Unsupervised Skin Feature Tracking with Deep Neural Networks

0

Sign in to get full access
Overview
- This paper proposes an unsupervised deep learning approach for tracking skin features in images and videos.
- The method aims to automatically detect and follow key visual characteristics on the skin without the need for manual labeling or annotations.
- This could have applications in areas like dermatology, remote patient monitoring, and human-computer interaction.
Plain English Explanation
The researchers have developed a new computer vision technique that can automatically track important visual features on a person's skin without any human supervision. This means the system can analyze images or videos and identify things like moles, freckles, or other distinct markings on the skin, and then follow where those features move over time.
This could be very useful in medical fields like dermatology, where doctors need to monitor changes in a patient's skin over time. Instead of manually inspecting the skin and keeping notes, the computer system could do this tracking automatically. It could also have applications in remote patient monitoring or even in areas like human-computer interaction, where the system could track a person's skin movements to control a device.
The key innovation here is that this skin feature tracking is done in an "unsupervised" way, meaning the system learns to do it without requiring any pre-labeled training data. This makes it more flexible and easier to apply in different contexts compared to other approaches that need a lot of manual labeling first.
Technical Explanation
The paper presents an unsupervised deep learning method for tracking skin features in images and videos. The approach uses a convolutional neural network architecture to learn a latent representation of the visual characteristics on a person's skin. This learned representation is then used to detect and follow the movement of key skin features across frames without any need for manual annotation.
The model is trained in an unsupervised fashion using a combination of reconstruction and adversarial losses. This allows the network to discover the relevant skin features in an autonomous way, rather than relying on pre-labeled training data. The authors evaluate the method on both synthetic and real-world datasets, demonstrating its ability to accurately track moles, freckles, and other skin markings over time.
A key technical contribution is the use of a novel self-supervised contrastive loss function, which encourages the network to learn a robust and discriminative latent space for the skin features. This helps improve the tracking performance compared to more basic reconstruction-only approaches.
The paper also explores ways to make the tracking more robust to challenges like occlusions, changes in lighting, and variations in skin tone. This includes incorporating attention mechanisms and using adversarial training to improve the model's generalization capabilities.
Critical Analysis
The proposed unsupervised skin feature tracking approach represents an interesting and potentially impactful advance in computer vision. The ability to automatically detect and follow key visual characteristics on the skin without any manual labeling could indeed have valuable applications in areas like dermatology, remote health monitoring, and human-computer interaction.
That said, the paper does acknowledge some limitations and areas for future work. For example, the tracking performance may still degrade in challenging real-world scenarios with significant occlusions, dramatic lighting changes, or large variations in skin tone. Extending the method to handle these edge cases more robustly would be an important next step.
Additionally, while the unsupervised nature of the approach is a strength, it may also mean the system cannot capture all the nuanced visual features that a human expert could identify. Incorporating some degree of human supervision or interaction, perhaps through active learning techniques, could help refine the tracked skin features to be more clinically relevant.
Another potential limitation is the reliance on 2D image/video data. Extending the method to work with 3D facial scans or other volumetric skin data could enhance the tracking capabilities and enable more comprehensive skin analysis.
Overall, this work demonstrates promising progress in the challenging domain of unsupervised skin feature tracking. With continued research and refinement, the techniques presented here could lead to practical systems that augment medical professionals and improve various human-centered applications.
Conclusion
This paper introduces an innovative unsupervised deep learning approach for automatically tracking visual skin features in images and videos. By learning a robust latent representation of key skin characteristics, the proposed method can detect and follow the movement of moles, freckles, and other distinctive markings without any need for manual labeling or annotations.
The technical contributions, including the novel self-supervised contrastive loss and attention-based tracking mechanisms, help make the system more robust to real-world challenges. While some limitations remain, this work represents an important step forward in enabling automated skin analysis with broad applications in fields like dermatology, remote patient monitoring, and human-computer interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unsupervised Skin Feature Tracking with Deep Neural Networks
Jose Chang, Torbjorn E. M. Nordling
Facial feature tracking is essential in imaging ballistocardiography for accurate heart rate estimation and enables motor degradation quantification in Parkinson's disease through skin feature tracking. While deep convolutional neural networks have shown remarkable accuracy in tracking tasks, they typically require extensive labeled data for supervised training. Our proposed pipeline employs a convolutional stacked autoencoder to match image crops with a reference crop containing the target feature, learning deep feature encodings specific to the object category in an unsupervised manner, thus reducing data requirements. To overcome edge effects making the performance dependent on crop size, we introduced a Gaussian weight on the residual errors of the pixels when calculating the loss function. Training the autoencoder on facial images and validating its performance on manually labeled face and hand videos, our Deep Feature Encodings (DFE) method demonstrated superior tracking accuracy with a mean error ranging from 0.6 to 3.3 pixels, outperforming traditional methods like SIFT, SURF, Lucas Kanade, and the latest transformers like PIPs++ and CoTracker. Overall, our unsupervised learning approach excels in tracking various skin features under significant motion conditions, providing superior feature descriptors for tracking, matching, and image registration compared to both traditional and state-of-the-art supervised learning methods.
Read more5/9/2024

0
Unsupervised learning of Data-driven Facial Expression Coding System (DFECS) using keypoint tracking
Shivansh Chandra Tripathi, Rahul Garg
The development of existing facial coding systems, such as the Facial Action Coding System (FACS), relied on manual examination of facial expression videos for defining Action Units (AUs). To overcome the labor-intensive nature of this process, we propose the unsupervised learning of an automated facial coding system by leveraging computer-vision-based facial keypoint tracking. In this novel facial coding system called the Data-driven Facial Expression Coding System (DFECS), the AUs are estimated by applying dimensionality reduction to facial keypoint movements from a neutral frame through a proposed Full Face Model (FFM). FFM employs a two-level decomposition using advanced dimensionality reduction techniques such as dictionary learning (DL) and non-negative matrix factorization (NMF). These techniques enhance the interpretability of AUs by introducing constraints such as sparsity and positivity to the encoding matrix. Results show that DFECS AUs estimated from the DISFA dataset can account for an average variance of up to 91.29 percent in test datasets (CK+ and BP4D-Spontaneous) and also surpass the variance explained by keypoint-based equivalents of FACS AUs in these datasets. Additionally, 87.5 percent of DFECS AUs are interpretable, i.e., align with the direction of facial muscle movements. In summary, advancements in automated facial coding systems can accelerate facial expression analysis across diverse fields such as security, healthcare, and entertainment. These advancements offer numerous benefits, including enhanced detection of abnormal behavior, improved pain analysis in healthcare settings, and enriched emotion-driven interactions. To facilitate further research, the code repository of DFECS has been made publicly accessible.
Read more6/11/2024

0
Ensembling convolutional neural networks for human skin segmentation
Patryk Kuban, Michal Kawulok
Detecting and segmenting human skin regions in digital images is an intensively explored topic of computer vision with a variety of approaches proposed over the years that have been found useful in numerous practical applications. The first methods were based on pixel-wise skin color modeling and they were later enhanced with context-based analysis to include the textural and geometrical features, recently extracted using deep convolutional neural networks. It has been also demonstrated that skin regions can be segmented from grayscale images without using color information at all. However, the possibility to combine these two sources of information has not been explored so far and we address this research gap with the contribution reported in this paper. We propose to train a convolutional network using the datasets focused on different features to create an ensemble whose individual outcomes are effectively combined using yet another convolutional network trained to produce the final segmentation map. The experimental results clearly indicate that the proposed approach outperforms the basic classifiers, as well as an ensemble based on the voting scheme. We expect that this study will help in developing new ensemble-based techniques that will improve the performance of semantic segmentation systems, reaching beyond the problem of detecting human skin.
Read more7/30/2024
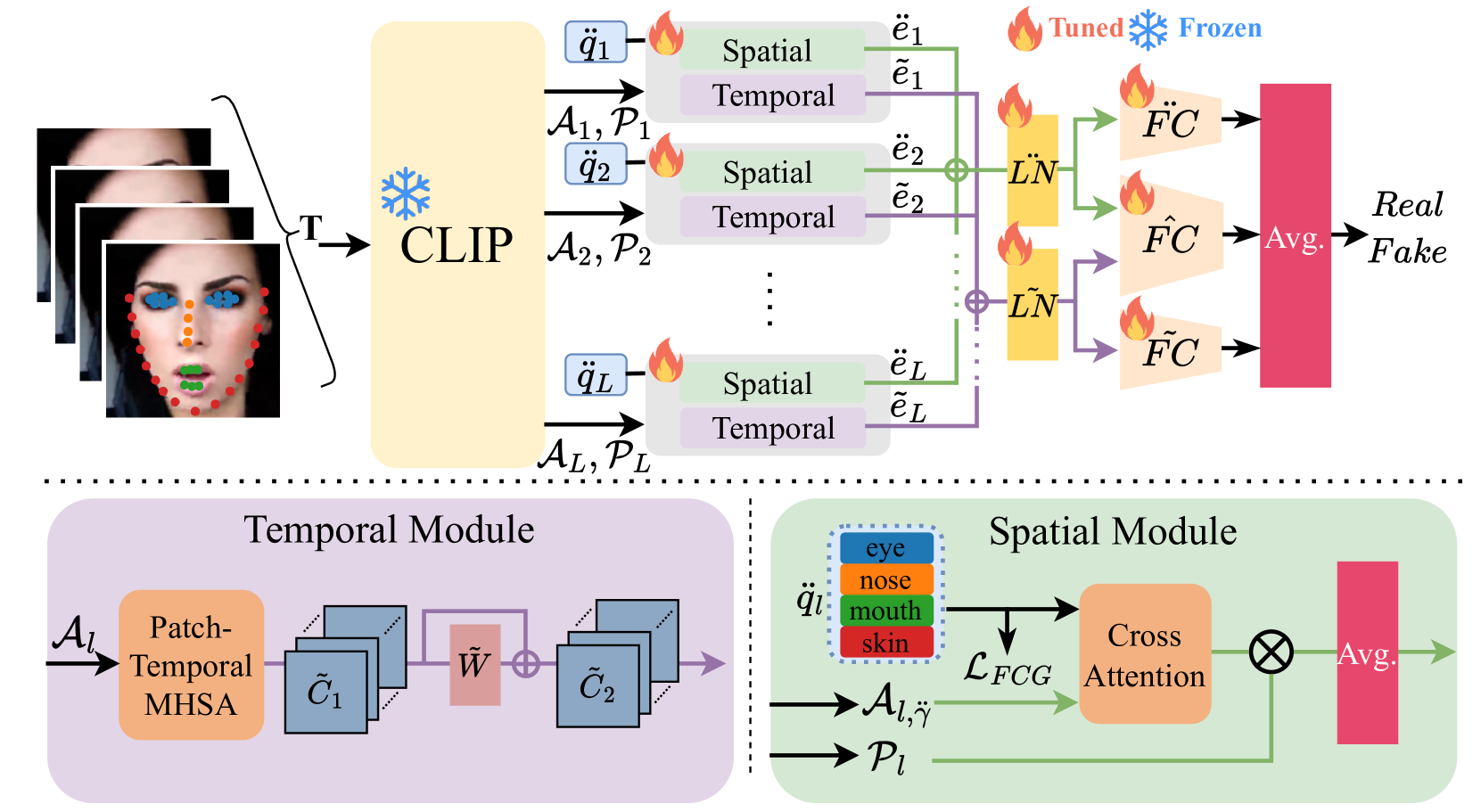
0
Towards More General Video-based Deepfake Detection through Facial Feature Guided Adaptation for Foundation Model
Yue-Hua Han, Tai-Ming Huang, Shu-Tzu Lo, Po-Han Huang, Kai-Lung Hua, Jun-Cheng Chen
With the rise of deep learning, generative models have enabled the creation of highly realistic synthetic images, presenting challenges due to their potential misuse. While research in Deepfake detection has grown rapidly in response, many detection methods struggle with unseen Deepfakes generated by new synthesis techniques. To address this generalisation challenge, we propose a novel Deepfake detection approach by adapting the Foundation Models with rich information encoded inside, specifically using the image encoder from CLIP which has demonstrated strong zero-shot capability for downstream tasks. Inspired by the recent advances of parameter efficient fine-tuning, we propose a novel side-network-based decoder to extract spatial and temporal cues from the given video clip, with the promotion of the Facial Component Guidance (FCG) to encourage the spatial feature to include features of key facial parts for more robust and general Deepfake detection. Through extensive cross-dataset evaluations, our approach exhibits superior effectiveness in identifying unseen Deepfake samples, achieving notable performance improvement even with limited training samples and manipulation types. Our model secures an average performance enhancement of 0.9% AUROC in cross-dataset assessments comparing with state-of-the-art methods, especially a significant lead of achieving 4.4% improvement on the challenging DFDC dataset.
Read more6/6/2024