Using Deep Learning to Increase Eye-Tracking Robustness, Accuracy, and Precision in Virtual Reality
2403.19768
0
0
Abstract
Algorithms for the estimation of gaze direction from mobile and video-based eye trackers typically involve tracking a feature of the eye that moves through the eye camera image in a way that covaries with the shifting gaze direction, such as the center or boundaries of the pupil. Tracking these features using traditional computer vision techniques can be difficult due to partial occlusion and environmental reflections. Although recent efforts to use machine learning (ML) for pupil tracking have demonstrated superior results when evaluated using standard measures of segmentation performance, little is known of how these networks may affect the quality of the final gaze estimate. This work provides an objective assessment of the impact of several contemporary ML-based methods for eye feature tracking when the subsequent gaze estimate is produced using either feature-based or model-based methods. Metrics include the accuracy and precision of the gaze estimate, as well as drop-out rate.
Create account to get full access
Introduction
The study aims to evaluate the impact of improved feature detection models on the quality of the final gaze estimate in mobile eye tracking systems. Mobile eye trackers often suffer from lower data quality compared to desktop eye trackers due to smaller eye cameras, lower resolution eye images, and dynamic ambient infrared illumination in natural environments. Despite progress in using machine learning for accurate eye image segmentation and feature localization, there has been minimal impact on the accuracy of consumer-level mobile eye tracking systems or public interest and adoption rates.
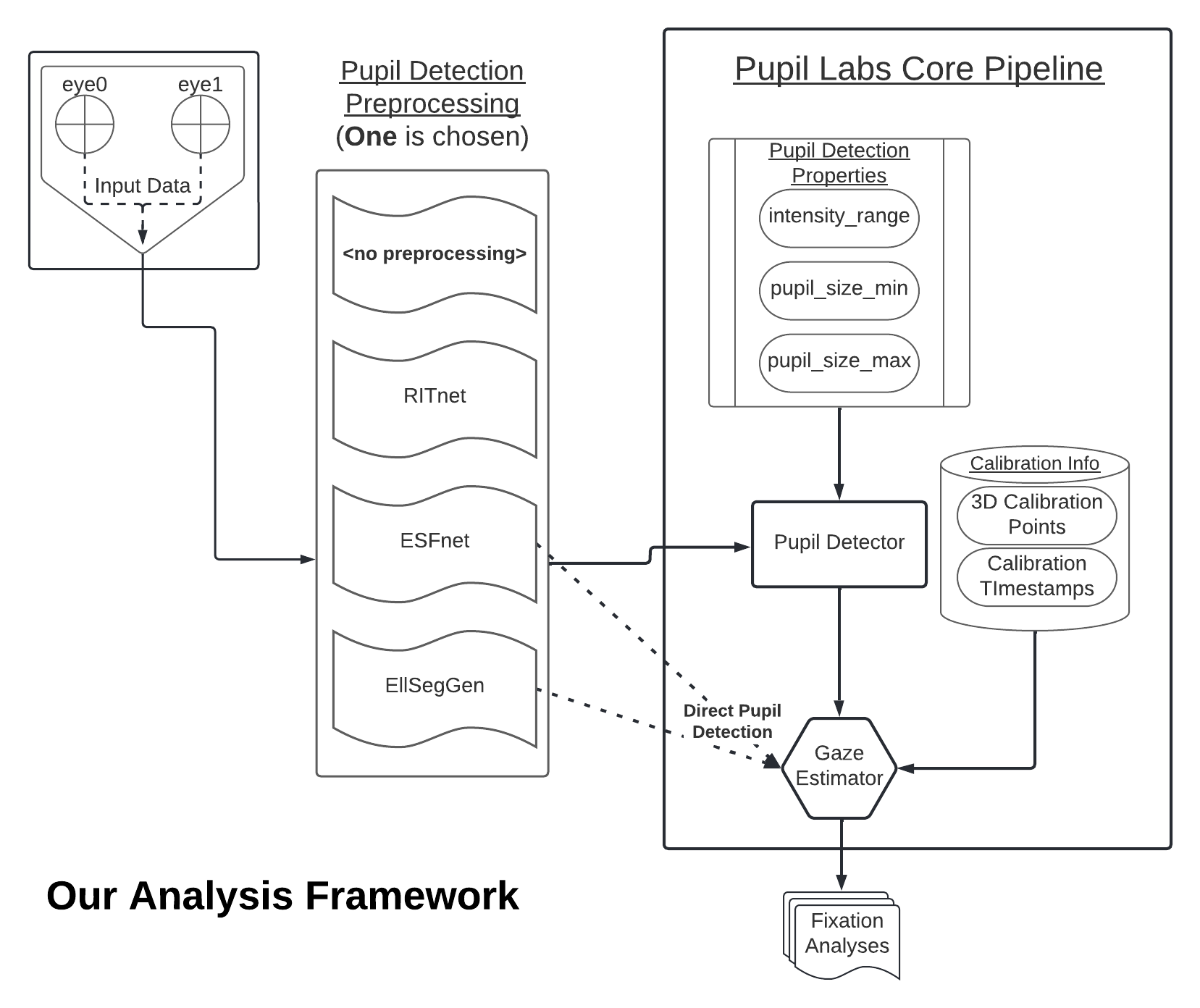
The authors introduce a custom pipeline to objectively assess the contribution of improved feature detection models on the quality of the final gaze estimate when applied to an open-source eye tracking solution, the Pupil Labs gaze mapping software. Two gaze mapping algorithms are used: the Pupil Labs feature-based gaze mapper, which provides a simple polynomial mapping between pupil location and gaze direction, and the more contemporary Pupil Labs 3D model-based gaze mapper, designed to address some of the shortcomings of the simple polynomial mapping.
The study tests and reports on the impact of several contemporary eye segmentation networks on the spatial accuracy, precision, and robustness to dropouts of the final gaze estimate while keeping other properties of the eye tracking pipeline unchanged.
Background
The provided text discusses sources of error in pupil detection and the impact of feature localization accuracy on gaze estimates in eye tracking systems. Hardware limitations, environmental factors, and individual differences can all contribute to inaccuracies in pupil detection. The effect of degraded feature detection on the gaze estimate depends on the type of gaze estimation algorithm used, with feature-based algorithms being more directly impacted than 3D model-based algorithms.
Machine learning methods for eye image segmentation, such as RITnet, EllSeg/EllSegGen, and ESFnet, have made significant progress in recent years. These neural networks can provide semantic labels for each pixel in an eye image, even when features are obscured. However, despite their high performance, these methods have not been widely adopted in eye tracking pipelines. Possible reasons include a lack of understanding of the connection between feature extraction and real-world eye tracking performance, and the increased computational load of these networks.
The authors present an objective evaluation of the contribution of improved feature detection models on the quality of the final gaze estimate in an open-source eye tracker integration into virtual reality by Pupil Labs. They provide an open-source pipeline for batch processing eye tracking videos, compare three neural networks (RITnet, EllSegGen, and ESFnet) to the Pupil Labs feature detector, and offer data-driven recommendations on which feature detection neural network to use based on dropout rate, accuracy, and precision.
Methodology
The paper describes an IRB-approved study in which 10 participants wore an HTC Vive Pro virtual reality headset with eye-tracking capabilities. Eye-tracking data was collected at different resolutions and sampling rates using the open-source Pupil Labs eye-tracking suite. Participants completed calibration and assessment routines involving fixating on targets presented within the headset.
The collected eye camera video was processed using various pupil detection algorithms, including the native Pupil Labs algorithm and neural networks like RITnet, EllSegGen, and ESFnet. The detected pupil ellipses were evaluated using confidence algorithms to ensure the quality of the data used for gaze estimation.
The paper compares feature-based and 3D model-based gaze estimation algorithms provided by the Pupil Labs software. The feature-based algorithm uses a polynomial function to map pupil positions to gaze locations, while the 3D model-based algorithm relies on fitting a geometric eye model within the eye-camera space.
To assess the performance of the gaze estimation algorithms, the authors calculate dropout rate, accuracy, and precision. Dropout rate is determined by a threshold of 10 degrees of accuracy error, with samples above this threshold being removed from further analysis. Accuracy represents the distance between the centroid of gaze angles and the ground-truth target location, while precision is the average difference between each gaze location and the center of mass of all gaze locations during a fixation.
Results
Results for dropout rate, accuracy, and precision averaged across all participants are shown in Figures 5 and 6 for 192x192px and 400x400px eye images respectively. Mean and standard error values are provided in Tables 1, 2, and 3.
At 192x192px resolution, RITnet performed poorly in terms of dropout, accuracy error, and precision error compared to other detection methods. Average dropout rates exceeded 61% for feature-based methods and 81% for 3D model-based methods, indicating RITnet is unsuitable at this resolution.
At 400x400px resolution, RITnet's performance was equivalent to the native Pupil Labs algorithm. Dropout rate increased linearly with gaze angle eccentricity, peaking around 20%. Accuracy error remained within 0.5 degrees of the native algorithm for both feature-based and 3D model-based gaze estimators.
EllSegGen (Direct Iris) combined with 3D model-based gaze estimation yielded very high dropout rates (30-32%) and is not recommended. At 192x192px, other EllSegGen variants had lower dropout rates than the native algorithm but no accuracy improvement. At 400x400px, EllSegGen variants had dropout rates below 6% with feature-based methods and precision improvements at higher eccentricities. EllSegGen performed best with 3D model-based estimation at 400x400px.
ESFnet performed similarly to EllSegGen at 192x192px, with ESFnet (Direct Pupil) matching or outperforming other models. At 400x400px, ESFnet and ESFnet (Direct Pupil) matched or exceeded native algorithm performance, except for increased dropout at higher eccentricities with 3D model-based methods.
Discussion

The paper discusses the performance of machine learning segmentation models for eye tracking in virtual reality headsets. The models were tested on eye images captured from off-axial angles within a VR headset, which differed from the datasets used to train the models. Despite this difference, the models demonstrated positive performance, indicating their ability to generalize to mobile eye trackers with varying parameters.
Image resolution had a significant impact on model performance, with lower resolution images (192x192px) surprisingly outperforming higher resolution images (400x400px). Further testing revealed that this effect was likely due to differences in image content rather than resolution itself.
The EllSegGen (Direct Iris) model provided competitive results when used with a feature-based gaze estimator but performed poorly with a 3D model-based gaze estimator. This discrepancy may be attributed to assumptions in the Pupil Labs Pye3D 3D model-based gaze estimator or differences in the information utilized by the two estimators. The feature-based algorithm only uses the centroid of the detected ellipse, while the 3D model-based algorithm uses all ellipse parameters to position the 3D eye models. This suggests that EllSegGen (Direct Iris) may accurately detect the iris centroid but struggle with estimating iris boundaries.
Conclusion
Summary:
The paper addresses the challenge of obtaining high-quality gaze data from mobile eye trackers, which often suffer from limitations due to hardware constraints. The authors propose using machine learning techniques, specifically eye feature detection neural networks, to improve the accuracy of feature localization and, consequently, the quality of the final gaze estimate.
The study focuses on measuring the potential impact of these machine learning improvements on gaze estimate quality, considering factors such as dropout rate and precision. The authors conclude that high-performing eye feature detection neural networks can effectively reduce dropouts and improve precision without compromising gaze accuracy.
The paper provides a means for eye tracking system users to enhance their data quality through the informed selection of pupil detection models. The authors have developed software for evaluating the contribution of feature detection models to gaze estimate quality, which will be made publicly available upon publication.
Although the study relies on specific hardware and software (Pupil Labs integration into the HTC Vive Pro headset and the Pupil Labs gaze estimation software framework), the findings are not necessarily dependent on these factors. The authors suggest that future work may explore the viability of these machine learning solutions on alternative eye-tracking hardware/software and in various contexts, such as outdoor eye tracking.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

3D Gaze Tracking for Studying Collaborative Interactions in Mixed-Reality Environments
Eduardo Davalos, Yike Zhang, Ashwin T. S., Joyce H. Fonteles, Umesh Timalsina, Guatam Biswas
0
0
This study presents a novel framework for 3D gaze tracking tailored for mixed-reality settings, aimed at enhancing joint attention and collaborative efforts in team-based scenarios. Conventional gaze tracking, often limited by monocular cameras and traditional eye-tracking apparatus, struggles with simultaneous data synchronization and analysis from multiple participants in group contexts. Our proposed framework leverages state-of-the-art computer vision and machine learning techniques to overcome these obstacles, enabling precise 3D gaze estimation without dependence on specialized hardware or complex data fusion. Utilizing facial recognition and deep learning, the framework achieves real-time, tracking of gaze patterns across several individuals, addressing common depth estimation errors, and ensuring spatial and identity consistency within the dataset. Empirical results demonstrate the accuracy and reliability of our method in group environments. This provides mechanisms for significant advances in behavior and interaction analysis in educational and professional training applications in dynamic and unstructured environments.
6/18/2024

Driver Attention Tracking and Analysis
Dat Viet Thanh Nguyen, Anh Tran, Hoai Nam Vu, Cuong Pham, Minh Hoai
0
0
We propose a novel method to estimate a driver's points-of-gaze using a pair of ordinary cameras mounted on the windshield and dashboard of a car. This is a challenging problem due to the dynamics of traffic environments with 3D scenes of unknown depths. This problem is further complicated by the volatile distance between the driver and the camera system. To tackle these challenges, we develop a novel convolutional network that simultaneously analyzes the image of the scene and the image of the driver's face. This network has a camera calibration module that can compute an embedding vector that represents the spatial configuration between the driver and the camera system. This calibration module improves the overall network's performance, which can be jointly trained end to end. We also address the lack of annotated data for training and evaluation by introducing a large-scale driving dataset with point-of-gaze annotations. This is an in situ dataset of real driving sessions in an urban city, containing synchronized images of the driving scene as well as the face and gaze of the driver. Experiments on this dataset show that the proposed method outperforms various baseline methods, having the mean prediction error of 29.69 pixels, which is relatively small compared to the $1280{times}720$ resolution of the scene camera.
4/12/2024

Spatio-Temporal Attention and Gaussian Processes for Personalized Video Gaze Estimation
Swati Jindal, Mohit Yadav, Roberto Manduchi
0
0
Gaze is an essential prompt for analyzing human behavior and attention. Recently, there has been an increasing interest in determining gaze direction from facial videos. However, video gaze estimation faces significant challenges, such as understanding the dynamic evolution of gaze in video sequences, dealing with static backgrounds, and adapting to variations in illumination. To address these challenges, we propose a simple and novel deep learning model designed to estimate gaze from videos, incorporating a specialized attention module. Our method employs a spatial attention mechanism that tracks spatial dynamics within videos. This technique enables accurate gaze direction prediction through a temporal sequence model, adeptly transforming spatial observations into temporal insights, thereby significantly improving gaze estimation accuracy. Additionally, our approach integrates Gaussian processes to include individual-specific traits, facilitating the personalization of our model with just a few labeled samples. Experimental results confirm the efficacy of the proposed approach, demonstrating its success in both within-dataset and cross-dataset settings. Specifically, our proposed approach achieves state-of-the-art performance on the Gaze360 dataset, improving by $2.5^circ$ without personalization. Further, by personalizing the model with just three samples, we achieved an additional improvement of $0.8^circ$. The code and pre-trained models are available at url{https://github.com/jswati31/stage}.
4/11/2024
Evaluating Eye Movement Biometrics in Virtual Reality: A Comparative Analysis of VR Headset and High-End Eye-Tracker Collected Dataset
Mehedi Hasan Raju, Dillon J Lohr, Oleg V Komogortsev
0
0
Previous studies have shown that eye movement data recorded at 1000 Hz can be used to authenticate individuals. This study explores the effectiveness of eye movement-based biometrics (EMB) by utilizing data from an eye-tracking (ET)-enabled virtual reality (VR) headset (GazeBaseVR) and compares it to the performance using data from a high-end eye tracker (GazeBase) that has been downsampled to 250 Hz. The research also aims to assess the biometric potential of both binocular and monocular eye movement data. GazeBaseVR dataset achieves an equal error rate (EER) of 1.67% and a false rejection rate (FRR) at 10^-4 false acceptance rate (FAR) of 22.73% in a binocular configuration. This study underscores the biometric viability of data obtained from eye-tracking-enabled VR headset.
5/7/2024