On the Utility of 3D Hand Poses for Action Recognition

0

Sign in to get full access
Overview
- This paper investigates the utility of 3D hand poses for action recognition tasks.
- The authors propose a multimodal transformer-based model that combines full-body skeleton and 3D hand pose information to improve action recognition performance.
- Experiments are conducted on two standard action recognition datasets to evaluate the effectiveness of the proposed approach.
Plain English Explanation
The paper examines whether incorporating information about the 3D position and movement of a person's hands can improve the accuracy of systems that recognize human actions or activities. The researchers developed a new machine learning model that takes in both full-body skeleton data (the 3D locations of major joints) and detailed 3D hand pose information. They tested this model on standard benchmark datasets for action recognition, and found that adding the hand pose data led to better performance compared to using just the full-body skeleton alone.
The key idea is that the movements and positions of a person's hands often provide important cues about what action they are performing, beyond what can be inferred from the overall body pose. For example, the way someone's hands grip and manipulate objects could reveal if they are cooking, playing an instrument, or shaking someone's hand. By incorporating this additional "hand-centric" information, the model is better able to distinguish between different types of actions.
Technical Explanation
The paper proposes a multimodal transformer-based architecture that takes as input both full-body 3D skeleton data and 3D hand pose information. The skeleton data captures the 3D positions of 17 major body joints over time, while the hand pose data specifies the 3D locations of 21 joints in each hand.
The model first processes the skeleton and hand pose data through separate transformer encoder modules to extract relevant features from each modality. These features are then concatenated and passed through additional transformer layers to learn multimodal representations that capture the interactions between the full-body and hand-centric information.
The authors evaluate their approach on two popular action recognition datasets, NTU RGB+D 60 and NTU RGB+D 120. They show that their multimodal model outperforms baseline methods that use only skeleton data or only hand pose data, demonstrating the complementary value of these two modalities for action recognition. Further analysis indicates that the hand pose information is particularly beneficial for discriminating between actions involving object manipulation or fine hand movements.
Critical Analysis
The paper provides a compelling demonstration of how 3D hand pose data can enhance the performance of skeleton-based action recognition systems. The technical approach is well-designed and the experimental results are thorough and convincing.
That said, the paper does not explore the limitations or potential drawbacks of the proposed method. For example, it is unclear how the model would perform in real-world scenarios with noisy or incomplete hand pose estimates, or how it would scale to larger and more diverse action recognition datasets.
Additionally, the paper does not discuss the computational and memory requirements of the multimodal transformer architecture, which could be an important practical consideration for deploying such models in resource-constrained settings.
Further research could investigate ways to make the hand pose-enriched action recognition more robust, efficient, and generalizable. Exploring novel network architectures or training techniques tailored to leverage hand-centric information could also be a fruitful direction.
Conclusion
This paper presents a strong case for the value of 3D hand pose data in improving skeleton-based action recognition. By developing a multimodal transformer model that effectively combines full-body and hand-centric information, the authors show consistent performance gains over approaches relying on just skeleton data.
The findings highlight the importance of considering hand movements and manipulations when modeling human actions, and suggest that future action recognition systems could benefit from integrating both holistic body pose and detailed hand pose information. This work lays the groundwork for further research into more advanced multimodal approaches to this key computer vision task.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the Utility of 3D Hand Poses for Action Recognition
Md Salman Shamil, Dibyadip Chatterjee, Fadime Sener, Shugao Ma, Angela Yao
3D hand pose is an underexplored modality for action recognition. Poses are compact yet informative and can greatly benefit applications with limited compute budgets. However, poses alone offer an incomplete understanding of actions, as they cannot fully capture objects and environments with which humans interact. We propose HandFormer, a novel multimodal transformer, to efficiently model hand-object interactions. HandFormer combines 3D hand poses at a high temporal resolution for fine-grained motion modeling with sparsely sampled RGB frames for encoding scene semantics. Observing the unique characteristics of hand poses, we temporally factorize hand modeling and represent each joint by its short-term trajectories. This factorized pose representation combined with sparse RGB samples is remarkably efficient and highly accurate. Unimodal HandFormer with only hand poses outperforms existing skeleton-based methods at 5x fewer FLOPs. With RGB, we achieve new state-of-the-art performance on Assembly101 and H2O with significant improvements in egocentric action recognition.
Read more8/15/2024
0
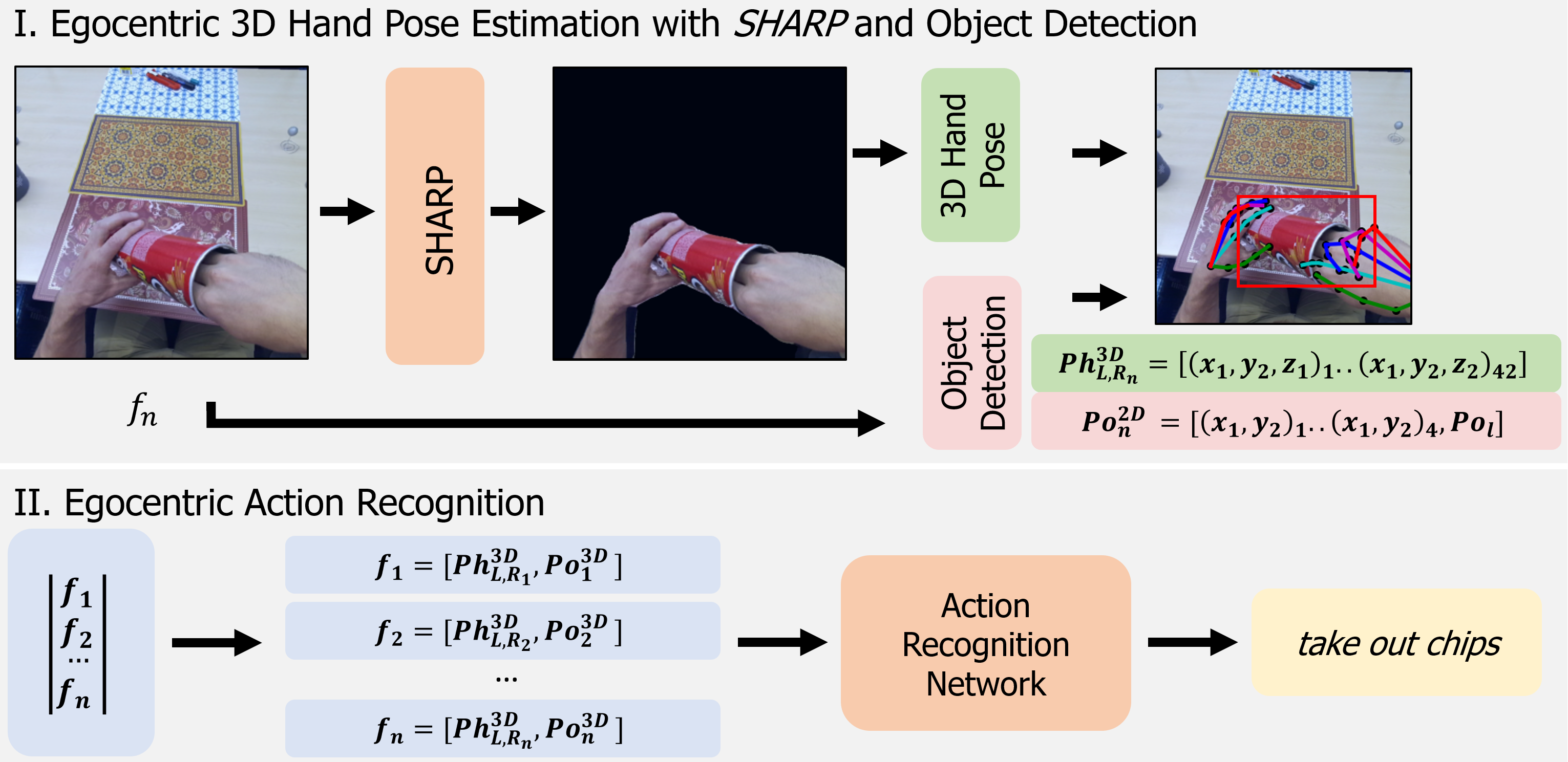
SHARP: Segmentation of Hands and Arms by Range using Pseudo-Depth for Enhanced Egocentric 3D Hand Pose Estimation and Action Recognition
Wiktor Mucha, Michael Wray, Martin Kampel
Hand pose represents key information for action recognition in the egocentric perspective, where the user is interacting with objects. We propose to improve egocentric 3D hand pose estimation based on RGB frames only by using pseudo-depth images. Incorporating state-of-the-art single RGB image depth estimation techniques, we generate pseudo-depth representations of the frames and use distance knowledge to segment irrelevant parts of the scene. The resulting depth maps are then used as segmentation masks for the RGB frames. Experimental results on H2O Dataset confirm the high accuracy of the estimated pose with our method in an action recognition task. The 3D hand pose, together with information from object detection, is processed by a transformer-based action recognition network, resulting in an accuracy of 91.73%, outperforming all state-of-the-art methods. Estimations of 3D hand pose result in competitive performance with existing methods with a mean pose error of 28.66 mm. This method opens up new possibilities for employing distance information in egocentric 3D hand pose estimation without relying on depth sensors.
Read more8/20/2024

0
In My Perspective, In My Hands: Accurate Egocentric 2D Hand Pose and Action Recognition
Wiktor Mucha, Martin Kampel
Action recognition is essential for egocentric video understanding, allowing automatic and continuous monitoring of Activities of Daily Living (ADLs) without user effort. Existing literature focuses on 3D hand pose input, which requires computationally intensive depth estimation networks or wearing an uncomfortable depth sensor. In contrast, there has been insufficient research in understanding 2D hand pose for egocentric action recognition, despite the availability of user-friendly smart glasses in the market capable of capturing a single RGB image. Our study aims to fill this research gap by exploring the field of 2D hand pose estimation for egocentric action recognition, making two contributions. Firstly, we introduce two novel approaches for 2D hand pose estimation, namely EffHandNet for single-hand estimation and EffHandEgoNet, tailored for an egocentric perspective, capturing interactions between hands and objects. Both methods outperform state-of-the-art models on H2O and FPHA public benchmarks. Secondly, we present a robust action recognition architecture from 2D hand and object poses. This method incorporates EffHandEgoNet, and a transformer-based action recognition method. Evaluated on H2O and FPHA datasets, our architecture has a faster inference time and achieves an accuracy of 91.32% and 94.43%, respectively, surpassing state of the art, including 3D-based methods. Our work demonstrates that using 2D skeletal data is a robust approach for egocentric action understanding. Extensive evaluation and ablation studies show the impact of the hand pose estimation approach, and how each input affects the overall performance.
Read more7/25/2024
❗
0
Generative Hierarchical Temporal Transformer for Hand Pose and Action Modeling
Yilin Wen, Hao Pan, Takehiko Ohkawa, Lei Yang, Jia Pan, Yoichi Sato, Taku Komura, Wenping Wang
We present a novel unified framework that concurrently tackles recognition and future prediction for human hand pose and action modeling. Previous works generally provide isolated solutions for either recognition or prediction, which not only increases the complexity of integration in practical applications, but more importantly, cannot exploit the synergy of both sides and suffer suboptimal performances in their respective domains. To address this problem, we propose a generative Transformer VAE architecture to model hand pose and action, where the encoder and decoder capture recognition and prediction respectively, and their connection through the VAE bottleneck mandates the learning of consistent hand motion from the past to the future and vice versa. Furthermore, to faithfully model the semantic dependency and different temporal granularity of hand pose and action, we decompose the framework into two cascaded VAE blocks: the first and latter blocks respectively model the short-span poses and long-span action, and are connected by a mid-level feature representing a sub-second series of hand poses. This decomposition into block cascades facilitates capturing both short-term and long-term temporal regularity in pose and action modeling, and enables training two blocks separately to fully utilize datasets with annotations of different temporal granularities. We train and evaluate our framework across multiple datasets; results show that our joint modeling of recognition and prediction improves over isolated solutions, and that our semantic and temporal hierarchy facilitates long-term pose and action modeling.
Read more9/10/2024