Utilizing Local Hierarchy with Adversarial Training for Hierarchical Text Classification

0

Sign in to get full access
Overview
- This paper proposes a new method for hierarchical text classification, which is the task of assigning text to categories organized in a hierarchical structure.
- The proposed approach combines adversarial training, which improves model robustness, with leveraging the local hierarchy between categories to enhance classification performance.
- The authors evaluate their method on several benchmark datasets and demonstrate improved results compared to existing hierarchical text classification techniques.
Plain English Explanation
The paper addresses the problem of hierarchical text classification, where you have a set of categories organized into a tree-like structure, and the goal is to correctly assign a piece of text (like an article or document) to the appropriate category.
The key idea is to use a machine learning technique called adversarial training, which helps make the model more robust and able to handle difficult or ambiguous inputs. The adversarial training is combined with a way to explicitly take advantage of the local relationships between categories in the hierarchy.
For example, if you have a category for "Pets" that contains subcategories like "Dogs" and "Cats", the model can learn that "Dogs" and "Cats" are closely related and use that information to improve the overall classification performance.
The authors evaluate their approach on several standard benchmark datasets for hierarchical text classification and show that it outperforms previous methods. This suggests the proposed technique is an effective way to tackle this important real-world problem, with applications in areas like organizing news articles, product catalogs, or scientific literature.
Technical Explanation
The paper presents a novel hierarchical text classification model that combines adversarial training with exploiting the local hierarchy between categories. The key components are:
-
Adversarial training: The model is trained not only on the original data, but also on adversarial examples - slightly perturbed versions of the inputs designed to fool the model. This makes the model more robust to variations in the input text.
-
Local hierarchy modeling: The model learns representations that capture the semantic relationships between categories, especially those that are closely related in the hierarchy. This allows the model to leverage the hierarchical structure to improve classification accuracy.
The proposed architecture includes an encoder that maps text into a vector representation, and a classifier that predicts the category based on this representation. During training, the classifier is optimized not only for the original examples, but also for the adversarial examples generated by perturbing the input.
The authors evaluate their approach on several benchmark datasets for hierarchical text classification, including news articles, product catalogs, and medical literature. They demonstrate that their method outperforms previous state-of-the-art techniques, highlighting the benefits of combining adversarial training and local hierarchy modeling for this task.
Critical Analysis
The paper makes a compelling case for the effectiveness of the proposed hierarchical text classification approach. The combination of adversarial training and local hierarchy modeling is a novel contribution that builds upon previous work in this area.
One potential limitation is that the paper does not provide a detailed ablation study to tease apart the individual contributions of the adversarial training and local hierarchy components. It would be helpful to understand how much each of these elements is driving the performance improvements.
Additionally, the paper focuses on evaluating the method on standard benchmark datasets, but does not discuss potential real-world deployment challenges or considerations around model interpretability and explainability. These are important factors to consider for practical applications of the technology.
Overall, the research presents a solid technical advance in hierarchical text classification, but could benefit from further analysis and discussion of the broader implications and practical considerations of the work.
Conclusion
This paper introduces a new approach for hierarchical text classification that leverages adversarial training and local hierarchy modeling to achieve state-of-the-art performance on benchmark datasets. By making the model more robust to input variations and better able to capture the relationships between categories, the proposed method represents an important step forward in this fundamental machine learning problem.
The findings have potential applications in areas like content organization, information retrieval, and knowledge management, where being able to accurately classify text into hierarchical taxonomies is crucial. While the technical details are complex, the core ideas behind the research are intuitive and could inspire further work on enhancing hierarchical classification systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Utilizing Local Hierarchy with Adversarial Training for Hierarchical Text Classification
Zihan Wang, Peiyi Wang, Houfeng Wang
Hierarchical text classification (HTC) is a challenging subtask of multi-label classification due to its complex taxonomic structure. Nearly all recent HTC works focus on how the labels are structured but ignore the sub-structure of ground-truth labels according to each input text which contains fruitful label co-occurrence information. In this work, we introduce this local hierarchy with an adversarial framework. We propose a HiAdv framework that can fit in nearly all HTC models and optimize them with the local hierarchy as auxiliary information. We test on two typical HTC models and find that HiAdv is effective in all scenarios and is adept at dealing with complex taxonomic hierarchies. Further experiments demonstrate that the promotion of our framework indeed comes from the local hierarchy and the local hierarchy is beneficial for rare classes which have insufficient training data.
Read more4/1/2024
0
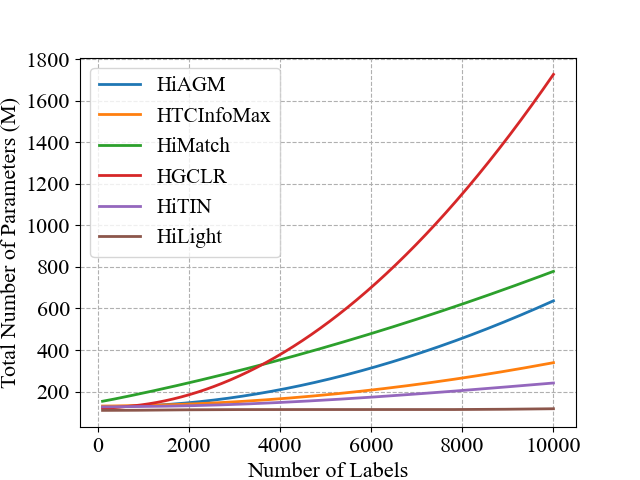
HiLight: A Hierarchy-aware Light Global Model with Hierarchical Local ConTrastive Learning
Zhijian Chen, Zhonghua Li, Jianxin Yang, Ye Qi
Hierarchical text classification (HTC) is a special sub-task of multi-label classification (MLC) whose taxonomy is constructed as a tree and each sample is assigned with at least one path in the tree. Latest HTC models contain three modules: a text encoder, a structure encoder and a multi-label classification head. Specially, the structure encoder is designed to encode the hierarchy of taxonomy. However, the structure encoder has scale problem. As the taxonomy size increases, the learnable parameters of recent HTC works grow rapidly. Recursive regularization is another widely-used method to introduce hierarchical information but it has collapse problem and generally relaxed by assigning with a small weight (ie. 1e-6). In this paper, we propose a Hierarchy-aware Light Global model with Hierarchical local conTrastive learning (HiLight), a lightweight and efficient global model only consisting of a text encoder and a multi-label classification head. We propose a new learning task to introduce the hierarchical information, called Hierarchical Local Contrastive Learning (HiLCL). Extensive experiments are conducted on two benchmark datasets to demonstrate the effectiveness of our model.
Read more8/13/2024
0
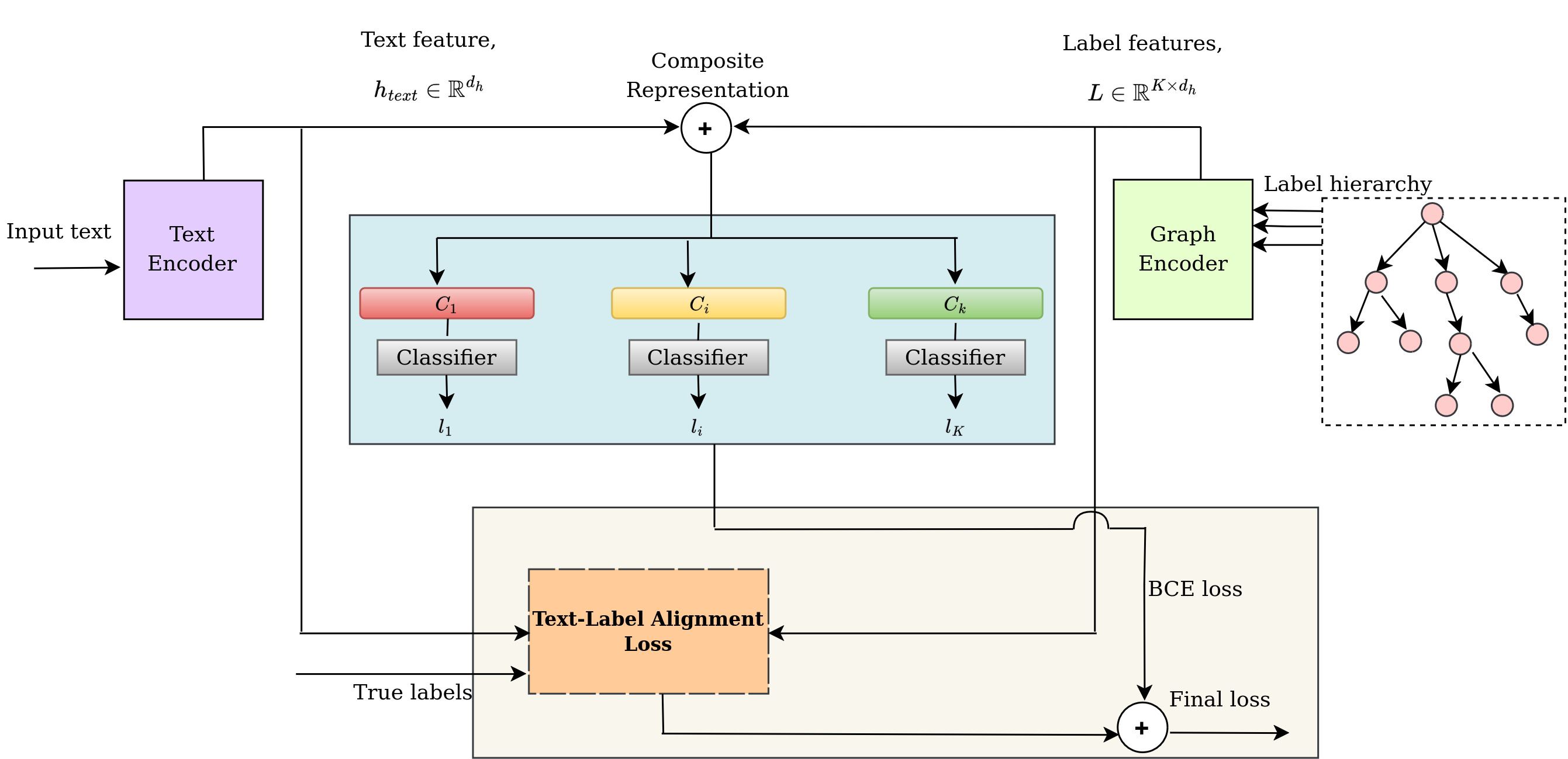
Modeling Text-Label Alignment for Hierarchical Text Classification
Ashish Kumar, Durga Toshniwal
Hierarchical Text Classification (HTC) aims to categorize text data based on a structured label hierarchy, resulting in predicted labels forming a sub-hierarchy tree. The semantics of the text should align with the semantics of the labels in this sub-hierarchy. With the sub-hierarchy changing for each sample, the dynamic nature of text-label alignment poses challenges for existing methods, which typically process text and labels independently. To overcome this limitation, we propose a Text-Label Alignment (TLA) loss specifically designed to model the alignment between text and labels. We obtain a set of negative labels for a given text and its positive label set. By leveraging contrastive learning, the TLA loss pulls the text closer to its positive label and pushes it away from its negative label in the embedding space. This process aligns text representations with related labels while distancing them from unrelated ones. Building upon this framework, we introduce the Hierarchical Text-Label Alignment (HTLA) model, which leverages BERT as the text encoder and GPTrans as the graph encoder and integrates text-label embeddings to generate hierarchy-aware representations. Experimental results on benchmark datasets and comparison with existing baselines demonstrate the effectiveness of HTLA for HTC.
Read more9/4/2024

0
Domain-Hierarchy Adaptation via Chain of Iterative Reasoning for Few-shot Hierarchical Text Classification
Ke Ji, Peng Wang, Wenjun Ke, Guozheng Li, Jiajun Liu, Jingsheng Gao, Ziyu Shang
Recently, various pre-trained language models (PLMs) have been proposed to prove their impressive performances on a wide range of few-shot tasks. However, limited by the unstructured prior knowledge in PLMs, it is difficult to maintain consistent performance on complex structured scenarios, such as hierarchical text classification (HTC), especially when the downstream data is extremely scarce. The main challenge is how to transfer the unstructured semantic space in PLMs to the downstream domain hierarchy. Unlike previous work on HTC which directly performs multi-label classification or uses graph neural network (GNN) to inject label hierarchy, in this work, we study the HTC problem under a few-shot setting to adapt knowledge in PLMs from an unstructured manner to the downstream hierarchy. Technically, we design a simple yet effective method named Hierarchical Iterative Conditional Random Field (HierICRF) to search the most domain-challenging directions and exquisitely crafts domain-hierarchy adaptation as a hierarchical iterative language modeling problem, and then it encourages the model to make hierarchical consistency self-correction during the inference, thereby achieving knowledge transfer with hierarchical consistency preservation. We perform HierICRF on various architectures, and extensive experiments on two popular HTC datasets demonstrate that prompt with HierICRF significantly boosts the few-shot HTC performance with an average Micro-F1 by 28.80% to 1.50% and Macro-F1 by 36.29% to 1.5% over the previous state-of-the-art (SOTA) baselines under few-shot settings, while remaining SOTA hierarchical consistency performance.
Read more7/15/2024