Unsupervised Novelty Detection Methods Benchmarking with Wavelet Decomposition

0

Sign in to get full access
Overview
- This paper presents a benchmark study of unsupervised novelty detection methods using wavelet decomposition.
- The researchers evaluated the performance of various unsupervised novelty detection algorithms on real-world datasets.
- The study aims to provide insights into the strengths and weaknesses of different novelty detection techniques.
Plain English Explanation
Novelty detection is the task of identifying data points that are different or unusual compared to the normal patterns in a dataset. This is an important problem in many fields, such as anomaly detection in industrial systems or detecting new types of cyber threats.
In this paper, the researchers focused on unsupervised novelty detection, which means the algorithms don't require any labeled examples of "normal" or "anomalous" data. Instead, the algorithms try to learn the normal patterns from the data automatically and then identify points that don't fit those patterns.
The researchers used wavelet decomposition as a way to extract features from the data before feeding it into the novelty detection algorithms. Wavelet decomposition is a technique that can capture patterns at different scales, which can be useful for understanding complex data.
The researchers then benchmarked several unsupervised novelty detection methods on real-world datasets to see how well they performed. This type of benchmark is important for understanding the strengths and limitations of different algorithms and helping practitioners choose the right approach for their specific problem.
Technical Explanation
The paper begins by reviewing the existing literature on unsupervised novelty detection methods, including techniques based on one-class support vector machines, autoencoders, and clustering algorithms.
The key contribution of this work is the use of wavelet decomposition to extract features from the data before applying the novelty detection algorithms. Wavelet decomposition is a signal processing technique that can capture patterns at different scales, which can be particularly useful for complex, non-stationary data.
The researchers evaluated the performance of five unsupervised novelty detection methods on three real-world datasets:
- One-Class Support Vector Machine (OC-SVM): A widely used algorithm that learns a decision boundary around the "normal" data points.
- Isolation Forest: A tree-based algorithm that identifies anomalies based on how easy they are to isolate from the rest of the data.
- Local Outlier Factor (LOF): An algorithm that identifies outliers based on the local density of the data points.
- Autoencoder: A neural network-based method that learns to reconstruct the "normal" data points and identifies anomalies as points with high reconstruction error.
- Gaussian Mixture Model (GMM): A probabilistic model that assumes the data is generated from a mixture of Gaussian distributions, and identifies anomalies as points with low probability under the model.
The performance of these algorithms was evaluated using standard metrics such as precision, recall, and F1-score, and the results were compared across the different datasets and feature extraction approaches (with and without wavelet decomposition).
Critical Analysis
The paper provides a thorough and well-designed benchmark study of unsupervised novelty detection methods. The use of wavelet decomposition as a feature extraction technique is a novel and potentially valuable contribution, as it can capture complex patterns in the data that may not be easily identified by simpler feature engineering approaches.
However, the paper does not address some important limitations and potential issues with the research:
- The datasets used in the study are relatively small and may not be representative of the diversity of real-world novelty detection problems.
- The paper does not explore the sensitivity of the results to the choice of hyperparameters for the different algorithms, which can have a significant impact on their performance.
- The paper does not discuss the computational complexity and runtime of the different algorithms, which can be an important practical consideration in many real-world applications.
Additionally, the paper could have benefited from a more in-depth discussion of the relative strengths and weaknesses of the different novelty detection methods, and how the choice of algorithm might depend on the specific characteristics of the problem at hand.
Conclusion
This paper presents a comprehensive benchmark study of unsupervised novelty detection methods, using wavelet decomposition as a feature extraction technique. The results provide valuable insights into the performance of different algorithms on real-world datasets, and the use of wavelet decomposition suggests a promising direction for improving the accuracy of novelty detection in complex, non-stationary data.
While the study has some limitations, it represents an important contribution to the field of unsupervised anomaly detection and can help guide practitioners in choosing the most appropriate algorithms for their specific applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unsupervised Novelty Detection Methods Benchmarking with Wavelet Decomposition
Ariel Priarone, Umberto Albertin, Carlo Cena, Mauro Martini, Marcello Chiaberge
Novelty detection is a critical task in various engineering fields. Numerous approaches to novelty detection rely on supervised or semi-supervised learning, which requires labelled datasets for training. However, acquiring labelled data, when feasible, can be expensive and time-consuming. For these reasons, unsupervised learning is a powerful alternative that allows performing novelty detection without needing labelled samples. In this study, numerous unsupervised machine learning algorithms for novelty detection are compared, highlighting their strengths and weaknesses in the context of vibration sensing. The proposed framework uses a continuous metric, unlike most traditional methods that merely flag anomalous samples without quantifying the degree of anomaly. Moreover, a new dataset is gathered from an actuator vibrating at specific frequencies to benchmark the algorithms and evaluate the framework. Novel conditions are introduced by altering the input wave signal. Our findings offer valuable insights into the adaptability and robustness of unsupervised learning techniques for real-world novelty detection applications.
Read more9/12/2024

0
The seismic purifier: An unsupervised approach to seismic signal detection via representation learning
Onur Efe, Arkadas Ozakin
In this paper, we develop an unsupervised learning approach to earthquake detection. We train a specific class of deep auto-encoders that learn to reproduce the input waveforms after a data-compressive bottleneck, and then use a simple triggering algorithm at the bottleneck to label waveforms as noise or signal. Our approach is motivated by the intuition that efficient compression of data should represent signals differently from noise, and is facilitated by a time-axis-preserving approach to auto-encoding and intuitively-motivated choices on the architecture and triggering. We demonstrate that the detection performance of the unsupervised approach is comparable to, and in some cases better than, some of the state-of-the-art supervised methods. Moreover, it has strong emph{cross-dataset generalization}. By experimenting with various modifications, we demonstrate that the detection performance is insensitive to various technical choices made in the algorithm. Our approach has the potential to be useful for other signal detection problems with time series data.
Read more7/29/2024
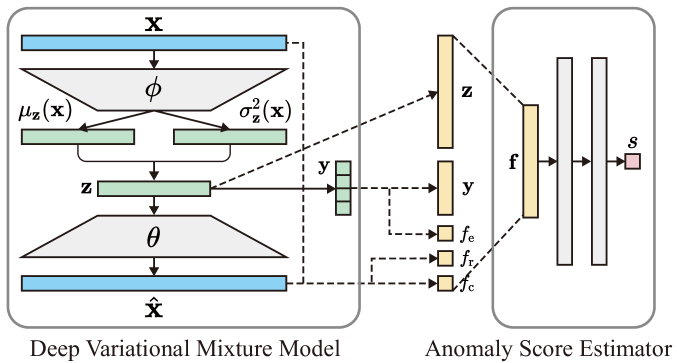
0
Weakly-supervised anomaly detection for multimodal data distributions
Xu Tan, Junqi Chen, Sylwan Rahardja, Jiawei Yang, Susanto Rahardja
Weakly-supervised anomaly detection can outperform existing unsupervised methods with the assistance of a very small number of labeled anomalies, which attracts increasing attention from researchers. However, existing weakly-supervised anomaly detection methods are limited as these methods do not factor in the multimodel nature of the real-world data distribution. To mitigate this, we propose the Weakly-supervised Variational-mixture-model-based Anomaly Detector (WVAD). WVAD excels in multimodal datasets. It consists of two components: a deep variational mixture model, and an anomaly score estimator. The deep variational mixture model captures various features of the data from different clusters, then these features are delivered to the anomaly score estimator to assess the anomaly levels. Experimental results on three real-world datasets demonstrate WVAD's superiority.
Read more6/14/2024

0
Universal Novelty Detection Through Adaptive Contrastive Learning
Hossein Mirzaei, Mojtaba Nafez, Mohammad Jafari, Mohammad Bagher Soltani, Mohammad Azizmalayeri, Jafar Habibi, Mohammad Sabokrou, Mohammad Hossein Rohban
Novelty detection is a critical task for deploying machine learning models in the open world. A crucial property of novelty detection methods is universality, which can be interpreted as generalization across various distributions of training or test data. More precisely, for novelty detection, distribution shifts may occur in the training set or the test set. Shifts in the training set refer to cases where we train a novelty detector on a new dataset and expect strong transferability. Conversely, distribution shifts in the test set indicate the methods' performance when the trained model encounters a shifted test sample. We experimentally show that existing methods falter in maintaining universality, which stems from their rigid inductive biases. Motivated by this, we aim for more generalized techniques that have more adaptable inductive biases. In this context, we leverage the fact that contrastive learning provides an efficient framework to easily switch and adapt to new inductive biases through the proper choice of augmentations in forming the negative pairs. We propose a novel probabilistic auto-negative pair generation method AutoAugOOD, along with contrastive learning, to yield a universal novelty detector method. Our experiments demonstrate the superiority of our method under different distribution shifts in various image benchmark datasets. Notably, our method emerges universality in the lens of adaptability to different setups of novelty detection, including one-class, unlabeled multi-class, and labeled multi-class settings. Code: https://github.com/mojtaba-nafez/UNODE
Read more8/21/2024