Unveiling Context-Related Anomalies: Knowledge Graph Empowered Decoupling of Scene and Action for Human-Related Video Anomaly Detection

0

Sign in to get full access
Overview
- Knowledge Graph Empowered Decoupling of Scene and Action for Human-Related Video Anomaly Detection
- Focuses on detecting anomalies in human-related videos by leveraging knowledge graphs to decouple scene and action information
- Aims to improve the accuracy and interpretability of video anomaly detection systems
Plain English Explanation
Video anomaly detection is the task of identifying unusual or unexpected events in video footage. This paper proposes a novel approach that uses a knowledge graph to better understand the relationship between the scene (the environment or setting) and the actions taking place.
The key idea is to decouple, or separate, the scene information from the action information in the video. This allows the system to better recognize when an action is out of place for a particular scene, which can indicate an anomaly. For example, if a person is seen running in a library, this would be considered anomalous behavior for that environment.
By incorporating a knowledge graph, the system can learn the typical associations between scenes and actions. The knowledge graph acts as a structured database of common sense knowledge, helping the model understand the context and make more informed decisions about what is normal or anomalous.
This approach aims to improve the accuracy and interpretability of video anomaly detection systems, as the separation of scene and action information provides more detailed insights into the nature of the anomaly. The researchers demonstrate the effectiveness of their method on benchmark datasets, showing it outperforms other state-of-the-art techniques.
Technical Explanation
The paper presents a novel framework for video anomaly detection that leverages a knowledge graph to decouple scene and action information. The key components of the approach are:
-
Scene-Action Decoupling: The model learns separate representations for the scene and action information in the video, allowing it to better understand the context and detect anomalies.
-
Knowledge Graph Integration: A knowledge graph is used to capture the typical associations between scenes and actions, providing the model with additional contextual information to identify anomalies.
-
Anomaly Detection: The model compares the predicted scene-action associations from the knowledge graph with the observed scene-action pairs in the video. Significant deviations are flagged as anomalies.
The authors evaluate their method on several benchmark datasets for human-related video anomaly detection and show that it outperforms other state-of-the-art techniques in terms of both accuracy and interpretability. The knowledge graph-based approach allows the model to better understand the context and make more informed decisions about what constitutes normal or anomalous behavior.
Critical Analysis
The paper presents a promising approach to video anomaly detection, but there are a few potential limitations and areas for further research:
-
Scalability of Knowledge Graph: The effectiveness of the knowledge graph-based approach may be limited by the size and quality of the underlying knowledge graph. Constructing a comprehensive knowledge graph for all possible scene-action associations could be challenging, especially for complex or domain-specific applications.
-
Dependency on Labeled Data: The training of the scene-action decoupling model still relies on labeled data, which can be expensive and time-consuming to obtain. Exploring unsupervised or semi-supervised techniques could help reduce the labeling burden.
-
Generalization to Diverse Scenarios: While the experiments show promising results on benchmark datasets, it's important to evaluate the method's performance on a wider range of real-world video data, which may include more diverse and complex anomalies.
-
Interpretability Limitations: While the scene-action decoupling provides more interpretable insights, there may still be challenges in fully explaining the model's decision-making process, especially for more complex anomalies.
Future research could address these limitations, for example, by investigating methods to automatically expand or refine the knowledge graph, exploring self-supervised learning approaches, and developing more comprehensive evaluation frameworks for video anomaly detection systems.
Conclusion
The paper presents a novel video anomaly detection framework that leverages a knowledge graph to decouple scene and action information, leading to improved accuracy and interpretability. By understanding the typical associations between scenes and actions, the model can more effectively identify anomalies that deviate from these expected patterns.
This research contributes to the ongoing efforts in the field of video anomaly detection, which has important applications in surveillance, safety monitoring, and human-related activity analysis. The knowledge graph-based approach offers a promising direction for enhancing the contextual understanding of video data and developing more robust and interpretable anomaly detection systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unveiling Context-Related Anomalies: Knowledge Graph Empowered Decoupling of Scene and Action for Human-Related Video Anomaly Detection
Chenglizhao Chen, Xinyu Liu, Mengke Song, Luming Li, Xu Yu, Shanchen Pang
Detecting anomalies in human-related videos is crucial for surveillance applications. Current methods primarily include appearance-based and action-based techniques. Appearance-based methods rely on low-level visual features such as color, texture, and shape. They learn a large number of pixel patterns and features related to known scenes during training, making them effective in detecting anomalies within these familiar contexts. However, when encountering new or significantly changed scenes, i.e., unknown scenes, they often fail because existing SOTA methods do not effectively capture the relationship between actions and their surrounding scenes, resulting in low generalization. In contrast, action-based methods focus on detecting anomalies in human actions but are usually less informative because they tend to overlook the relationship between actions and their scenes, leading to incorrect detection. For instance, the normal event of running on the beach and the abnormal event of running on the street might both be considered normal due to the lack of scene information. In short, current methods struggle to integrate low-level visual and high-level action features, leading to poor anomaly detection in varied and complex scenes. To address this challenge, we propose a novel decoupling-based architecture for human-related video anomaly detection (DecoAD). DecoAD significantly improves the integration of visual and action features through the decoupling and interweaving of scenes and actions, thereby enabling a more intuitive and accurate understanding of complex behaviors and scenes. DecoAD supports fully supervised, weakly supervised, and unsupervised settings.
Read more9/6/2024
🤔
0
DEVIAS: Learning Disentangled Video Representations of Action and Scene for Holistic Video Understanding
Kyungho Bae, Geo Ahn, Youngrae Kim, Jinwoo Choi
Video recognition models often learn scene-biased action representation due to the spurious correlation between actions and scenes in the training data. Such models show poor performance when the test data consists of videos with unseen action-scene combinations. Although scene-debiased action recognition models might address the issue, they often overlook valuable scene information in the data. To address this challenge, we propose to learn DisEntangled VIdeo representations of Action and Scene (DEVIAS), for more holistic video understanding. We propose an encoder-decoder architecture to learn disentangled action and scene representations with a single model. The architecture consists of a disentangling encoder (DE), an action mask decoder (AMD), and a prediction head. The key to achieving the disentanglement is employing both DE and AMD during training time. The DE uses the slot attention mechanism to learn disentangled action and scene representations. For further disentanglement, an AMD learns to predict action masks, given an action slot. With the resulting disentangled representations, we can achieve robust performance across diverse scenarios, including both seen and unseen action-scene combinations. We rigorously validate the proposed method on the UCF-101, Kinetics-400, and HVU datasets for the seen, and the SCUBA, HAT, and HVU datasets for unseen action-scene combination scenarios. Furthermore, DEVIAS provides flexibility to adjust the emphasis on action or scene information depending on dataset characteristics for downstream tasks. DEVIAS shows favorable performance in various downstream tasks: Diving48, Something-Something-V2, UCF-101, and ActivityNet. The code is available at https://github.com/KHU-VLL/DEVIAS.
Read more9/9/2024

0
Learn Suspected Anomalies from Event Prompts for Video Anomaly Detection
Chenchen Tao, Xiaohao Peng, Chong Wang, Jiafei Wu, Puning Zhao, Jun Wang, Jiangbo Qian
Most models for weakly supervised video anomaly detection (WS-VAD) rely on multiple instance learning, aiming to distinguish normal and abnormal snippets without specifying the type of anomaly. However, the ambiguous nature of anomaly definitions across contexts may introduce inaccuracy in discriminating abnormal and normal events. To show the model what is anomalous, a novel framework is proposed to guide the learning of suspected anomalies from event prompts. Given a textual prompt dictionary of potential anomaly events and the captions generated from anomaly videos, the semantic anomaly similarity between them could be calculated to identify the suspected events for each video snippet. It enables a new multi-prompt learning process to constrain the visual-semantic features across all videos, as well as provides a new way to label pseudo anomalies for self-training. To demonstrate its effectiveness, comprehensive experiments and detailed ablation studies are conducted on four datasets, namely XD-Violence, UCF-Crime, TAD, and ShanghaiTech. Our proposed model outperforms most state-of-the-art methods in terms of AP or AUC (86.5%, hl{90.4}%, 94.4%, and 97.4%). Furthermore, it shows promising performance in open-set and cross-dataset cases. The data, code, and models can be found at: url{https://github.com/shiwoaz/lap}.
Read more9/4/2024
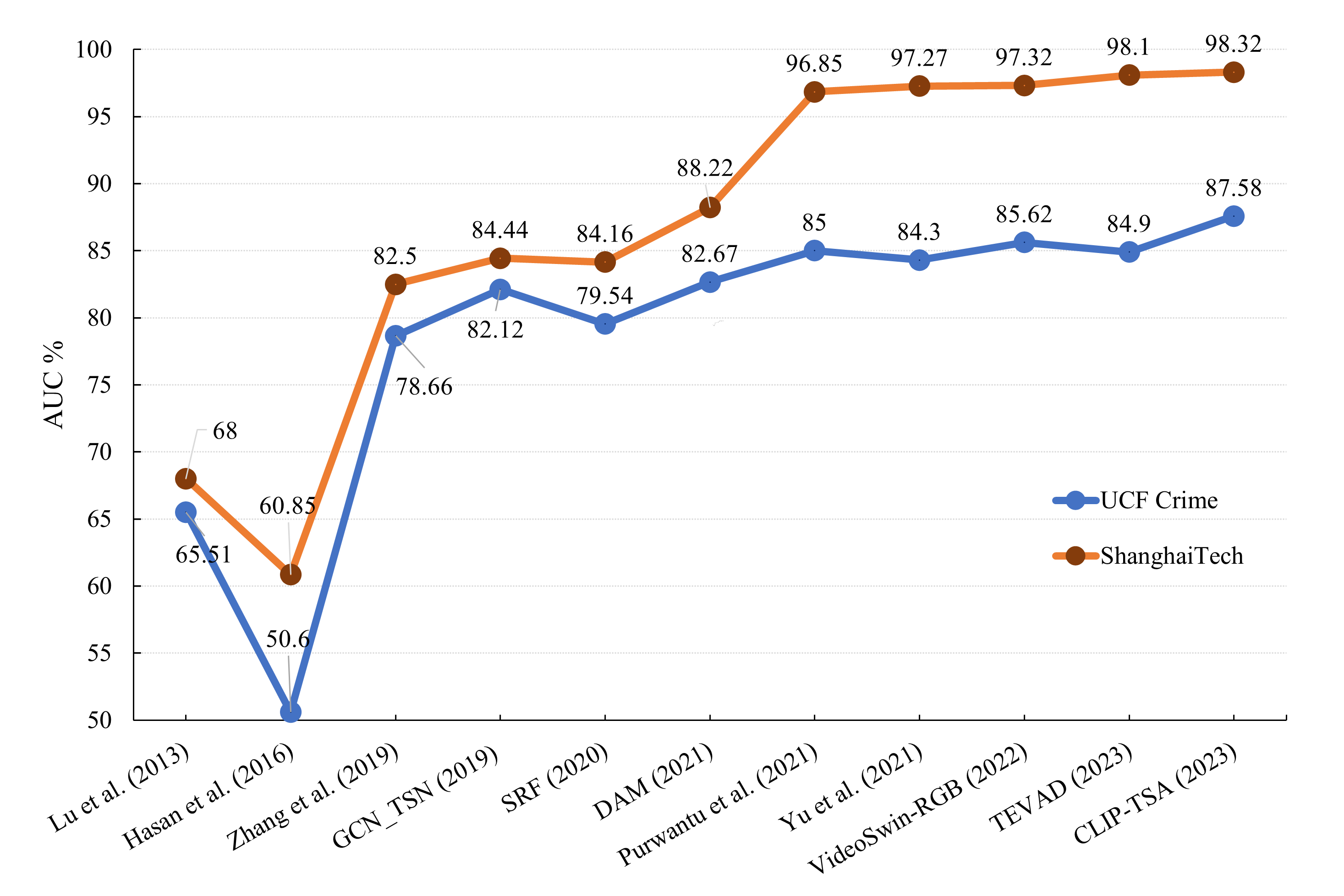
0
Video Anomaly Detection in 10 Years: A Survey and Outlook
Moshira Abdalla, Sajid Javed, Muaz Al Radi, Anwaar Ulhaq, Naoufel Werghi
Video anomaly detection (VAD) holds immense importance across diverse domains such as surveillance, healthcare, and environmental monitoring. While numerous surveys focus on conventional VAD methods, they often lack depth in exploring specific approaches and emerging trends. This survey explores deep learning-based VAD, expanding beyond traditional supervised training paradigms to encompass emerging weakly supervised, self-supervised, and unsupervised approaches. A prominent feature of this review is the investigation of core challenges within the VAD paradigms including large-scale datasets, features extraction, learning methods, loss functions, regularization, and anomaly score prediction. Moreover, this review also investigates the vision language models (VLMs) as potent feature extractors for VAD. VLMs integrate visual data with textual descriptions or spoken language from videos, enabling a nuanced understanding of scenes crucial for anomaly detection. By addressing these challenges and proposing future research directions, this review aims to foster the development of robust and efficient VAD systems leveraging the capabilities of VLMs for enhanced anomaly detection in complex real-world scenarios. This comprehensive analysis seeks to bridge existing knowledge gaps, provide researchers with valuable insights, and contribute to shaping the future of VAD research.
Read more7/2/2024