Utilizing Speaker Profiles for Impersonation Audio Detection

0

Sign in to get full access
Overview
- The paper proposes a new approach for detecting impersonation audio using speaker profiles.
- It introduces a dataset of impersonation audio samples and evaluates the proposed method on this dataset.
- The key idea is to leverage a speaker's unique voice characteristics to distinguish authentic audio from impersonation attempts.
Plain English Explanation
The paper discusses a technique for detecting when someone is trying to impersonate another person's voice in an audio recording. This is an important problem, as AI-generated "deepfake" audio can be used to create convincing fake audio of a person saying something they didn't actually say.
The researchers created a dataset of impersonation audio samples, where people tried to mimic the voices of different speakers. They then developed a method that analyzes the unique "voice profile" of each speaker to identify if an audio sample is authentic or an impersonation attempt.
The core insight is that each person has a distinctive way of speaking - things like their pitch, tone, pronunciation, and vocal mannerisms. By building a detailed profile of a speaker's unique voice characteristics, the system can detect when an impersonator is trying to mimic those characteristics but failing to fully replicate them.
This approach allows the system to go beyond just detecting obvious audio distortions or low quality that might indicate a deepfake. Instead, it can identify more subtle differences that give away an impersonation, even if the audio quality is high.
Technical Explanation
The paper introduces a new Impersonation Audio Dataset containing audio samples of people impersonating various speakers. This dataset is used to evaluate the proposed Speaker Profile-based Impersonation Audio Detection approach.
The key innovation is the use of detailed speaker profiles to characterize each speaker's unique voice. These profiles capture low-level acoustic features as well as higher-level attributes like speaking style and pronunciation.
During inference, the system compares the input audio to the speaker's profile to assess whether it matches the authentic voice or displays signs of impersonation. This allows the detection to go beyond just identifying audio quality issues and instead focus on subtle differences in the underlying voice characteristics.
The paper evaluates this approach on the impersonation dataset and shows that it outperforms baseline audio deepfake detection methods. The results indicate that leveraging detailed speaker profiles can be an effective way to combat impersonation attacks.
Critical Analysis
The paper presents a novel and promising approach to the important problem of impersonation audio detection. By focusing on the unique voice characteristics of each speaker, rather than just general audio quality, the method seems well-suited to handling high-quality impersonation attempts.
However, the paper does note some limitations of the current work. The Impersonation Audio Dataset is relatively small, and the paper suggests expanding it to improve the robustness of the approach. Additionally, the speaker profile extraction process could potentially be further optimized for efficiency.
It would also be valuable to test the method's generalization to real-world impersonation attempts, as the current evaluation is limited to a specific dataset. Assessing performance on a wider range of impersonation styles and audio conditions would help validate the practical applicability of the approach.
Overall, this research represents an important step forward in combating the growing threat of audio deepfakes and impersonation attacks. With further refinement and validation, the speaker profile-based detection technique could become a valuable tool in the fight against these emerging AI-powered deception threats.
Conclusion
This paper proposes a novel approach for detecting impersonation audio by leveraging detailed speaker profiles. The key insight is that each person's unique voice characteristics can be used to distinguish authentic audio from impersonation attempts, even if the audio quality is high.
The researchers introduce a new impersonation audio dataset and demonstrate that their speaker profile-based method outperforms baseline audio deepfake detection techniques. While the work has some limitations that require further research, it represents an important step forward in combating the growing threat of AI-generated audio impersonation.
As audio deepfakes become more sophisticated, innovative approaches like this will be crucial for preserving trust and authenticity in our digital communications. By focusing on the underlying voice signatures of individuals, this research opens up new avenues for robust impersonation detection that can adapt to evolving AI-powered deception threats.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Utilizing Speaker Profiles for Impersonation Audio Detection
Hao Gu, JiangYan Yi, Chenglong Wang, Yong Ren, Jianhua Tao, Xinrui Yan, Yujie Chen, Xiaohui Zhang
Fake audio detection is an emerging active topic. A growing number of literatures have aimed to detect fake utterance, which are mostly generated by Text-to-speech (TTS) or voice conversion (VC). However, countermeasures against impersonation remain an underexplored area. Impersonation is a fake type that involves an imitator replicating specific traits and speech style of a target speaker. Unlike TTS and VC, which often leave digital traces or signal artifacts, impersonation involves live human beings producing entirely natural speech, rendering the detection of impersonation audio a challenging task. Thus, we propose a novel method that integrates speaker profiles into the process of impersonation audio detection. Speaker profiles are inherent characteristics that are challenging for impersonators to mimic accurately, such as speaker's age, job. We aim to leverage these features to extract discriminative information for detecting impersonation audio. Moreover, there is no large impersonated speech corpora available for quantitative study of impersonation impacts. To address this gap, we further design the first large-scale, diverse-speaker Chinese impersonation dataset, named ImPersonation Audio Detection (IPAD), to advance the community's research on impersonation audio detection. We evaluate several existing fake audio detection methods on our proposed dataset IPAD, demonstrating its necessity and the challenges. Additionally, our findings reveal that incorporating speaker profiles can significantly enhance the model's performance in detecting impersonation audio.
Read more9/2/2024
🌀
0
Audio Anti-Spoofing Detection: A Survey
Menglu Li, Yasaman Ahmadiadli, Xiao-Ping Zhang
The availability of smart devices leads to an exponential increase in multimedia content. However, the rapid advancements in deep learning have given rise to sophisticated algorithms capable of manipulating or creating multimedia fake content, known as Deepfake. Audio Deepfakes pose a significant threat by producing highly realistic voices, thus facilitating the spread of misinformation. To address this issue, numerous audio anti-spoofing detection challenges have been organized to foster the development of anti-spoofing countermeasures. This survey paper presents a comprehensive review of every component within the detection pipeline, including algorithm architectures, optimization techniques, application generalizability, evaluation metrics, performance comparisons, available datasets, and open-source availability. For each aspect, we conduct a systematic evaluation of the recent advancements, along with discussions on existing challenges. Additionally, we also explore emerging research topics on audio anti-spoofing, including partial spoofing detection, cross-dataset evaluation, and adversarial attack defence, while proposing some promising research directions for future work. This survey paper not only identifies the current state-of-the-art to establish strong baselines for future experiments but also guides future researchers on a clear path for understanding and enhancing the audio anti-spoofing detection mechanisms.
Read more4/23/2024
🔎
0
Does Audio Deepfake Detection Generalize?
Nicolas M. Muller, Pavel Czempin, Franziska Dieckmann, Adam Froghyar, Konstantin Bottinger
Current text-to-speech algorithms produce realistic fakes of human voices, making deepfake detection a much-needed area of research. While researchers have presented various techniques for detecting audio spoofs, it is often unclear exactly why these architectures are successful: Preprocessing steps, hyperparameter settings, and the degree of fine-tuning are not consistent across related work. Which factors contribute to success, and which are accidental? In this work, we address this problem: We systematize audio spoofing detection by re-implementing and uniformly evaluating architectures from related work. We identify overarching features for successful audio deepfake detection, such as using cqtspec or logspec features instead of melspec features, which improves performance by 37% EER on average, all other factors constant. Additionally, we evaluate generalization capabilities: We collect and publish a new dataset consisting of 37.9 hours of found audio recordings of celebrities and politicians, of which 17.2 hours are deepfakes. We find that related work performs poorly on such real-world data (performance degradation of up to one thousand percent). This may suggest that the community has tailored its solutions too closely to the prevailing ASVSpoof benchmark and that deepfakes are much harder to detect outside the lab than previously thought.
Read more8/28/2024
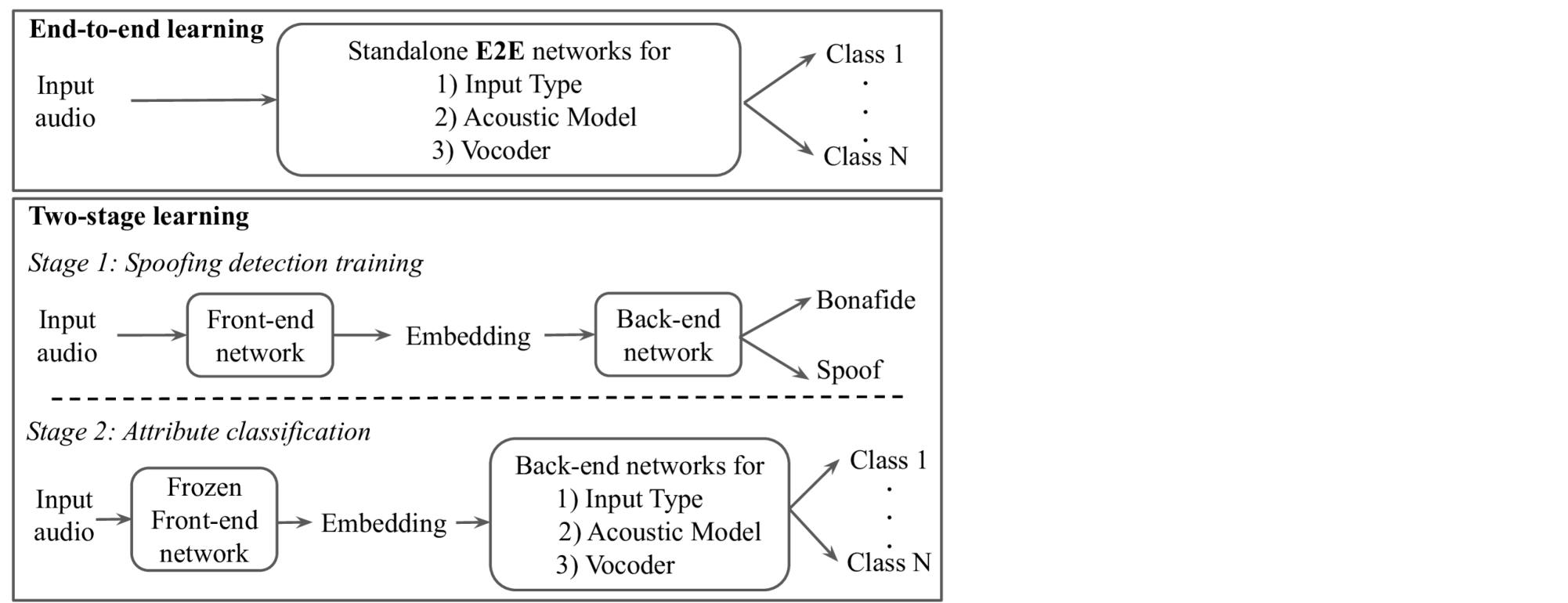
0
Source Tracing of Audio Deepfake Systems
Nicholas Klein, Tianxiang Chen, Hemlata Tak, Ricardo Casal, Elie Khoury
Recent progress in generative AI technology has made audio deepfakes remarkably more realistic. While current research on anti-spoofing systems primarily focuses on assessing whether a given audio sample is fake or genuine, there has been limited attention on discerning the specific techniques to create the audio deepfakes. Algorithms commonly used in audio deepfake generation, like text-to-speech (TTS) and voice conversion (VC), undergo distinct stages including input processing, acoustic modeling, and waveform generation. In this work, we introduce a system designed to classify various spoofing attributes, capturing the distinctive features of individual modules throughout the entire generation pipeline. We evaluate our system on two datasets: the ASVspoof 2019 Logical Access and the Multi-Language Audio Anti-Spoofing Dataset (MLAAD). Results from both experiments demonstrate the robustness of the system to identify the different spoofing attributes of deepfake generation systems.
Read more7/12/2024