Variational Stochastic Gradient Descent for Deep Neural Networks
2404.06549
0
0

Abstract
Optimizing deep neural networks is one of the main tasks in successful deep learning. Current state-of-the-art optimizers are adaptive gradient-based optimization methods such as Adam. Recently, there has been an increasing interest in formulating gradient-based optimizers in a probabilistic framework for better estimation of gradients and modeling uncertainties. Here, we propose to combine both approaches, resulting in the Variational Stochastic Gradient Descent (VSGD) optimizer. We model gradient updates as a probabilistic model and utilize stochastic variational inference (SVI) to derive an efficient and effective update rule. Further, we show how our VSGD method relates to other adaptive gradient-based optimizers like Adam. Lastly, we carry out experiments on two image classification datasets and four deep neural network architectures, where we show that VSGD outperforms Adam and SGD.
Create account to get full access
Overview
- This paper presents a new algorithm called Variational Stochastic Gradient Descent (VSGD) for training deep neural networks.
- VSGD combines techniques from both stochastic gradient descent and variational inference to improve the optimization and generalization of deep neural networks.
- The authors demonstrate the effectiveness of VSGD on various benchmark tasks, showing improvements over standard stochastic gradient descent.
Plain English Explanation
Deep neural networks have become incredibly powerful for a wide range of machine learning tasks, from image recognition to natural language processing. However, training these complex models can be challenging, as the optimization process can get stuck in poor local minima or fail to generalize well to new data.
The researchers in this paper propose a new algorithm called Variational Stochastic Gradient Descent (VSGD) that aims to address these issues. VSGD combines two key ideas: stochastic gradient descent and variational inference.
Stochastic gradient descent is the workhorse optimization algorithm used to train deep neural networks. It works by iteratively updating the model parameters in the direction of the gradient, which points towards a local minimum of the loss function. Variational inference, on the other hand, is a technique that allows the model to learn a probability distribution over the model parameters, rather than a single point estimate.
By combining these two ideas, VSGD can explore the parameter space more effectively, avoiding poor local minima and learning a more robust model that generalizes better to new data. The authors demonstrate the effectiveness of VSGD on a variety of benchmark machine learning tasks, showing improvements over standard stochastic gradient descent.
Technical Explanation
The key idea behind Variational Stochastic Gradient Descent (VSGD) is to learn a probability distribution over the model parameters, rather than a single point estimate, as is done in standard stochastic gradient descent.
Specifically, VSGD introduces a set of auxiliary variables that represent the model parameters. These auxiliary variables are treated as random variables, and a variational distribution is learned over them using techniques from variational inference. During training, the model alternates between updating the variational distribution and taking gradient steps to optimize the model parameters.
This approach has several advantages:
- Exploration of the parameter space: By learning a distribution over the parameters, VSGD can more effectively explore the parameter space and avoid poor local minima.
- Improved generalization: The variational distribution learned by VSGD can capture the uncertainty in the model parameters, leading to better generalization performance on new data.
- Adaptive step sizes: VSGD can adaptively adjust the step sizes during optimization, similar to methods like Adaptive Moment Estimation (Adam), which can further improve convergence.
The authors evaluate VSGD on a range of benchmark tasks, including image classification, language modeling, and reinforcement learning. The results show that VSGD outperforms standard stochastic gradient descent, as well as other recent gradient-based optimization methods.
Critical Analysis
The Variational Stochastic Gradient Descent (VSGD) algorithm presented in this paper is a promising approach for training deep neural networks, as it combines the strengths of stochastic gradient descent and variational inference.
One potential limitation of the method is the additional computational overhead required to maintain and update the variational distribution over the model parameters. This could make VSGD slower than standard stochastic gradient descent, especially for very large models. The authors mention that they have explored ways to mitigate this issue, such as using more efficient variational inference techniques, but further research may be needed to fully address this trade-off.
Additionally, the paper does not provide a deep theoretical analysis of the algorithm's convergence properties or the underlying reasons for its improved performance. While the empirical results are compelling, a more rigorous theoretical understanding of VSGD could help guide future developments and extensions of the method.
Finally, the authors note that VSGD is a general-purpose optimization algorithm and could potentially be applied to a wide range of machine learning problems beyond just deep neural networks. Exploring the use of VSGD in other domains, such as reinforcement learning or meta-learning, could be an interesting direction for future research.
Conclusion
The Variational Stochastic Gradient Descent (VSGD) algorithm presented in this paper offers a promising new approach for training deep neural networks. By combining techniques from stochastic gradient descent and variational inference, VSGD can more effectively explore the parameter space and learn models that generalize better to new data.
The empirical results demonstrate the effectiveness of VSGD on a variety of benchmark tasks, and the authors suggest that the method could have broader applications beyond just deep learning. While there are some potential limitations to consider, such as the additional computational overhead, the VSGD algorithm represents an exciting development in the field of machine learning optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Learning rate adaptive stochastic gradient descent optimization methods: numerical simulations for deep learning methods for partial differential equations and convergence analyses
Steffen Dereich, Arnulf Jentzen, Adrian Riekert
0
0
It is known that the standard stochastic gradient descent (SGD) optimization method, as well as accelerated and adaptive SGD optimization methods such as the Adam optimizer fail to converge if the learning rates do not converge to zero (as, for example, in the situation of constant learning rates). Numerical simulations often use human-tuned deterministic learning rate schedules or small constant learning rates. The default learning rate schedules for SGD optimization methods in machine learning implementation frameworks such as TensorFlow and Pytorch are constant learning rates. In this work we propose and study a learning-rate-adaptive approach for SGD optimization methods in which the learning rate is adjusted based on empirical estimates for the values of the objective function of the considered optimization problem (the function that one intends to minimize). In particular, we propose a learning-rate-adaptive variant of the Adam optimizer and implement it in case of several neural network learning problems, particularly, in the context of deep learning approximation methods for partial differential equations such as deep Kolmogorov methods, physics-informed neural networks, and deep Ritz methods. In each of the presented learning problems the proposed learning-rate-adaptive variant of the Adam optimizer faster reduces the value of the objective function than the Adam optimizer with the default learning rate. For a simple class of quadratic minimization problems we also rigorously prove that a learning-rate-adaptive variant of the SGD optimization method converges to the minimizer of the considered minimization problem. Our convergence proof is based on an analysis of the laws of invariant measures of the SGD method as well as on a more general convergence analysis for SGD with random but predictable learning rates which we develop in this work.
6/21/2024
🛠️
Variational Optimization for Quantum Problems using Deep Generative Networks
Lingxia Zhang, Xiaodie Lin, Peidong Wang, Kaiyan Yang, Xiao Zeng, Zhaohui Wei, Zizhu Wang
0
0
Optimization is one of the keystones of modern science and engineering. Its applications in quantum technology and machine learning helped nurture variational quantum algorithms and generative AI respectively. We propose a general approach to design variational optimization algorithms based on generative models: the Variational Generative Optimization Network (VGON). To demonstrate its broad applicability, we apply VGON to three quantum tasks: finding the best state in an entanglement-detection protocol, finding the ground state of a 1D quantum spin model with variational quantum circuits, and generating degenerate ground states of many-body quantum Hamiltonians. For the first task, VGON greatly reduces the optimization time compared to stochastic gradient descent while generating nearly optimal quantum states. For the second task, VGON alleviates the barren plateau problem in variational quantum circuits. For the final task, VGON can identify the degenerate ground state spaces after a single stage of training and generate a variety of states therein.
4/30/2024
Derivatives of Stochastic Gradient Descent
Franck Iutzeler, Edouard Pauwels, Samuel Vaiter
0
0
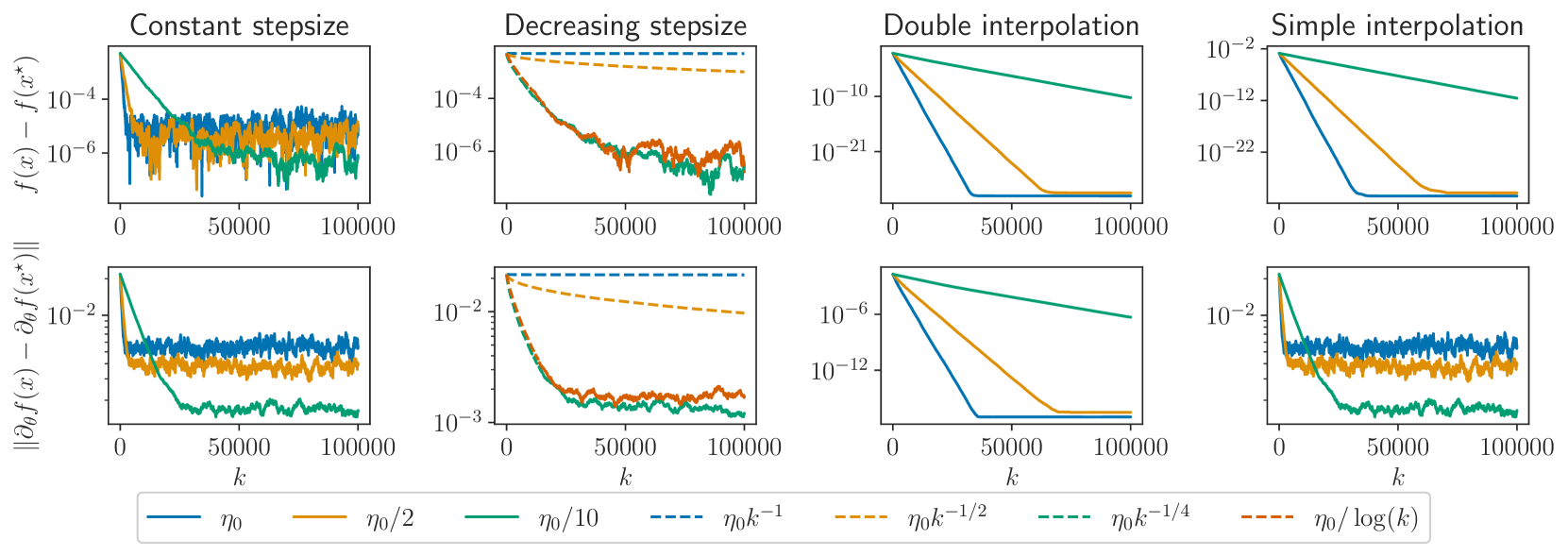
We consider stochastic optimization problems where the objective depends on some parameter, as commonly found in hyperparameter optimization for instance. We investigate the behavior of the derivatives of the iterates of Stochastic Gradient Descent (SGD) with respect to that parameter and show that they are driven by an inexact SGD recursion on a different objective function, perturbed by the convergence of the original SGD. This enables us to establish that the derivatives of SGD converge to the derivative of the solution mapping in terms of mean squared error whenever the objective is strongly convex. Specifically, we demonstrate that with constant step-sizes, these derivatives stabilize within a noise ball centered at the solution derivative, and that with vanishing step-sizes they exhibit $O(log(k)^2 / k)$ convergence rates. Additionally, we prove exponential convergence in the interpolation regime. Our theoretical findings are illustrated by numerical experiments on synthetic tasks.
5/28/2024
Variational Learning is Effective for Large Deep Networks
Yuesong Shen, Nico Daheim, Bai Cong, Peter Nickl, Gian Maria Marconi, Clement Bazan, Rio Yokota, Iryna Gurevych, Daniel Cremers, Mohammad Emtiyaz Khan, Thomas Mollenhoff
0
0
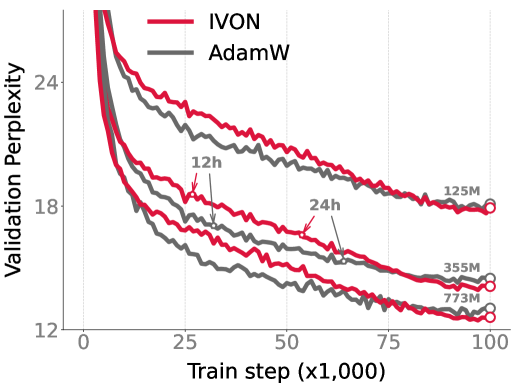
We give extensive empirical evidence against the common belief that variational learning is ineffective for large neural networks. We show that an optimizer called Improved Variational Online Newton (IVON) consistently matches or outperforms Adam for training large networks such as GPT-2 and ResNets from scratch. IVON's computational costs are nearly identical to Adam but its predictive uncertainty is better. We show several new use cases of IVON where we improve finetuning and model merging in Large Language Models, accurately predict generalization error, and faithfully estimate sensitivity to data. We find overwhelming evidence that variational learning is effective.
6/7/2024