Watermark-based Detection and Attribution of AI-Generated Content
2404.04254
0
0

Abstract
Several companies--such as Google, Microsoft, and OpenAI--have deployed techniques to watermark AI-generated content to enable proactive detection. However, existing literature mainly focuses on user-agnostic detection. Attribution aims to further trace back the user of a generative-AI service who generated a given content detected as AI-generated. Despite its growing importance, attribution is largely unexplored. In this work, we aim to bridge this gap by providing the first systematic study on watermark-based, user-aware detection and attribution of AI-generated content. Specifically, we theoretically study the detection and attribution performance via rigorous probabilistic analysis. Moreover, we develop an efficient algorithm to select watermarks for the users to enhance attribution performance. Both our theoretical and empirical results show that watermark-based detection and attribution inherit the accuracy and (non-)robustness properties of the watermarking method.
Create account to get full access
Overview
- This paper presents a watermark-based approach for detecting and attributing AI-generated content.
- The proposed method embeds a unique watermark into the generated text, allowing for reliable detection and tracing back to the original model.
- The authors evaluate their technique on various language models and demonstrate its effectiveness in distinguishing AI-generated from human-written content.
Plain English Explanation
The paper introduces a new way to identify text that was generated by AI systems, rather than written by humans. The key idea is to embed a hidden "watermark" into the AI-generated text. This watermark acts like a digital fingerprint that can be detected later, allowing the text to be traced back to the original AI model that produced it.
The authors test their watermarking approach on several different language models, and show that it can reliably distinguish AI-generated text from human-written text. This could be useful for identifying AI-generated content on the internet, preventing the spread of misinformation, and humanizing machine-generated content.
Technical Explanation
The paper proposes a watermarking technique to detect and attribute AI-generated text. The authors embed a unique watermark into the language model's output during training, without degrading the quality of the generated text.
To evaluate their approach, the authors fine-tune several large language models, including GPT-2 and GPT-J, and test the watermarked text on a range of tasks. They demonstrate that the watermark can be reliably detected, even when the text is edited or modified. Additionally, they show that the watermark can be used to trace the text back to the original model, enabling attribution of AI-generated content.
Critical Analysis
The proposed watermarking approach appears to be a promising technique for addressing the challenges of detecting AI-generated content and tracing it back to the original source. However, the authors acknowledge that their method may have limited effectiveness against adversarial attacks, where the watermark could potentially be removed or obscured.
Additionally, the paper does not explore the potential ethical implications of such watermarking techniques, such as privacy concerns or the potential for misuse. Further research is needed to understand the broader societal impacts of this technology.
Conclusion
This paper presents a novel watermarking approach for detecting and attributing AI-generated text. The authors demonstrate the effectiveness of their technique on various language models, highlighting its potential to combat the spread of misinformation and promote transparency in the use of AI-generated content. While the method shows promise, more research is needed to address its limitations and explore the broader ethical considerations surrounding the use of such techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Protect-Your-IP: Scalable Source-Tracing and Attribution against Personalized Generation
Runyi Li, Xuanyu Zhang, Zhipei Xu, Yongbing Zhang, Jian Zhang
0
0
With the advent of personalized generation models, users can more readily create images resembling existing content, heightening the risk of violating portrait rights and intellectual property (IP). Traditional post-hoc detection and source-tracing methods for AI-generated content (AIGC) employ proactive watermark approaches; however, these are less effective against personalized generation models. Moreover, attribution techniques for AIGC rely on passive detection but often struggle to differentiate AIGC from authentic images, presenting a substantial challenge. Integrating these two processes into a cohesive framework not only meets the practical demands for protection and forensics but also improves the effectiveness of attribution tasks. Inspired by this insight, we propose a unified approach for image copyright source-tracing and attribution, introducing an innovative watermarking-attribution method that blends proactive and passive strategies. We embed copyright watermarks into protected images and train a watermark decoder to retrieve copyright information from the outputs of personalized models, using this watermark as an initial step for confirming if an image is AIGC-generated. To pinpoint specific generation techniques, we utilize powerful visual backbone networks for classification. Additionally, we implement an incremental learning strategy to adeptly attribute new personalized models without losing prior knowledge, thereby enhancing the model's adaptability to novel generation methods. We have conducted experiments using various celebrity portrait series sourced online, and the results affirm the efficacy of our method in source-tracing and attribution tasks, as well as its robustness against knowledge forgetting.
5/28/2024
📈
Explanation as a Watermark: Towards Harmless and Multi-bit Model Ownership Verification via Watermarking Feature Attribution
Shuo Shao, Yiming Li, Hongwei Yao, Yiling He, Zhan Qin, Kui Ren
0
0
Ownership verification is currently the most critical and widely adopted post-hoc method to safeguard model copyright. In general, model owners exploit it to identify whether a given suspicious third-party model is stolen from them by examining whether it has particular properties `inherited' from their released models. Currently, backdoor-based model watermarks are the primary and cutting-edge methods to implant such properties in the released models. However, backdoor-based methods have two fatal drawbacks, including harmfulness and ambiguity. The former indicates that they introduce maliciously controllable misclassification behaviors ($i.e.$, backdoor) to the watermarked released models. The latter denotes that malicious users can easily pass the verification by finding other misclassified samples, leading to ownership ambiguity. In this paper, we argue that both limitations stem from the `zero-bit' nature of existing watermarking schemes, where they exploit the status ($i.e.$, misclassified) of predictions for verification. Motivated by this understanding, we design a new watermarking paradigm, $i.e.$, Explanation as a Watermark (EaaW), that implants verification behaviors into the explanation of feature attribution instead of model predictions. Specifically, EaaW embeds a `multi-bit' watermark into the feature attribution explanation of specific trigger samples without changing the original prediction. We correspondingly design the watermark embedding and extraction algorithms inspired by explainable artificial intelligence. In particular, our approach can be used for different tasks ($e.g.$, image classification and text generation). Extensive experiments verify the effectiveness and harmlessness of our EaaW and its resistance to potential attacks.
5/9/2024
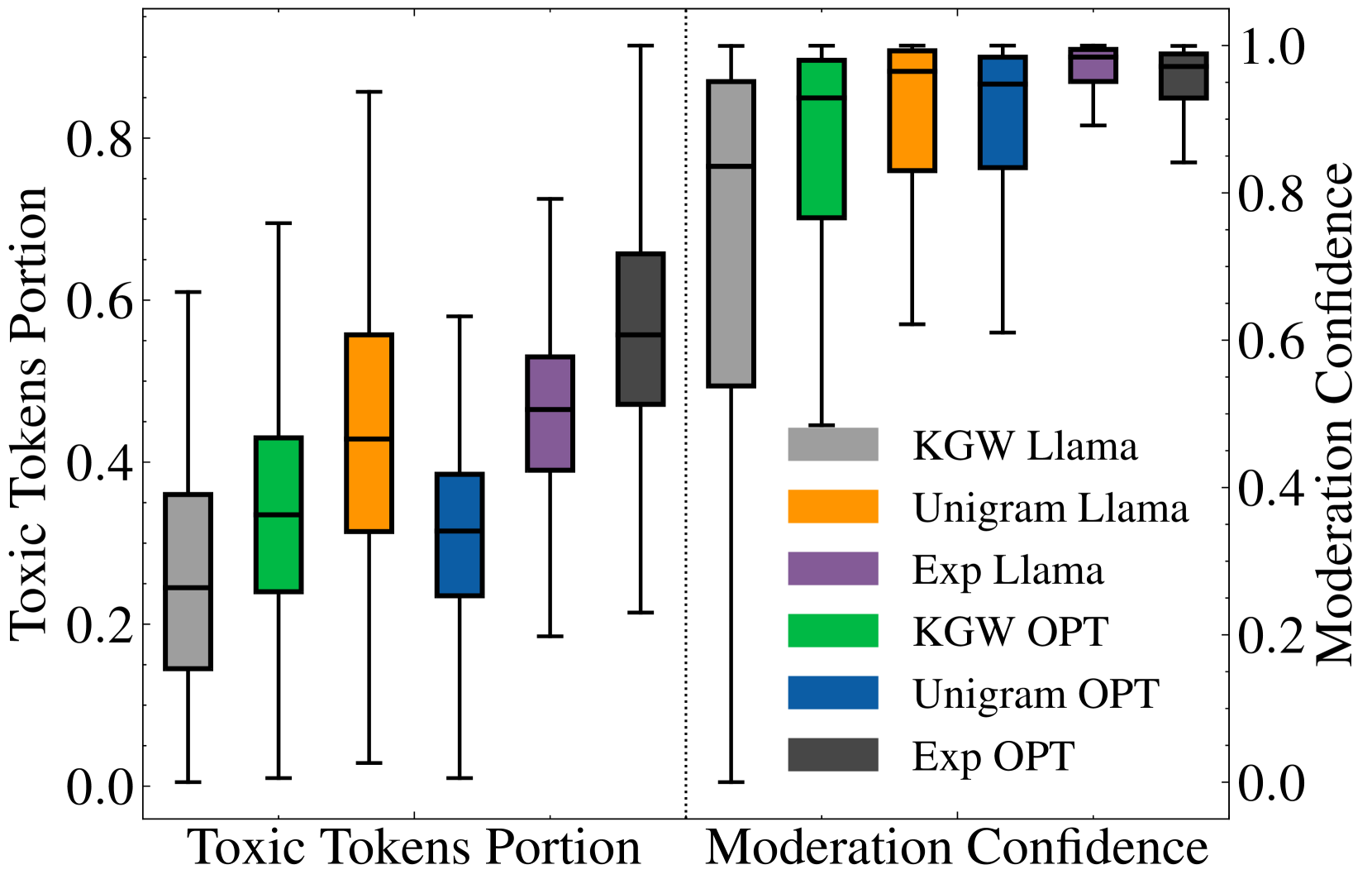
No Free Lunch in LLM Watermarking: Trade-offs in Watermarking Design Choices
Qi Pang, Shengyuan Hu, Wenting Zheng, Virginia Smith
0
0
Advances in generative models have made it possible for AI-generated text, code, and images to mirror human-generated content in many applications. Watermarking, a technique that aims to embed information in the output of a model to verify its source, is useful for mitigating the misuse of such AI-generated content. However, we show that common design choices in LLM watermarking schemes make the resulting systems surprisingly susceptible to attack -- leading to fundamental trade-offs in robustness, utility, and usability. To navigate these trade-offs, we rigorously study a set of simple yet effective attacks on common watermarking systems, and propose guidelines and defenses for LLM watermarking in practice.
5/28/2024
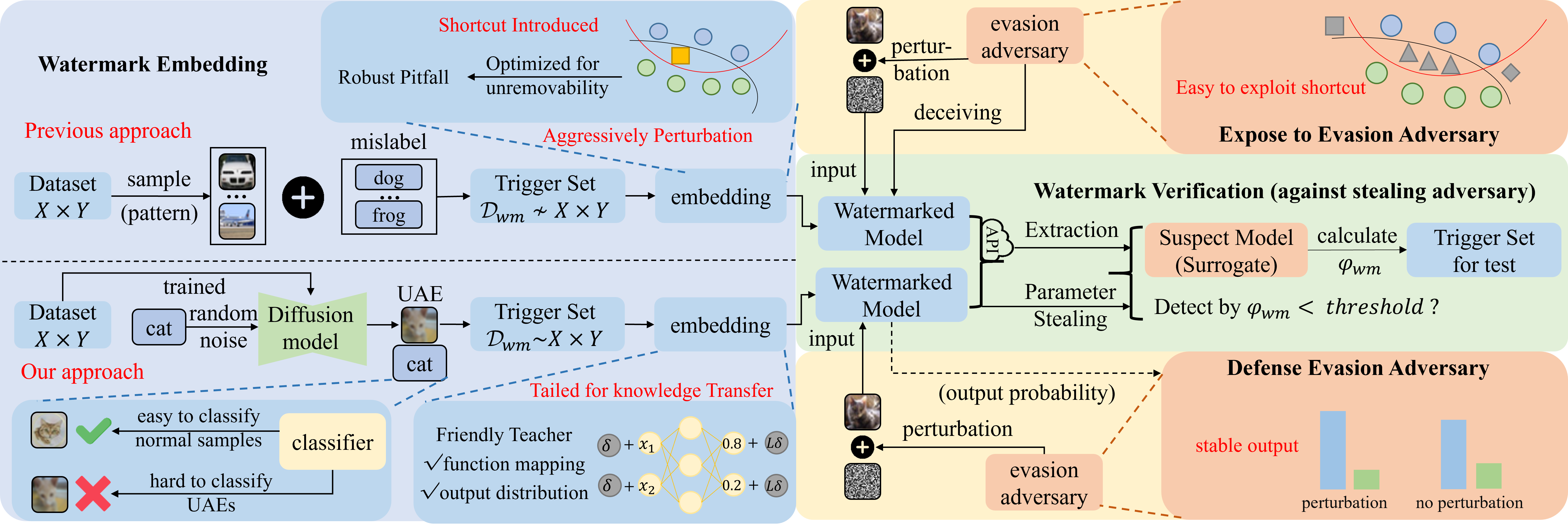
Reliable Model Watermarking: Defending Against Theft without Compromising on Evasion
Hongyu Zhu, Sichu Liang, Wentao Hu, Fangqi Li, Ju Jia, Shilin Wang
0
0
With the rise of Machine Learning as a Service (MLaaS) platforms,safeguarding the intellectual property of deep learning models is becoming paramount. Among various protective measures, trigger set watermarking has emerged as a flexible and effective strategy for preventing unauthorized model distribution. However, this paper identifies an inherent flaw in the current paradigm of trigger set watermarking: evasion adversaries can readily exploit the shortcuts created by models memorizing watermark samples that deviate from the main task distribution, significantly impairing their generalization in adversarial settings. To counteract this, we leverage diffusion models to synthesize unrestricted adversarial examples as trigger sets. By learning the model to accurately recognize them, unique watermark behaviors are promoted through knowledge injection rather than error memorization, thus avoiding exploitable shortcuts. Furthermore, we uncover that the resistance of current trigger set watermarking against removal attacks primarily relies on significantly damaging the decision boundaries during embedding, intertwining unremovability with adverse impacts. By optimizing the knowledge transfer properties of protected models, our approach conveys watermark behaviors to extraction surrogates without aggressively decision boundary perturbation. Experimental results on CIFAR-10/100 and Imagenette datasets demonstrate the effectiveness of our method, showing not only improved robustness against evasion adversaries but also superior resistance to watermark removal attacks compared to state-of-the-art solutions.
4/23/2024