ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models

0

Sign in to get full access
Overview
- This paper introduces a method called ViewDiff for generating 3D-consistent images from text descriptions using text-to-image models.
- It aims to address the challenge of generating 3D-consistent content from 2D text-to-image models.
- The approach leverages multiple views of the same 3D scene to train the text-to-image model and ensure 3D consistency.
Plain English Explanation
The paper presents a technique called ViewDiff that allows text-to-image models to generate 3D-consistent images. This is an important capability because most existing text-to-image models only produce 2D images, which can lack depth and realism.
The key idea behind ViewDiff is to train the text-to-image model using multiple views of the same 3D scene. By exposing the model to different perspectives of the same object or environment, it can learn to generate images that are consistent in 3D space, rather than just producing flat, 2D renderings.
For example, if you describe a chair in a text prompt, a regular text-to-image model might generate a single 2D image of the chair. In contrast, ViewDiff would generate multiple views of the chair - from the front, side, and back - that all fit together seamlessly in 3D. This ensures that the generated images accurately reflect the 3D structure of the described object or scene.
By achieving this 3D consistency, the ViewDiff approach can produce more realistic and immersive images that better match our real-world experience. This could be particularly useful for applications like virtual reality, game development, or product visualization, where 3D content is essential.
Technical Explanation
The ViewDiff approach works by training the text-to-image model on a dataset of 3D scenes, where each scene is represented by multiple 2D views. The model is then trained to generate these multiple views from a given text prompt, ensuring that the generated images are consistent with each other in 3D space.
The key components of the ViewDiff method are:
-
Multi-view Dataset: The researchers collected a dataset of 3D scenes, each represented by multiple 2D views from different angles. This allows the model to learn the 3D structure of the scenes during training.
-
View Consistency Loss: In addition to the standard text-to-image training objective, the researchers introduced a "view consistency" loss that encourages the generated images to be geometrically consistent across multiple views of the same scene.
-
View Synthesis: During inference, the trained model can generate multiple consistent views of a scene from a single text prompt, effectively reconstructing the 3D structure of the described content.
The experiments conducted in the paper demonstrate that ViewDiff can generate visually appealing 3D-consistent images across a variety of scene types, outperforming baseline text-to-image models in terms of 3D consistency and realism.
Critical Analysis
The ViewDiff approach represents an important step forward in addressing the challenge of generating 3D-consistent content from 2D text-to-image models. By leveraging multiple views of 3D scenes during training, the model is able to learn the underlying 3D structure of the described content, leading to more realistic and immersive image generation.
However, the paper acknowledges several limitations and areas for future research:
-
Dataset Constraints: The current multi-view dataset used for training is relatively small and limited to specific scene types. Expanding the dataset to cover a wider range of 3D content could further improve the model's capabilities.
-
Computational Complexity: Generating multiple consistent views during inference can be computationally expensive, which may limit the practical deployment of ViewDiff in real-time applications.
-
Generalization Ability: While ViewDiff demonstrates strong performance on the evaluated tasks, it's unclear how well the approach would generalize to more complex or unseen 3D scenes, particularly those with intricate geometries or novel compositions.
-
User Experience Considerations: The paper does not explore the user experience implications of 3D-consistent image generation, such as how these images might be integrated into various applications or how users might interact with them.
Addressing these limitations and exploring the broader implications of 3D-consistent image generation could be valuable areas for future research in this field.
Conclusion
The ViewDiff approach presented in this paper represents a significant advancement in the field of text-to-image generation, addressing the important challenge of producing 3D-consistent visual content. By leveraging multiple views of 3D scenes during training, the model is able to learn the underlying 3D structure of the described content, leading to more realistic and immersive image generation.
The potential applications of this technology are wide-ranging, from virtual reality and game development to product visualization and architectural design. As text-to-image models continue to evolve, techniques like ViewDiff will be crucial for bridging the gap between 2D and 3D, ultimately enabling more natural and intuitive ways for humans to interact with and experience digital content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models
Lukas Hollein, Aljav{z} Bov{z}iv{c}, Norman Muller, David Novotny, Hung-Yu Tseng, Christian Richardt, Michael Zollhofer, Matthias Nie{ss}ner
3D asset generation is getting massive amounts of attention, inspired by the recent success of text-guided 2D content creation. Existing text-to-3D methods use pretrained text-to-image diffusion models in an optimization problem or fine-tune them on synthetic data, which often results in non-photorealistic 3D objects without backgrounds. In this paper, we present a method that leverages pretrained text-to-image models as a prior, and learn to generate multi-view images in a single denoising process from real-world data. Concretely, we propose to integrate 3D volume-rendering and cross-frame-attention layers into each block of the existing U-Net network of the text-to-image model. Moreover, we design an autoregressive generation that renders more 3D-consistent images at any viewpoint. We train our model on real-world datasets of objects and showcase its capabilities to generate instances with a variety of high-quality shapes and textures in authentic surroundings. Compared to the existing methods, the results generated by our method are consistent, and have favorable visual quality (-30% FID, -37% KID).
Read more7/30/2024
0
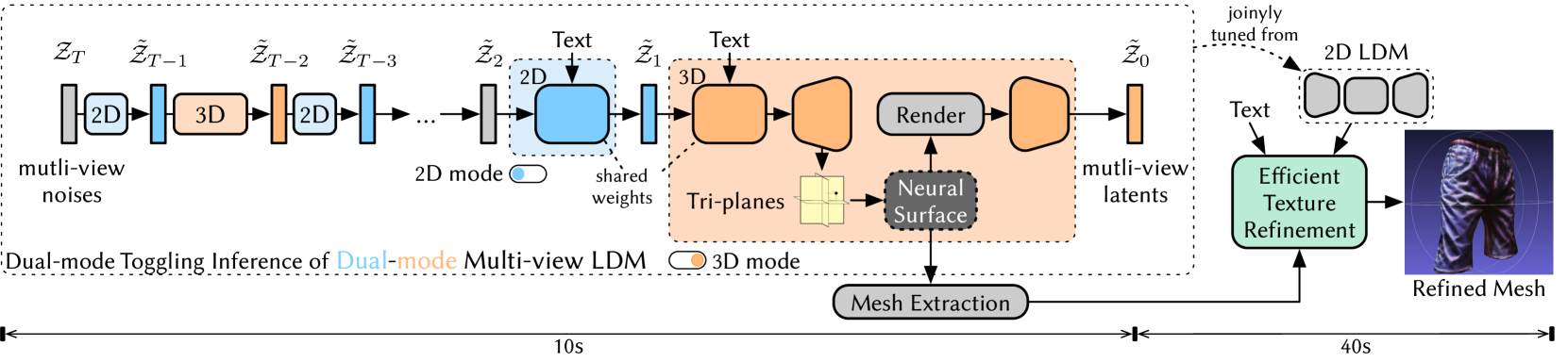
Dual3D: Efficient and Consistent Text-to-3D Generation with Dual-mode Multi-view Latent Diffusion
Xinyang Li, Zhangyu Lai, Linning Xu, Jianfei Guo, Liujuan Cao, Shengchuan Zhang, Bo Dai, Rongrong Ji
We present Dual3D, a novel text-to-3D generation framework that generates high-quality 3D assets from texts in only $1$ minute.The key component is a dual-mode multi-view latent diffusion model. Given the noisy multi-view latents, the 2D mode can efficiently denoise them with a single latent denoising network, while the 3D mode can generate a tri-plane neural surface for consistent rendering-based denoising. Most modules for both modes are tuned from a pre-trained text-to-image latent diffusion model to circumvent the expensive cost of training from scratch. To overcome the high rendering cost during inference, we propose the dual-mode toggling inference strategy to use only $1/10$ denoising steps with 3D mode, successfully generating a 3D asset in just $10$ seconds without sacrificing quality. The texture of the 3D asset can be further enhanced by our efficient texture refinement process in a short time. Extensive experiments demonstrate that our method delivers state-of-the-art performance while significantly reducing generation time. Our project page is available at https://dual3d.github.io
Read more5/17/2024

0
VividDreamer: Towards High-Fidelity and Efficient Text-to-3D Generation
Zixuan Chen, Ruijie Su, Jiahao Zhu, Lingxiao Yang, Jian-Huang Lai, Xiaohua Xie
Text-to-3D generation aims to create 3D assets from text-to-image diffusion models. However, existing methods face an inherent bottleneck in generation quality because the widely-used objectives such as Score Distillation Sampling (SDS) inappropriately omit U-Net jacobians for swift generation, leading to significant bias compared to the true gradient obtained by full denoising sampling. This bias brings inconsistent updating direction, resulting in implausible 3D generation e.g., color deviation, Janus problem, and semantically inconsistent details). In this work, we propose Pose-dependent Consistency Distillation Sampling (PCDS), a novel yet efficient objective for diffusion-based 3D generation tasks. Specifically, PCDS builds the pose-dependent consistency function within diffusion trajectories, allowing to approximate true gradients through minimal sampling steps (1-3). Compared to SDS, PCDS can acquire a more accurate updating direction with the same sampling time (1 sampling step), while enabling few-step (2-3) sampling to trade compute for higher generation quality. For efficient generation, we propose a coarse-to-fine optimization strategy, which first utilizes 1-step PCDS to create the basic structure of 3D objects, and then gradually increases PCDS steps to generate fine-grained details. Extensive experiments demonstrate that our approach outperforms the state-of-the-art in generation quality and training efficiency, conspicuously alleviating the implausible 3D generation issues caused by the deviated updating direction. Moreover, it can be simply applied to many 3D generative applications to yield impressive 3D assets, please see our project page: https://narcissusex.github.io/VividDreamer.
Read more6/24/2024
0
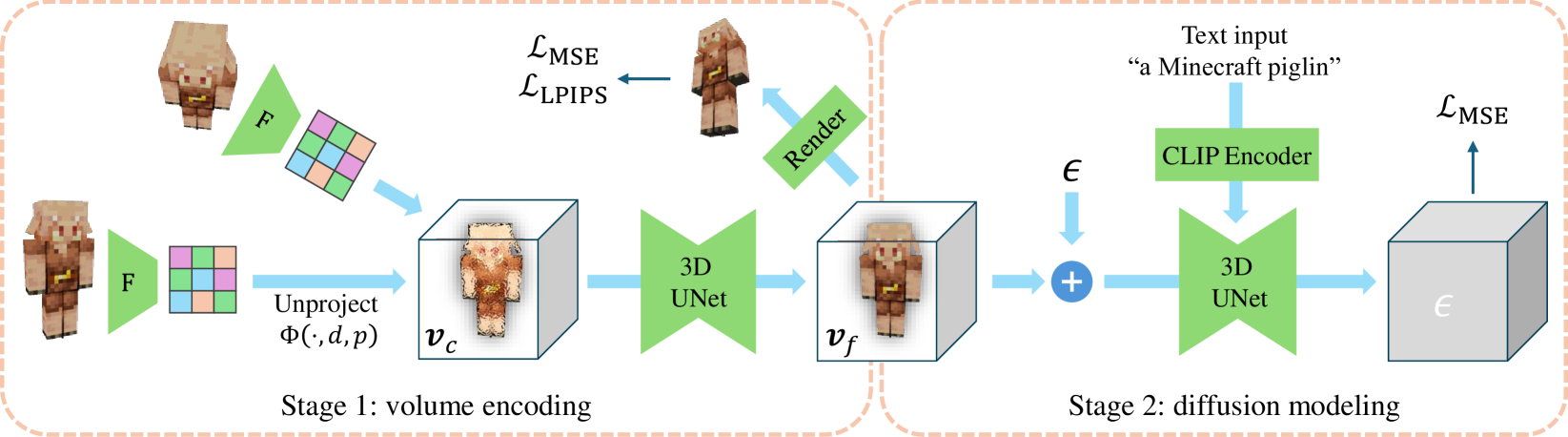
VolumeDiffusion: Flexible Text-to-3D Generation with Efficient Volumetric Encoder
Zhicong Tang, Shuyang Gu, Chunyu Wang, Ting Zhang, Jianmin Bao, Dong Chen, Baining Guo
This paper introduces a pioneering 3D volumetric encoder designed for text-to-3D generation. To scale up the training data for the diffusion model, a lightweight network is developed to efficiently acquire feature volumes from multi-view images. The 3D volumes are then trained on a diffusion model for text-to-3D generation using a 3D U-Net. This research further addresses the challenges of inaccurate object captions and high-dimensional feature volumes. The proposed model, trained on the public Objaverse dataset, demonstrates promising outcomes in producing diverse and recognizable samples from text prompts. Notably, it empowers finer control over object part characteristics through textual cues, fostering model creativity by seamlessly combining multiple concepts within a single object. This research significantly contributes to the progress of 3D generation by introducing an efficient, flexible, and scalable representation methodology.
Read more8/14/2024