization tasks. In this paper, 4 state-of-the-art SFDA methods, each one representative of a main SFDA family, are compared for WSOL in terms of classification and localization accuracy. They are the SFDA-Distribution Estimation, Source HypOthesis Transfer, Cross-Domain Contrastive Learning, and Adaptively Domain Statistics Alignment. Experimental results on the challenging Glas (smaller, breast cancer) and Camelyon16 (larger, colon cancer) histology datasets indicate that these SFDA methods typically perform poorly for localization after adaptation when optimized for classification.
Read more5/14/2024

0
Adapting Self-Supervised Learning for Computational Pathology
Eric Zimmermann, Neil Tenenholtz, James Hall, George Shaikovski, Michal Zelechowski, Adam Casson, Fausto Milletari, Julian Viret, Eugene Vorontsov, Siqi Liu, Kristen Severson
Self-supervised learning (SSL) has emerged as a key technique for training networks that can generalize well to diverse tasks without task-specific supervision. This property makes SSL desirable for computational pathology, the study of digitized images of tissues, as there are many target applications and often limited labeled training samples. However, SSL algorithms and models have been primarily developed in the field of natural images and whether their performance can be improved by adaptation to particular domains remains an open question. In this work, we present an investigation of modifications to SSL for pathology data, specifically focusing on the DINOv2 algorithm. We propose alternative augmentations, regularization functions, and position encodings motivated by the characteristics of pathology images. We evaluate the impact of these changes on several benchmarks to demonstrate the value of tailored approaches.
Read more5/6/2024