Using Pretrained Large Language Model with Prompt Engineering to Answer Biomedical Questions

0

Sign in to get full access
Overview
• This paper explores the use of large language models (LLMs) and prompt engineering to answer biomedical questions. • The researchers investigate how well LLMs can recall and apply medical knowledge when prompted with relevant questions. • The study builds on previous research on using LLMs for educational and medical applications, such as MedReQAL, PromptLink, and Exploring Capabilities of Prompted LLMs.
Plain English Explanation
Large language models (LLMs) are advanced AI systems trained on massive amounts of text data. These models have shown impressive capabilities in understanding and generating human-like language. In this paper, the researchers investigate whether LLMs can be effectively used to answer biomedical questions by combining them with prompt engineering.
Prompt engineering involves carefully crafting the instructions or "prompts" given to the LLM to elicit the desired response. The researchers explore how to design prompts that allow LLMs to recall and apply their medical knowledge to answer questions related to topics like disease, treatment, and medical procedures.
The study builds on previous work that has explored the use of LLMs in educational and medical contexts, such as assessing medical knowledge recall (MedReQAL) and leveraging LLMs to link information across different sources (PromptLink). The researchers aim to further advance the understanding of how these powerful language models can be effectively utilized to support medical and healthcare applications.
Technical Explanation
The researchers conducted a series of experiments to evaluate the performance of LLMs in answering biomedical questions. They fine-tuned a pre-trained LLM on a large corpus of biomedical literature and then tested the model's ability to answer questions across various medical domains, such as disease, treatment, and medical procedures.
The researchers carefully designed prompts to guide the LLM in recalling and applying its medical knowledge. These prompts included detailed instructions, contextual information, and specific question formats. By analyzing the model's responses, the researchers gained insights into the strengths and limitations of using LLMs for biomedical question answering.
The findings of this study build on previous research that has explored the use of LLMs in educational and medical applications. For example, the MedReQAL project examined medical knowledge recall in LLMs, while the PromptLink study explored how LLMs can be used to link information across different sources.
Critical Analysis
The paper acknowledges several limitations and areas for further research. The researchers note that the performance of LLMs can be influenced by the quality and breadth of the training data, and that more diverse datasets may be needed to capture the full range of biomedical knowledge.
Additionally, the study focuses on the ability of LLMs to answer factual questions, but does not address their potential for more complex reasoning or decision-making tasks in the medical domain. Further research may be needed to explore the capabilities and limitations of LLMs in more nuanced and high-stakes medical applications.
It is also important to consider the potential ethical and privacy concerns associated with the use of LLMs in healthcare, such as the need to ensure the confidentiality of patient information and the transparency of the decision-making process. The Edinburgh Clinical NLP project has addressed some of these concerns in the context of clinical natural language processing.
Conclusion
This study demonstrates the potential of using large language models (LLMs) and prompt engineering to answer biomedical questions. By fine-tuning LLMs on medical literature and carefully designing prompts, the researchers were able to leverage the language understanding and generation capabilities of these models to recall and apply medical knowledge.
The findings of this research build on previous work that has explored the use of LLMs in educational and medical applications, such as assessing medical knowledge recall (MedReQAL) and linking information across different sources (PromptLink).
While the study highlights the potential of LLMs in biomedical question answering, it also acknowledges the need for further research to address the limitations and ethical considerations surrounding the use of these models in healthcare. As the field of AI continues to advance, the integration of LLMs with prompt engineering may prove to be a valuable tool for supporting medical professionals and enhancing patient care.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Using Pretrained Large Language Model with Prompt Engineering to Answer Biomedical Questions
Wenxin Zhou, Thuy Hang Ngo
Our team participated in the BioASQ 2024 Task12b and Synergy tasks to build a system that can answer biomedical questions by retrieving relevant articles and snippets from the PubMed database and generating exact and ideal answers. We propose a two-level information retrieval and question-answering system based on pre-trained large language models (LLM), focused on LLM prompt engineering and response post-processing. We construct prompts with in-context few-shot examples and utilize post-processing techniques like resampling and malformed response detection. We compare the performance of various pre-trained LLM models on this challenge, including Mixtral, OpenAI GPT and Llama2. Our best-performing system achieved 0.14 MAP score on document retrieval, 0.05 MAP score on snippet retrieval, 0.96 F1 score for yes/no questions, 0.38 MRR score for factoid questions and 0.50 F1 score for list questions in Task 12b.
Read more7/10/2024
0
MedREQAL: Examining Medical Knowledge Recall of Large Language Models via Question Answering
Juraj Vladika, Phillip Schneider, Florian Matthes
In recent years, Large Language Models (LLMs) have demonstrated an impressive ability to encode knowledge during pre-training on large text corpora. They can leverage this knowledge for downstream tasks like question answering (QA), even in complex areas involving health topics. Considering their high potential for facilitating clinical work in the future, understanding the quality of encoded medical knowledge and its recall in LLMs is an important step forward. In this study, we examine the capability of LLMs to exhibit medical knowledge recall by constructing a novel dataset derived from systematic reviews -- studies synthesizing evidence-based answers for specific medical questions. Through experiments on the new MedREQAL dataset, comprising question-answer pairs extracted from rigorous systematic reviews, we assess six LLMs, such as GPT and Mixtral, analyzing their classification and generation performance. Our experimental insights into LLM performance on the novel biomedical QA dataset reveal the still challenging nature of this task.
Read more6/11/2024
0
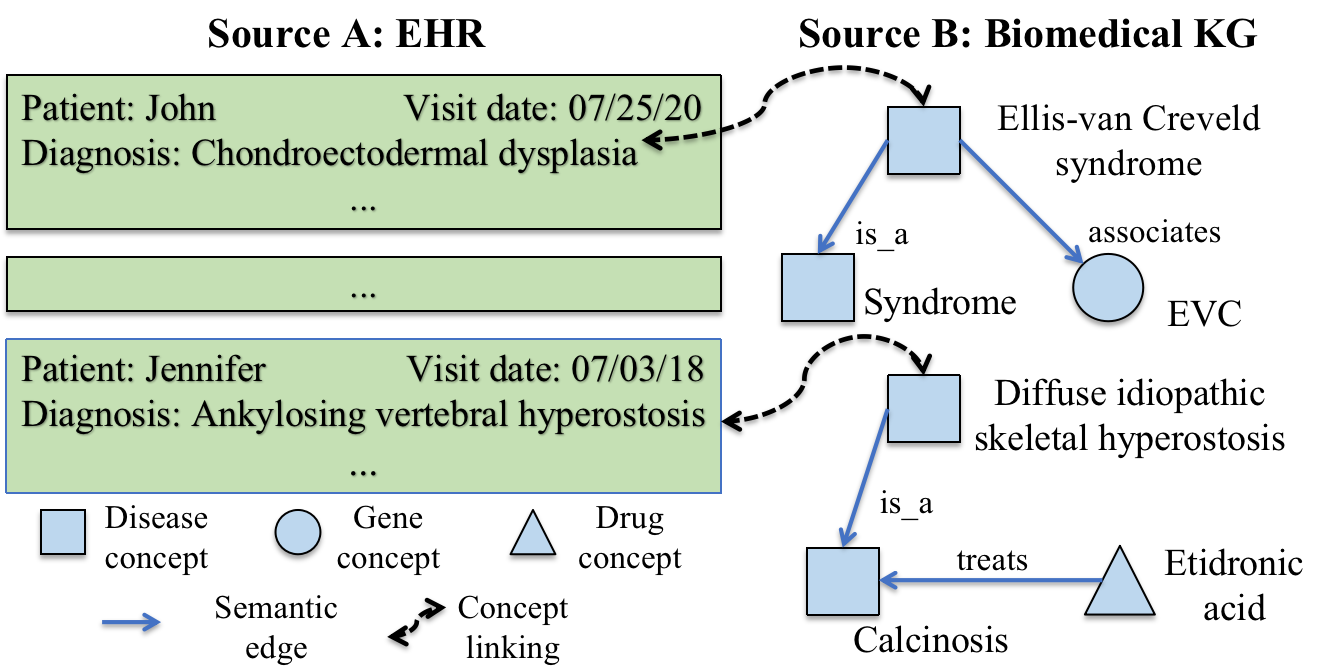
PromptLink: Leveraging Large Language Models for Cross-Source Biomedical Concept Linking
Yuzhang Xie, Jiaying Lu, Joyce Ho, Fadi Nahab, Xiao Hu, Carl Yang
Linking (aligning) biomedical concepts across diverse data sources enables various integrative analyses, but it is challenging due to the discrepancies in concept naming conventions. Various strategies have been developed to overcome this challenge, such as those based on string-matching rules, manually crafted thesauri, and machine learning models. However, these methods are constrained by limited prior biomedical knowledge and can hardly generalize beyond the limited amounts of rules, thesauri, or training samples. Recently, large language models (LLMs) have exhibited impressive results in diverse biomedical NLP tasks due to their unprecedentedly rich prior knowledge and strong zero-shot prediction abilities. However, LLMs suffer from issues including high costs, limited context length, and unreliable predictions. In this research, we propose PromptLink, a novel biomedical concept linking framework that leverages LLMs. It first employs a biomedical-specialized pre-trained language model to generate candidate concepts that can fit in the LLM context windows. Then it utilizes an LLM to link concepts through two-stage prompts, where the first-stage prompt aims to elicit the biomedical prior knowledge from the LLM for the concept linking task and the second-stage prompt enforces the LLM to reflect on its own predictions to further enhance their reliability. Empirical results on the concept linking task between two EHR datasets and an external biomedical KG demonstrate the effectiveness of PromptLink. Furthermore, PromptLink is a generic framework without reliance on additional prior knowledge, context, or training data, making it well-suited for concept linking across various types of data sources. The source code is available at https://github.com/constantjxyz/PromptLink.
Read more5/14/2024
💬
0
Exploring the Capabilities of Prompted Large Language Models in Educational and Assessment Applications
Subhankar Maity, Aniket Deroy, Sudeshna Sarkar
In the era of generative artificial intelligence (AI), the fusion of large language models (LLMs) offers unprecedented opportunities for innovation in the field of modern education. We embark on an exploration of prompted LLMs within the context of educational and assessment applications to uncover their potential. Through a series of carefully crafted research questions, we investigate the effectiveness of prompt-based techniques in generating open-ended questions from school-level textbooks, assess their efficiency in generating open-ended questions from undergraduate-level technical textbooks, and explore the feasibility of employing a chain-of-thought inspired multi-stage prompting approach for language-agnostic multiple-choice question (MCQ) generation. Additionally, we evaluate the ability of prompted LLMs for language learning, exemplified through a case study in the low-resource Indian language Bengali, to explain Bengali grammatical errors. We also evaluate the potential of prompted LLMs to assess human resource (HR) spoken interview transcripts. By juxtaposing the capabilities of LLMs with those of human experts across various educational tasks and domains, our aim is to shed light on the potential and limitations of LLMs in reshaping educational practices.
Read more5/21/2024