V2A-Mark: Versatile Deep Visual-Audio Watermarking for Manipulation Localization and Copyright Protection
2404.16824
0
0
🤿
Abstract
AI-generated video has revolutionized short video production, filmmaking, and personalized media, making video local editing an essential tool. However, this progress also blurs the line between reality and fiction, posing challenges in multimedia forensics. To solve this urgent issue, V2A-Mark is proposed to address the limitations of current video tampering forensics, such as poor generalizability, singular function, and single modality focus. Combining the fragility of video-into-video steganography with deep robust watermarking, our method can embed invisible visual-audio localization watermarks and copyright watermarks into the original video frames and audio, enabling precise manipulation localization and copyright protection. We also design a temporal alignment and fusion module and degradation prompt learning to enhance the localization accuracy and decoding robustness. Meanwhile, we introduce a sample-level audio localization method and a cross-modal copyright extraction mechanism to couple the information of audio and video frames. The effectiveness of V2A-Mark has been verified on a visual-audio tampering dataset, emphasizing its superiority in localization precision and copyright accuracy, crucial for the sustainable development of video editing in the AIGC video era.
Create account to get full access
Overview
- AI-generated video has revolutionized short video production, filmmaking, and personalized media, making video local editing an essential tool.
- However, this progress also blurs the line between reality and fiction, posing challenges in multimedia forensics.
- To address this issue, V2A-Mark is proposed to improve upon the limitations of current video tampering forensics.
Plain English Explanation
The rise of AI-powered video creation has transformed the world of short videos, movies, and personalized media. Video local editing has become a crucial tool in this new landscape. However, this technological advancement has also created a challenge - it's becoming harder to distinguish real video content from AI-generated or manipulated content. This blurring of the line between reality and fiction poses a problem for multimedia forensics, the field that investigates the authenticity of digital media.
To tackle this urgent issue, researchers have developed a new method called V2A-Mark. This approach aims to overcome the limitations of current video tampering forensics, such as poor generalizability, singular function, and sole focus on a single type of media (e.g., only video or only audio). V2A-Mark combines the strengths of two techniques: the fragility of video-into-video steganography and the robustness of deep watermarking. By embedding invisible visual-audio localization watermarks and copyright watermarks into the original video frames and audio, V2A-Mark enables precise localization of any tampering and helps protect the content's copyright.
The researchers have also designed additional components to enhance the method's performance, such as a temporal alignment and fusion module, as well as a degradation prompt learning mechanism. These innovations improve the localization accuracy and decoding robustness. Furthermore, V2A-Mark incorporates a sample-level audio localization method and a cross-modal copyright extraction mechanism to leverage the information from both video frames and audio.
Technical Explanation
The V2A-Mark method aims to address the limitations of current video tampering forensics, such as poor generalizability, singular function, and sole focus on a single modality (e.g., only video or only audio). By combining the fragility of video-into-video steganography with deep robust watermarking, V2A-Mark can embed invisible visual-audio localization watermarks and copyright watermarks into the original video frames and audio. This enables precise manipulation localization and copyright protection.
To enhance the method's performance, the researchers designed a temporal alignment and fusion module, as well as a degradation prompt learning mechanism. The temporal alignment and fusion module helps improve the localization accuracy by aligning and fusing the information from video and audio. The degradation prompt learning component enhances the decoding robustness by learning to handle various types of degradations that the watermarks may encounter.
Additionally, V2A-Mark incorporates a sample-level audio localization method and a cross-modal copyright extraction mechanism. The sample-level audio localization method enables precise localization of tampering in the audio domain, while the cross-modal copyright extraction mechanism couples the information from both video frames and audio to provide robust copyright protection.
The effectiveness of V2A-Mark has been verified on a visual-audio tampering dataset, demonstrating its superiority in localization precision and copyright accuracy. These capabilities are crucial for the sustainable development of video editing in the AI-generated content (AIGC) video era, where the ability to authenticate and protect digital media is paramount.
Critical Analysis
The V2A-Mark method represents a significant advancement in video tampering forensics, addressing the limitations of current approaches. However, the paper does not provide a comprehensive discussion of the potential limitations or caveats of the proposed method.
For instance, the paper does not explore the impact of different types of video and audio manipulations on the method's performance. It would be valuable to understand how V2A-Mark handles more sophisticated tampering techniques, such as adversarial attacks or complex video editing workflows.
Additionally, the paper does not mention the computational and storage overhead associated with the V2A-Mark method. As video editing and personalization become more prevalent, the scalability and efficiency of the forensic technique will be crucial for real-world deployment.
Furthermore, the paper does not discuss the potential privacy implications of embedding watermarks in user-generated content. While the watermarks are designed to be invisible, there may be concerns about the unauthorized detection or extraction of these marks, which could raise ethical considerations.
Despite these potential limitations, the V2A-Mark method represents a significant step forward in addressing the challenges posed by the rise of AI-generated video content. Continued research and development in this area will be crucial for maintaining the integrity and trust in multimedia content in the years to come.
Conclusion
The V2A-Mark method offers a promising solution to the challenges faced in video tampering forensics, which have become increasingly important due to the rapid progress in AI-generated video content. By combining the fragility of video-into-video steganography with deep robust watermarking, V2A-Mark can embed invisible visual-audio localization watermarks and copyright watermarks into original video frames and audio. This enables precise manipulation localization and robust copyright protection, addressing the limitations of current forensic approaches.
The technical innovations, such as the temporal alignment and fusion module, degradation prompt learning, sample-level audio localization, and cross-modal copyright extraction, further enhance the method's performance. The verified effectiveness of V2A-Mark on a visual-audio tampering dataset highlights its potential to play a crucial role in the sustainable development of video editing and personalization in the AIGC video era, where the ability to authenticate and protect digital media is paramount.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
Are Watermarks Bugs for Deepfake Detectors? Rethinking Proactive Forensics
Xiaoshuai Wu, Xin Liao, Bo Ou, Yuling Liu, Zheng Qin
0
0
AI-generated content has accelerated the topic of media synthesis, particularly Deepfake, which can manipulate our portraits for positive or malicious purposes. Before releasing these threatening face images, one promising forensics solution is the injection of robust watermarks to track their own provenance. However, we argue that current watermarking models, originally devised for genuine images, may harm the deployed Deepfake detectors when directly applied to forged images, since the watermarks are prone to overlap with the forgery signals used for detection. To bridge this gap, we thus propose AdvMark, on behalf of proactive forensics, to exploit the adversarial vulnerability of passive detectors for good. Specifically, AdvMark serves as a plug-and-play procedure for fine-tuning any robust watermarking into adversarial watermarking, to enhance the forensic detectability of watermarked images; meanwhile, the watermarks can still be extracted for provenance tracking. Extensive experiments demonstrate the effectiveness of the proposed AdvMark, leveraging robust watermarking to fool Deepfake detectors, which can help improve the accuracy of downstream Deepfake detection without tuning the in-the-wild detectors. We believe this work will shed some light on the harmless proactive forensics against Deepfake.
4/30/2024
🔎
Proactive Detection of Voice Cloning with Localized Watermarking
Robin San Roman, Pierre Fernandez, Alexandre D'efossez, Teddy Furon, Tuan Tran, Hady Elsahar
0
0
In the rapidly evolving field of speech generative models, there is a pressing need to ensure audio authenticity against the risks of voice cloning. We present AudioSeal, the first audio watermarking technique designed specifically for localized detection of AI-generated speech. AudioSeal employs a generator/detector architecture trained jointly with a localization loss to enable localized watermark detection up to the sample level, and a novel perceptual loss inspired by auditory masking, that enables AudioSeal to achieve better imperceptibility. AudioSeal achieves state-of-the-art performance in terms of robustness to real life audio manipulations and imperceptibility based on automatic and human evaluation metrics. Additionally, AudioSeal is designed with a fast, single-pass detector, that significantly surpasses existing models in speed - achieving detection up to two orders of magnitude faster, making it ideal for large-scale and real-time applications.
6/7/2024

AudioMarkBench: Benchmarking Robustness of Audio Watermarking
Hongbin Liu, Moyang Guo, Zhengyuan Jiang, Lun Wang, Neil Zhenqiang Gong
0
0
The increasing realism of synthetic speech, driven by advancements in text-to-speech models, raises ethical concerns regarding impersonation and disinformation. Audio watermarking offers a promising solution via embedding human-imperceptible watermarks into AI-generated audios. However, the robustness of audio watermarking against common/adversarial perturbations remains understudied. We present AudioMarkBench, the first systematic benchmark for evaluating the robustness of audio watermarking against watermark removal and watermark forgery. AudioMarkBench includes a new dataset created from Common-Voice across languages, biological sexes, and ages, 3 state-of-the-art watermarking methods, and 15 types of perturbations. We benchmark the robustness of these methods against the perturbations in no-box, black-box, and white-box settings. Our findings highlight the vulnerabilities of current watermarking techniques and emphasize the need for more robust and fair audio watermarking solutions. Our dataset and code are publicly available at url{https://github.com/moyangkuo/AudioMarkBench}.
6/12/2024
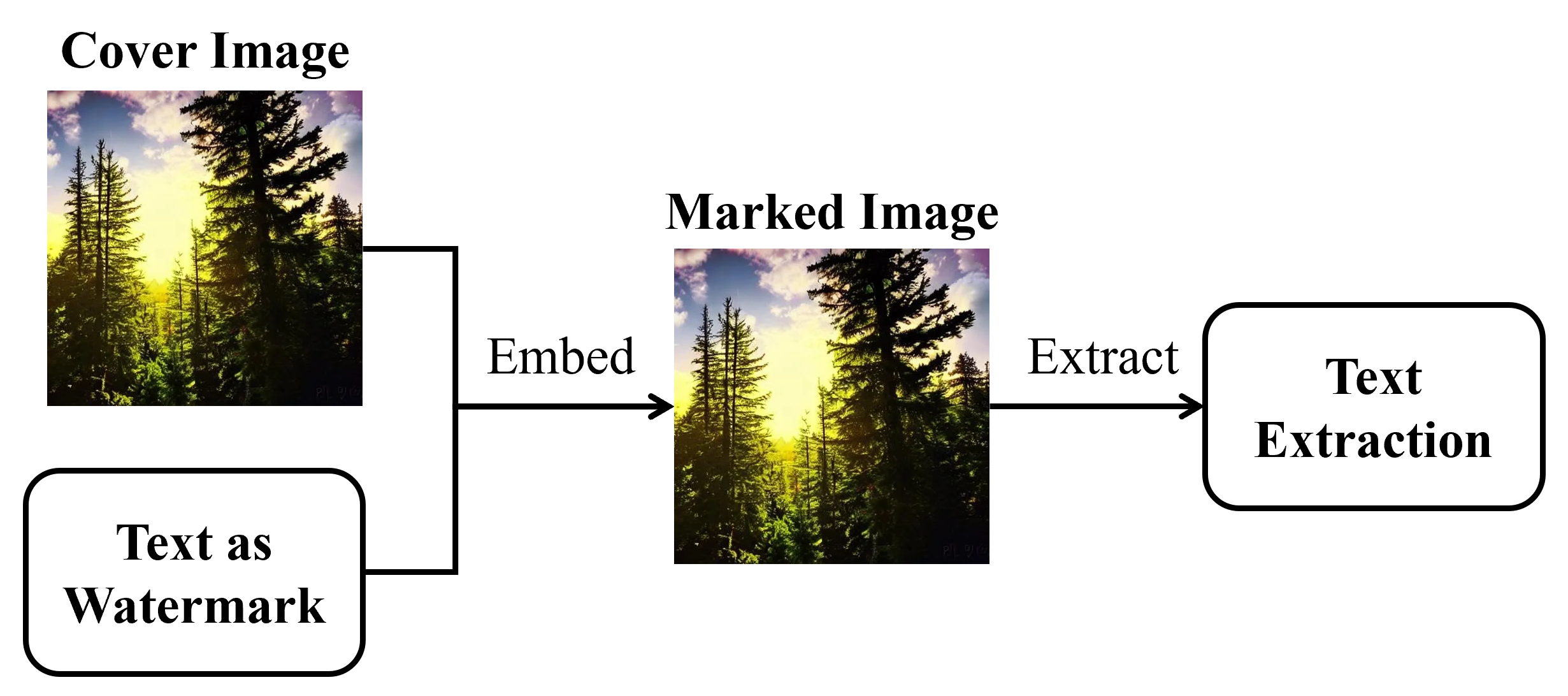
Deep Learning-based Text-in-Image Watermarking
Bishwa Karki, Chun-Hua Tsai, Pei-Chi Huang, Xin Zhong
0
0
In this work, we introduce a novel deep learning-based approach to text-in-image watermarking, a method that embeds and extracts textual information within images to enhance data security and integrity. Leveraging the capabilities of deep learning, specifically through the use of Transformer-based architectures for text processing and Vision Transformers for image feature extraction, our method sets new benchmarks in the domain. The proposed method represents the first application of deep learning in text-in-image watermarking that improves adaptivity, allowing the model to intelligently adjust to specific image characteristics and emerging threats. Through testing and evaluation, our method has demonstrated superior robustness compared to traditional watermarking techniques, achieving enhanced imperceptibility that ensures the watermark remains undetectable across various image contents.
4/23/2024