Video Super-Resolution Transformer with Masked Inter&Intra-Frame Attention
2401.06312
0
0
Abstract
Recently, Vision Transformer has achieved great success in recovering missing details in low-resolution sequences, i.e., the video super-resolution (VSR) task. Despite its superiority in VSR accuracy, the heavy computational burden as well as the large memory footprint hinder the deployment of Transformer-based VSR models on constrained devices. In this paper, we address the above issue by proposing a novel feature-level masked processing framework: VSR with Masked Intra and inter frame Attention (MIA-VSR). The core of MIA-VSR is leveraging feature-level temporal continuity between adjacent frames to reduce redundant computations and make more rational use of previously enhanced SR features. Concretely, we propose an intra-frame and inter-frame attention block which takes the respective roles of past features and input features into consideration and only exploits previously enhanced features to provide supplementary information. In addition, an adaptive block-wise mask prediction module is developed to skip unimportant computations according to feature similarity between adjacent frames. We conduct detailed ablation studies to validate our contributions and compare the proposed method with recent state-of-the-art VSR approaches. The experimental results demonstrate that MIA-VSR improves the memory and computation efficiency over state-of-the-art methods, without trading off PSNR accuracy. The code is available at https://github.com/LabShuHangGU/MIA-VSR.
Create account to get full access
Introduction
The provided text discusses image super-resolution (SR), which is the process of recovering sharp details in high-resolution (HR) images from low-resolution (LR) observations. It highlights the practical applications of SR, such as surveillance and high-definition displays, and mentions that it has been an active research area for the past two decades.
The text then distinguishes between single image super-resolution and video super-resolution (VSR). Single image SR utilizes only the information within a single frame to estimate the missing details. In contrast, VSR leverages temporal information from multiple frames, often leading to better SR results.
The paper proposes a novel masked video super-resolution (VSR) framework called Masked Inter&Intra frame Attention (MIA) model. The key ideas are:
-
Developing a tailored inter-frame and intra-frame attention block (IIA) to effectively utilize previously enhanced features and spatial/temporal information while reducing computational cost compared to existing approaches.
-
Proposing a feature-level adaptive masked processing mechanism to skip redundant computations based on the continuity between adjacent frames, enabling efficient VSR while maintaining good performance.
The IIA block takes into account the respective roles of past features and input features, using only the current frame's image feature to generate the query token. This aligns intermediate features with spatial coordinates, enabling efficient masked processing.
The adaptive masking strategy predicts unimportant regions at the feature level based on similarity between adjacent frames, skipping computations for those regions in different processing stages. This allows leveraging temporal redundancy to reduce unnecessary calculations.
The proposed MIA-VSR framework can take advantage of temporal continuity to recover missing high-resolution details while reducing redundant computations, leading to superior results with less computation and memory requirements compared to state-of-the-art VSR models.
Related Work
The paper discusses two main categories of deep learning methods for video super-resolution (VSR): temporal sliding-window based methods and recurrent based methods.
Temporal sliding-window based VSR methods process low-resolution (LR) frames in a sliding window manner, aligning adjacent frames with the reference frame to estimate a single high-resolution (HR) output. These methods rely on alignment modules like optical flow estimation, implicit alignment in feature space using dynamic filters, deformable convolutions, or attention. The network architecture for processing the aligned images is also an important research direction.
Recurrent framework based VSR methods utilize recurrent neural networks to exploit temporal information from more frames. Examples include FRVSR, RLSP, RSDN, BasicVSR, BasicVSR++, and PSRT. These methods propagate high-dimensional hidden states or output features to incorporate information from more frames for better detail estimation.
The proposed MIA-VSR method follows the bi-directional second-order hidden feature propagation framework while introducing masked processing and intra&inter-frame attention for better trade-off between accuracy, computation, and memory.
The paper also discusses efficient video processing strategies like pruning, distillation, key-frame based processing, and skip-convolution. However, most of these are designed for high-level vision tasks, and the paper claims to be the first work leveraging temporal continuity to reduce redundant computation for the low-level VSR task.
Methodology

The section describes the overall architecture of the proposed MIA-VSR (Masked Intra&Inter-frame Attention for Efficient Video Super-Resolution) model. The key components are:
-
Shallow feature extraction followed by recurrent feature refinement and reconstruction parts.
-
The recurrent part comprises M feature propagation modules, each with N cascaded intra&inter-frame attention blocks (IIABs).
-
IIABs take the current frame feature and enhanced features from past two frames. They generate query tokens from the current frame and key/value tokens from intra-frame (current) and inter-frame (past) features. This avoids redundant computations compared to processing concatenated features.
-
An adaptive mask prediction module generates block-wise masks to further reduce unimportant computations by skipping regions based on feature differences between adjacent frames.
-
The model is trained with a Charbonnier loss between the super-resolved and ground truth frames, plus an L1 loss to encourage more masked positions.
The architecture aims to efficiently process video frames by reducing redundant computations in the recurrent feature refinement stage through the proposed IIAB and adaptive masking strategies.
Experiments
The section provides details on the experimental settings and results for the proposed MIA-VSR (Masked Intra-Inter Attention for Video Super-Resolution) model.
4.1 Experimental Settings:
- The model is evaluated on the REDS, Vimeo90K, and Vid4 datasets for 4x video super-resolution.
- Two models are trained, one on REDS and one on Vimeo90K.
- The adaptive mask prediction module is fine-tuned for 100K iterations on pre-trained models.
- The model is implemented in PyTorch and trained on RTX 4090 GPUs.
4.2 Ablation Study:
- The proposed Intra-Inter Attention Block (IIAB) is compared to the Multi-Frame Self-Attention Block (MFSAB), showing better performance with less computation.
- Different values of the sparsity loss weight λ are tested for the adaptive mask prediction, with 5e-4 providing the best trade-off between accuracy and computation savings.
- Visualizations of predicted masks are provided.
4.3 Comparison with State-of-the-Art Methods:
- MIA-VSR outperforms other methods like TOFlow, EDVR, MuCAN, VSR-T, VRT, RVRT, BasicVSR, IconVSR, TTVSR, and BasicVSR++ on REDS4, Vimeo90K-T, and Vid4 datasets.
- With less computation than RVRT and PSRT-recurrent, MIA-VSR achieves the best results on REDS and Vid4, and second-best on Vimeo-90K.
- Visual comparisons are provided, showing MIA-VSR's ability to recover sharp textures.
4.4 Complexity and Memory Analysis:
- MIA-VSR has a similar number of parameters to other Transformer-based methods but
Conclusion
The paper introduces a novel Transformer-based recurrent video super-resolution model called MIA-VSR. It proposes a masked processing framework that leverages temporal continuity between adjacent frames to reduce computational requirements for the video super-resolution model. The model includes an Intra-frame and Inter-frame attention block that utilizes previously enhanced features to provide supplementary information, and an adaptive mask prediction module that generates block-wise masks for each processing stage. The researchers evaluated the MIA-VSR model on various benchmark datasets, achieving state-of-the-art video super-resolution results while requiring fewer computational resources compared to existing methods.
Appendix A Dataset and implementation details
The paper discusses the datasets and training/testing details used to evaluate the proposed MIA-VSR video super-resolution method.
Datasets:
- REDS: A widely-used video dataset with 270 clips at 1280x720 resolution. The authors used 4 representative clips for testing and the remaining 266 for training.
- Vimeo-90K: A commonly used dataset with 64,612 training clips and 7,824 testing clips at 448x256 resolution.
- Vid4: A classical dataset for video super-resolution containing 4 video clips with at least 34 frames each at 720x480 resolution.
Training Details:
- For REDS, the model was trained for 600K iterations with an initial learning rate of 2e-4, using the Adam optimizer and a batch size of 24.
- For Vimeo-90K, the pre-trained REDS model was further trained for 300K iterations with an initial learning rate of 1e-4, using the same settings.
Testing Details:
- The REDS4 dataset (4 clips from REDS) was used for testing the REDS model.
- The Vimeo90K-T and Vid4 datasets were used for testing the Vimeo-90K model.
Appendix B Light-weight MIA-VSR models
This section discusses lightweight versions of the proposed MIA-VSR model for video super-resolution (VSR), called MIA-VSR-small and MIA-VSR-tiny. These models have 4 feature propagation modules, each with 6 MIIA blocks and a skip connection. The spatial window size is 8x8 and the head size is 6. The main difference is the number of channels, with 120 for MIA-VSR-small and 96 for MIA-VSR-tiny.
The results show that transformer-based VSR models generally outperform CNN-based methods. The MIA-VSR model achieves better results than the state-of-the-art CNN-based BasicVSR++ with fewer parameters and lower computational cost. Compared to existing transformer-based methods, MIA-VSR achieves better results with much less computation.
The lightweight MIA-VSR-small and MIA-VSR-tiny models strike a good balance between performance and computational cost. With 45% fewer FLOPs, MIA-VSR-tiny improves upon the TTVSR model by 0.28 dB PSNR.
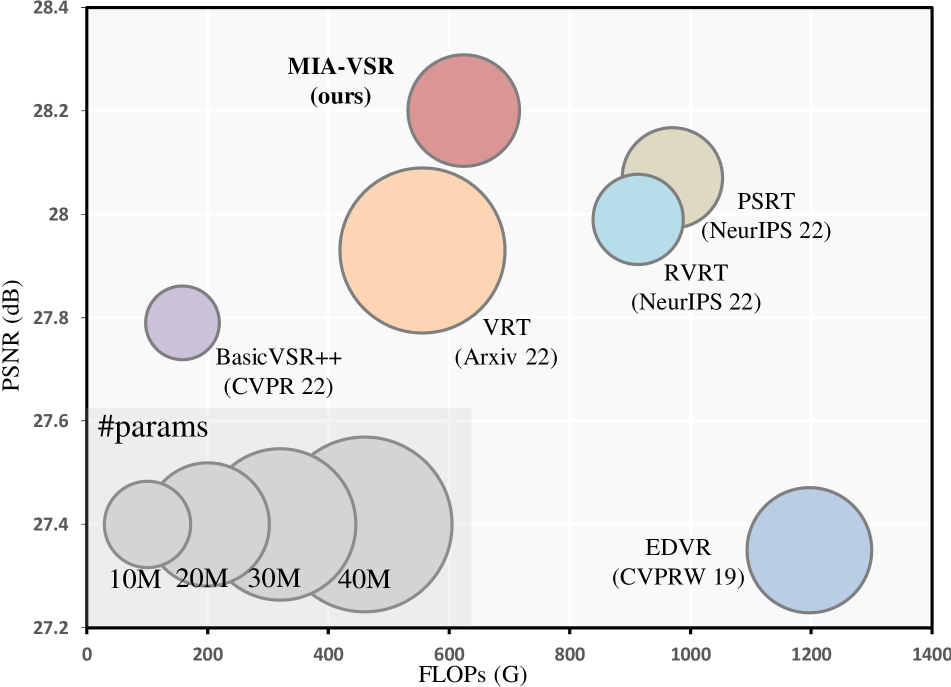
![Figure 6: PSNR(dB) and FLOPs(G) comparison on the REDS4 [27] dataset.
In comparison with the existing video super-resolution methods, our proposed MIA-VSR model, MIA-VSR-small and MIA-VSR-tiny could obtain better trade-offs between VSR results and computational cost.
Our fine-tuned model MIA-VSR†normal-†\dagger† outperforms the current state-of-the-art model by more than 0.1 dB with nearly 40% less number of FLOPs.
Our light-weight model MIA-VSR-tiny outperforms the recent light-weight Transformer-based VSR model TTVSR[24] by 0.28 dB, with 45% less number of FLOPs.
More details can be found in Section B.](https://arxiv.org/html/2401.06312v1/x6.png)
Appendix C Fine-tune MIA-VSR with longer sequences.
The paper discusses further training of the MIA-VSR model, a video super-resolution (VSR) model, with longer sequences to achieve better results. The authors took the MIA-VSR model trained on the REDS dataset for 450K iterations with 16 frames and fine-tuned it for an additional 150K iterations with 40 frames, naming it MIA-VSR††\dagger†. This fine-tuned model demonstrated an improvement of 0.1dB over the original MIA-VSR model trained with 16 frames, without increasing the number of floating-point operations (FLOPs). The authors compared the performance of MIA-VSR††\dagger† with state-of-the-art Transformer-based VSR methods, including VRT, RVRT, and PSRT, as shown in Fig.6 and Table 4.
Appendix D Visual results
The paper presents visual comparisons between existing video super-resolution (VSR) methods and the proposed VSR Transformer with masked inter&intra-frame attention (MIA). The proposed method was trained using 16 frames from the REDS dataset and 14 frames from the Vimeo-90K dataset. The visual results shown in Figures 7 and 8 demonstrate that the proposed method can generate visually pleasing images with sharp edges and fine details, such as horizontal bar patterns of buildings and numbers on license plates. In contrast, existing methods suffer from texture distortion or loss of detail in these types of scenes. In addition to the qualitative visual improvements, the proposed method also achieves quantitative improvements, as mentioned earlier in the paper.


This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Frequency-Assisted Mamba for Remote Sensing Image Super-Resolution
Yi Xiao, Qiangqiang Yuan, Kui Jiang, Yuzeng Chen, Qiang Zhang, Chia-Wen Lin
0
0
Recent progress in remote sensing image (RSI) super-resolution (SR) has exhibited remarkable performance using deep neural networks, e.g., Convolutional Neural Networks and Transformers. However, existing SR methods often suffer from either a limited receptive field or quadratic computational overhead, resulting in sub-optimal global representation and unacceptable computational costs in large-scale RSI. To alleviate these issues, we develop the first attempt to integrate the Vision State Space Model (Mamba) for RSI-SR, which specializes in processing large-scale RSI by capturing long-range dependency with linear complexity. To achieve better SR reconstruction, building upon Mamba, we devise a Frequency-assisted Mamba framework, dubbed FMSR, to explore the spatial and frequent correlations. In particular, our FMSR features a multi-level fusion architecture equipped with the Frequency Selection Module (FSM), Vision State Space Module (VSSM), and Hybrid Gate Module (HGM) to grasp their merits for effective spatial-frequency fusion. Recognizing that global and local dependencies are complementary and both beneficial for SR, we further recalibrate these multi-level features for accurate feature fusion via learnable scaling adaptors. Extensive experiments on AID, DOTA, and DIOR benchmarks demonstrate that our FMSR outperforms state-of-the-art Transformer-based methods HAT-L in terms of PSNR by 0.11 dB on average, while consuming only 28.05% and 19.08% of its memory consumption and complexity, respectively.
5/9/2024

Space-Time Video Super-resolution with Neural Operator
Yuantong Zhang, Hanyou Zheng, Daiqin Yang, Zhenzhong Chen, Haichuan Ma, Wenpeng Ding
0
0
This paper addresses the task of space-time video super-resolution (ST-VSR). Existing methods generally suffer from inaccurate motion estimation and motion compensation (MEMC) problems for large motions. Inspired by recent progress in physics-informed neural networks, we model the challenges of MEMC in ST-VSR as a mapping between two continuous function spaces. Specifically, our approach transforms independent low-resolution representations in the coarse-grained continuous function space into refined representations with enriched spatiotemporal details in the fine-grained continuous function space. To achieve efficient and accurate MEMC, we design a Galerkin-type attention function to perform frame alignment and temporal interpolation. Due to the linear complexity of the Galerkin-type attention mechanism, our model avoids patch partitioning and offers global receptive fields, enabling precise estimation of large motions. The experimental results show that the proposed method surpasses state-of-the-art techniques in both fixed-size and continuous space-time video super-resolution tasks.
4/10/2024
👀
DVMSR: Distillated Vision Mamba for Efficient Super-Resolution
Xiaoyan Lei, Wenlong Zhang, Weifeng Cao
0
0
Efficient Image Super-Resolution (SR) aims to accelerate SR network inference by minimizing computational complexity and network parameters while preserving performance. Existing state-of-the-art Efficient Image Super-Resolution methods are based on convolutional neural networks. Few attempts have been made with Mamba to harness its long-range modeling capability and efficient computational complexity, which have shown impressive performance on high-level vision tasks. In this paper, we propose DVMSR, a novel lightweight Image SR network that incorporates Vision Mamba and a distillation strategy. The network of DVMSR consists of three modules: feature extraction convolution, multiple stacked Residual State Space Blocks (RSSBs), and a reconstruction module. Specifically, the deep feature extraction module is composed of several residual state space blocks (RSSB), each of which has several Vision Mamba Moudles(ViMM) together with a residual connection. To achieve efficiency improvement while maintaining comparable performance, we employ a distillation strategy to the vision Mamba network for superior performance. Specifically, we leverage the rich representation knowledge of teacher network as additional supervision for the output of lightweight student networks. Extensive experiments have demonstrated that our proposed DVMSR can outperform state-of-the-art efficient SR methods in terms of model parameters while maintaining the performance of both PSNR and SSIM. The source code is available at https://github.com/nathan66666/DVMSR.git
5/14/2024
VideoGigaGAN: Towards Detail-rich Video Super-Resolution
Yiran Xu, Taesung Park, Richard Zhang, Yang Zhou, Eli Shechtman, Feng Liu, Jia-Bin Huang, Difan Liu
0
0
Video super-resolution (VSR) approaches have shown impressive temporal consistency in upsampled videos. However, these approaches tend to generate blurrier results than their image counterparts as they are limited in their generative capability. This raises a fundamental question: can we extend the success of a generative image upsampler to the VSR task while preserving the temporal consistency? We introduce VideoGigaGAN, a new generative VSR model that can produce videos with high-frequency details and temporal consistency. VideoGigaGAN builds upon a large-scale image upsampler -- GigaGAN. Simply inflating GigaGAN to a video model by adding temporal modules produces severe temporal flickering. We identify several key issues and propose techniques that significantly improve the temporal consistency of upsampled videos. Our experiments show that, unlike previous VSR methods, VideoGigaGAN generates temporally consistent videos with more fine-grained appearance details. We validate the effectiveness of VideoGigaGAN by comparing it with state-of-the-art VSR models on public datasets and showcasing video results with $8times$ super-resolution.
5/3/2024