VAR-CLIP: Text-to-Image Generator with Visual Auto-Regressive Modeling

0

Sign in to get full access
Overview
- VAR-CLIP is a text-to-image generation model that uses visual auto-regressive modeling.
- It leverages the strong image understanding capabilities of CLIP while adding a visual auto-regressive module to generate high-quality images from text prompts.
- The model achieves state-of-the-art results on several text-to-image benchmarks.
Plain English Explanation
VAR-CLIP: Text-to-Image Generator with Visual Auto-Regressive Modeling is a new approach to generating images from text. The key idea is to combine the powerful image understanding of a model called CLIP with a "visual auto-regressive" module.
CLIP is a large language model that has been trained to understand the relationship between images and text. It can take a text description and match it to the most relevant image in a large database. VAR-CLIP builds on CLIP by adding an additional component that can actually generate new images from scratch based on the text prompt.
This "visual auto-regressive" module works by predicting the pixels of the image one small piece at a time, in an iterative, automatic way. It learns to build up the image gradually, making decisions about what each region of the image should look like based on the text description.
By combining the strengths of CLIP's image understanding with this visual auto-regressive generation, the VAR-CLIP model is able to produce high-quality images that match the given text prompts. It achieves state-of-the-art performance on several benchmarks for text-to-image generation.
Technical Explanation
VAR-CLIP: Text-to-Image Generator with Visual Auto-Regressive Modeling presents a novel approach for generating images from text prompts. The key innovation is the integration of a visual auto-regressive module with CLIP, a powerful vision-language model.
CLIP is used to encode the text prompt and provide high-level guidance for the image generation process. The visual auto-regressive module then learns to iteratively predict the pixel values of the output image, conditioned on the CLIP text embedding and the partially generated image.
This visual auto-regressive model is inspired by the success of auto-regressive text generation models, but applied to the visual domain. It breaks down the image generation task into a sequence of local, interdependent predictions, allowing the model to gradually build up the final image.
The authors conduct extensive experiments on several text-to-image benchmarks, demonstrating state-of-the-art performance of VAR-CLIP compared to previous approaches. They also provide detailed ablation studies to analyze the contributions of the different model components.
Critical Analysis
The VAR-CLIP paper presents a promising approach to text-to-image generation, but it is important to consider some potential limitations and areas for further research.
One key concern is the computational complexity of the visual auto-regressive module, which may limit the scalability of the approach. The iterative, pixel-level prediction process could be slow and resource-intensive, especially for high-resolution images.
Additionally, the paper does not fully address the issue of "hallucination" - the tendency of text-to-image models to generate content that is not fully grounded in the input text. Further work may be needed to improve the faithfulness and consistency of the generated images.
Finally, the authors acknowledge that VAR-CLIP, like other text-to-image models, can sometimes exhibit biases and limitations in its understanding of the world. Exploring ways to make these models more inclusive and representative remains an important direction for future research.
Overall, the VAR-CLIP paper represents a significant advancement in text-to-image generation, but continued innovation and careful evaluation will be necessary to fully realize the potential of this technology.
Conclusion
VAR-CLIP: Text-to-Image Generator with Visual Auto-Regressive Modeling presents a novel approach to generating images from text prompts. By combining the strengths of the CLIP vision-language model with a visual auto-regressive module, the researchers have developed a system that achieves state-of-the-art performance on several text-to-image benchmarks.
The key innovation is the iterative, pixel-level prediction process of the visual auto-regressive module, which allows the model to gradually build up the output image. This complements the high-level understanding provided by CLIP, leading to the generation of more coherent and faithful images.
While the VAR-CLIP model represents an important step forward, there remain opportunities for further research to address computational complexity, hallucination, and bias. Nonetheless, this work demonstrates the potential of combining language and vision models in novel ways to push the boundaries of image generation capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VAR-CLIP: Text-to-Image Generator with Visual Auto-Regressive Modeling
Qian Zhang, Xiangzi Dai, Ninghua Yang, Xiang An, Ziyong Feng, Xingyu Ren
VAR is a new generation paradigm that employs 'next-scale prediction' as opposed to 'next-token prediction'. This innovative transformation enables auto-regressive (AR) transformers to rapidly learn visual distributions and achieve robust generalization. However, the original VAR model is constrained to class-conditioned synthesis, relying solely on textual captions for guidance. In this paper, we introduce VAR-CLIP, a novel text-to-image model that integrates Visual Auto-Regressive techniques with the capabilities of CLIP. The VAR-CLIP framework encodes captions into text embeddings, which are then utilized as textual conditions for image generation. To facilitate training on extensive datasets, such as ImageNet, we have constructed a substantial image-text dataset leveraging BLIP2. Furthermore, we delve into the significance of word positioning within CLIP for the purpose of caption guidance. Extensive experiments confirm VAR-CLIP's proficiency in generating fantasy images with high fidelity, textual congruence, and aesthetic excellence. Our project page are https://github.com/daixiangzi/VAR-CLIP
Read more8/6/2024

0
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, Liwei Wang
We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine next-scale prediction or next-resolution prediction, diverging from the standard raster-scan next-token prediction. This simple, intuitive methodology allows autoregressive (AR) transformers to learn visual distributions fast and generalize well: VAR, for the first time, makes GPT-like AR models surpass diffusion transformers in image generation. On ImageNet 256x256 benchmark, VAR significantly improve AR baseline by improving Frechet inception distance (FID) from 18.65 to 1.73, inception score (IS) from 80.4 to 350.2, with around 20x faster inference speed. It is also empirically verified that VAR outperforms the Diffusion Transformer (DiT) in multiple dimensions including image quality, inference speed, data efficiency, and scalability. Scaling up VAR models exhibits clear power-law scaling laws similar to those observed in LLMs, with linear correlation coefficients near -0.998 as solid evidence. VAR further showcases zero-shot generalization ability in downstream tasks including image in-painting, out-painting, and editing. These results suggest VAR has initially emulated the two important properties of LLMs: Scaling Laws and zero-shot task generalization. We have released all models and codes to promote the exploration of AR/VAR models for visual generation and unified learning.
Read more6/11/2024

0
ControlVAR: Exploring Controllable Visual Autoregressive Modeling
Xiang Li, Kai Qiu, Hao Chen, Jason Kuen, Zhe Lin, Rita Singh, Bhiksha Raj
Conditional visual generation has witnessed remarkable progress with the advent of diffusion models (DMs), especially in tasks like control-to-image generation. However, challenges such as expensive computational cost, high inference latency, and difficulties of integration with large language models (LLMs) have necessitated exploring alternatives to DMs. This paper introduces ControlVAR, a novel framework that explores pixel-level controls in visual autoregressive (VAR) modeling for flexible and efficient conditional generation. In contrast to traditional conditional models that learn the conditional distribution, ControlVAR jointly models the distribution of image and pixel-level conditions during training and imposes conditional controls during testing. To enhance the joint modeling, we adopt the next-scale AR prediction paradigm and unify control and image representations. A teacher-forcing guidance strategy is proposed to further facilitate controllable generation with joint modeling. Extensive experiments demonstrate the superior efficacy and flexibility of ControlVAR across various conditional generation tasks against popular conditional DMs, eg, ControlNet and T2I-Adaptor.
Read more6/17/2024
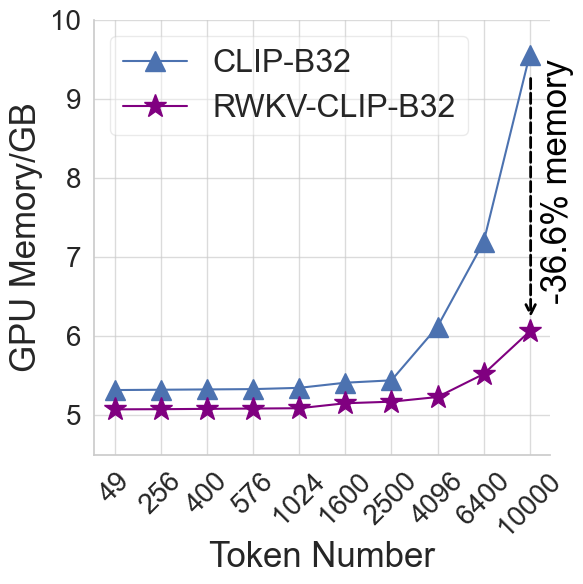
0
RWKV-CLIP: A Robust Vision-Language Representation Learner
Tiancheng Gu, Kaicheng Yang, Xiang An, Ziyong Feng, Dongnan Liu, Weidong Cai, Jiankang Deng
Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper further explores CLIP from the perspectives of data and model architecture. To address the prevalence of noisy data and enhance the quality of large-scale image-text data crawled from the internet, we introduce a diverse description generation framework that can leverage Large Language Models (LLMs) to synthesize and refine content from web-based texts, synthetic captions, and detection tags. Furthermore, we propose RWKV-CLIP, the first RWKV-driven vision-language representation learning model that combines the effective parallel training of transformers with the efficient inference of RNNs. Comprehensive experiments across various model scales and pre-training datasets demonstrate that RWKV-CLIP is a robust and efficient vision-language representation learner, it achieves state-of-the-art performance in several downstream tasks, including linear probe, zero-shot classification, and zero-shot image-text retrieval. To facilitate future research, the code and pre-trained models are released at https://github.com/deepglint/RWKV-CLIP
Read more6/12/2024