Variational Learning is Effective for Large Deep Networks
2402.17641
0
0
Abstract
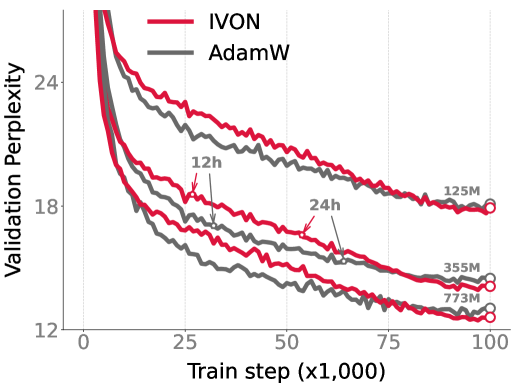
We give extensive empirical evidence against the common belief that variational learning is ineffective for large neural networks. We show that an optimizer called Improved Variational Online Newton (IVON) consistently matches or outperforms Adam for training large networks such as GPT-2 and ResNets from scratch. IVON's computational costs are nearly identical to Adam but its predictive uncertainty is better. We show several new use cases of IVON where we improve finetuning and model merging in Large Language Models, accurately predict generalization error, and faithfully estimate sensitivity to data. We find overwhelming evidence that variational learning is effective.
Create account to get full access
Overview
- This paper explores the effectiveness of variational learning for training large deep neural networks.
- The authors identify challenges in applying variational learning to these networks and propose an improved variational online Newton method to address them.
- The method is evaluated on various deep learning tasks, demonstrating its advantages over standard optimization techniques.
Plain English Explanation
Variational learning is a way of training machine learning models, like deep neural networks, that can be more effective than traditional optimization methods. However, applying variational learning to large, deep neural networks can be challenging.
This paper looks at those challenges and proposes an improved variational online Newton method that helps overcome them. The key idea is to use a specific type of optimization that can efficiently handle the complexity of large, deep neural networks.
The authors test their improved method on different deep learning tasks and show that it outperforms standard optimization techniques. This suggests that variational learning can be a powerful tool for training large, complex neural networks, if the right optimization approach is used.
The paper provides insights into the tradeoffs and best practices for applying variational learning to state-of-the-art deep learning models. By addressing the challenges, it demonstrates how variational methods can be effectively used to train high-performance deep neural networks.
Technical Explanation
The paper examines the challenges of using variational learning for large deep neural networks. The authors identify issues like the difficulty of optimizing the variational objective and the high computational cost.
To address these challenges, they propose an improved variational online Newton method. This approach uses a specific type of optimization, called online Newton, that can efficiently handle the complexity of large, deep models.
The authors evaluate their improved method on a range of deep learning tasks, including image classification, language modeling, and reinforcement learning. They compare it to standard optimization techniques like stochastic gradient descent and natural gradient descent.
The results show that the proposed variational online Newton method outperforms these standard approaches, especially on the most challenging deep neural network architectures. This suggests that variational learning can be a powerful tool for training large, complex models when combined with the right optimization strategy.
Critical Analysis
The paper provides a thorough analysis of the challenges in applying variational learning to large deep neural networks and proposes a novel solution to address them. The authors' identification of the key issues, such as the difficulty of optimizing the variational objective and the high computational cost, is well-supported and relevant to the field.
While the proposed variational online Newton method appears to be effective, the paper could have provided more details on the specific advantages and limitations of this approach. For example, it would be helpful to understand how the method compares to other recent advances in variational optimization, such as reparameterization tricks or amortized variational inference.
Additionally, the paper could have delved deeper into the theoretical properties of the variational online Newton method, such as its convergence guarantees or its sensitivity to hyperparameter choices. Providing more insight into the underlying mechanisms of the method would strengthen the overall contribution.
Overall, the paper presents a valuable contribution to the field of Bayesian deep learning and variational optimization. The authors have identified an important problem and proposed a promising solution that demonstrates the potential of variational learning for large-scale deep neural networks.
Conclusion
This paper showcases the effectiveness of variational learning for training large, deep neural networks. By addressing the key challenges in applying variational methods to these complex models, the authors have developed an improved variational online Newton optimization technique that outperforms standard approaches.
The results suggest that variational learning can be a powerful tool for building high-performance deep learning models, provided the right optimization strategy is used. This work contributes to the growing body of research on Bayesian deep learning and variational methods, which hold promise for making deep neural networks more robust, interpretable, and sample-efficient.
As deep learning continues to advance, techniques like the one proposed in this paper will be increasingly important for pushing the boundaries of what is possible with large-scale neural networks. The insights and methods presented here can help pave the way for more effective, reliable, and interpretable deep learning systems across a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Variational Optimization for Quantum Problems using Deep Generative Networks
Lingxia Zhang, Xiaodie Lin, Peidong Wang, Kaiyan Yang, Xiao Zeng, Zhaohui Wei, Zizhu Wang
0
0
Optimization is one of the keystones of modern science and engineering. Its applications in quantum technology and machine learning helped nurture variational quantum algorithms and generative AI respectively. We propose a general approach to design variational optimization algorithms based on generative models: the Variational Generative Optimization Network (VGON). To demonstrate its broad applicability, we apply VGON to three quantum tasks: finding the best state in an entanglement-detection protocol, finding the ground state of a 1D quantum spin model with variational quantum circuits, and generating degenerate ground states of many-body quantum Hamiltonians. For the first task, VGON greatly reduces the optimization time compared to stochastic gradient descent while generating nearly optimal quantum states. For the second task, VGON alleviates the barren plateau problem in variational quantum circuits. For the final task, VGON can identify the degenerate ground state spaces after a single stage of training and generate a variety of states therein.
4/30/2024

Variational Stochastic Gradient Descent for Deep Neural Networks
Haotian Chen, Anna Kuzina, Babak Esmaeili, Jakub M Tomczak
0
0
Optimizing deep neural networks is one of the main tasks in successful deep learning. Current state-of-the-art optimizers are adaptive gradient-based optimization methods such as Adam. Recently, there has been an increasing interest in formulating gradient-based optimizers in a probabilistic framework for better estimation of gradients and modeling uncertainties. Here, we propose to combine both approaches, resulting in the Variational Stochastic Gradient Descent (VSGD) optimizer. We model gradient updates as a probabilistic model and utilize stochastic variational inference (SVI) to derive an efficient and effective update rule. Further, we show how our VSGD method relates to other adaptive gradient-based optimizers like Adam. Lastly, we carry out experiments on two image classification datasets and four deep neural network architectures, where we show that VSGD outperforms Adam and SGD.
4/11/2024
🧠
Post-variational quantum neural networks
Po-Wei Huang, Patrick Rebentrost
0
0
Hybrid quantum-classical computing in the noisy intermediate-scale quantum (NISQ) era with variational algorithms can exhibit barren plateau issues, causing difficult convergence of gradient-based optimization techniques. In this paper, we discuss post-variational strategies, which shift tunable parameters from the quantum computer to the classical computer, opting for ensemble strategies when optimizing quantum models. We discuss various strategies and design principles for constructing individual quantum circuits, where the resulting ensembles can be optimized with convex programming. Further, we discuss architectural designs of post-variational quantum neural networks and analyze the propagation of estimation errors throughout such neural networks. Finally, we show that empirically, post-variational quantum neural networks using our architectural designs can potentially provide better results than variational algorithms and performance comparable to that of two-layer neural networks.
4/8/2024
🛠️
A Study on Optimization Techniques for Variational Quantum Circuits in Reinforcement Learning
Michael Kolle, Timo Witter, Tobias Rohe, Gerhard Stenzel, Philipp Altmann, Thomas Gabor
0
0
Quantum Computing aims to streamline machine learning, making it more effective with fewer trainable parameters. This reduction of parameters can speed up the learning process and reduce the use of computational resources. However, in the current phase of quantum computing development, known as the noisy intermediate-scale quantum era (NISQ), learning is difficult due to a limited number of qubits and widespread quantum noise. To overcome these challenges, researchers are focusing on variational quantum circuits (VQCs). VQCs are hybrid algorithms that merge a quantum circuit, which can be adjusted through parameters, with traditional classical optimization techniques. These circuits require only few qubits for effective learning. Recent studies have presented new ways of applying VQCs to reinforcement learning, showing promising results that warrant further exploration. This study investigates the effects of various techniques -- data re-uploading, input scaling, output scaling -- and introduces exponential learning rate decay in the quantum proximal policy optimization algorithm's actor-VQC. We assess these methods in the popular Frozen Lake and Cart Pole environments. Our focus is on their ability to reduce the number of parameters in the VQC without losing effectiveness. Our findings indicate that data re-uploading and an exponential learning rate decay significantly enhance hyperparameter stability and overall performance. While input scaling does not improve parameter efficiency, output scaling effectively manages greediness, leading to increased learning speed and robustness.
5/22/2024