Vim-F: Visual State Space Model Benefiting from Learning in the Frequency Domain

0

Sign in to get full access
Overview
• This paper introduces Vim-F, a visual state space model that leverages learning in the frequency domain to improve performance.
• Vim-F builds on previous work on visual state space models, such as VMAMBA and Multi-Scale VMAMBA, by incorporating frequency domain learning.
• The key idea is to learn a frequency-based representation of the visual state that can capture long-range dependencies more effectively than spatial-domain approaches.
Plain English Explanation
Vim-F is a new type of visual model that tries to understand images and videos in a different way than traditional approaches. Rather than just looking at the pixels directly, Vim-F looks at the underlying frequencies or patterns in the data.
The researchers behind Vim-F believe that analyzing the frequency domain, rather than just the spatial domain, can help the model better capture the important long-range relationships in visual data. This is similar to how our own eyes and brains process visual information by detecting patterns and edges at different scales.
By incorporating this frequency-based learning, Vim-F is able to build a more powerful "internal representation" of the visual state that can be used for tasks like object recognition, image generation, and video understanding. The VMAMBA and Multi-Scale VMAMBA models provided a good starting point, but Vim-F takes things further by explicitly leveraging the frequency domain.
Technical Explanation
The core of Vim-F is a visual state space model that learns a latent representation of the visual state by analyzing the input data in the frequency domain. This is in contrast to more traditional approaches that focus solely on the spatial domain.
The authors draw inspiration from prior work on VMAMBA and Multi-Scale VMAMBA, which showed the benefits of modeling the visual state using a state space formulation. Vim-F extends this by incorporating a frequency-domain learning component, which allows the model to better capture long-range dependencies in the visual data.
Specifically, Vim-F includes a Fourier transform module that converts the input images/videos into the frequency domain. This frequency-domain representation is then fed into the state space model, which learns to construct a latent state that encodes the essential visual information. The authors demonstrate how this frequency-assisted approach outperforms spatial-only models on a range of visual understanding tasks.
Critical Analysis
The authors provide a thorough evaluation of Vim-F, comparing it to several baseline methods on tasks like object recognition, image generation, and video prediction. The results indicate that the frequency-domain learning component does indeed provide tangible benefits over spatial-only approaches.
However, the paper does not delve deeply into the limitations of the Vim-F model. For example, it would be helpful to understand how the frequency-domain representation impacts the model's interpretability and whether there are any failure modes or edge cases where the approach struggles.
Additionally, the authors could have provided more insight into the specific mechanisms by which the frequency-based learning leads to performance gains. A deeper examination of the internal representations learned by Vim-F could shed light on the key factors driving its improved performance.
Overall, the Vim-F model represents an interesting and promising direction for visual state space modeling. However, further research is needed to fully understand its strengths, weaknesses, and the broader implications for the field of computer vision.
Conclusion
The Vim-F model presented in this paper introduces a novel approach to visual state space modeling that incorporates frequency-domain learning. By explicitly analyzing the frequency characteristics of visual data, Vim-F is able to capture long-range dependencies more effectively than spatial-only models.
The experimental results demonstrate the benefits of this frequency-assisted approach, with Vim-F outperforming baseline methods on a variety of visual understanding tasks. While the paper does not explore all the potential limitations of the model, it represents an important step forward in leveraging the frequency domain for improved visual representation learning.
As the field of computer vision continues to evolve, techniques like Vim-F that can extract more powerful visual features will likely play an increasingly crucial role in advancing the state of the art. The authors' work on Vim-F provides a valuable contribution to this ongoing effort.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Vim-F: Visual State Space Model Benefiting from Learning in the Frequency Domain
Juntao Zhang, Kun Bian, Peng Cheng, Wenbo An, Jianning Liu, Jun Zhou
In recent years, State Space Models (SSMs) with efficient hardware-aware designs, known as the Mamba deep learning models, have made significant progress in modeling long sequences such as language understanding. Therefore, building efficient and general-purpose visual backbones based on SSMs is a promising direction. Compared to traditional convolutional neural networks (CNNs) and Vision Transformers (ViTs), the performance of Vision Mamba (ViM) methods is not yet fully competitive. To enable SSMs to process image data, ViMs typically flatten 2D images into 1D sequences, inevitably ignoring some 2D local dependencies, thereby weakening the model's ability to interpret spatial relationships from a global perspective. We use Fast Fourier Transform (FFT) to obtain the spectrum of the feature map and add it to the original feature map, enabling ViM to model a unified visual representation in both frequency and spatial domains. The introduction of frequency domain information enables ViM to have a global receptive field during scanning. We propose a novel model called Vim-F, which employs pure Mamba encoders and scans in both the frequency and spatial domains. Moreover, we question the necessity of position embedding in ViM and remove it accordingly in Vim-F, which helps to fully utilize the efficient long-sequence modeling capability of ViM. Finally, we redesign a patch embedding for Vim-F, leveraging a convolutional stem to capture more local correlations, further improving the performance of Vim-F. Code is available at: url{https://github.com/yws-wxs/Vim-F}.
Read more5/30/2024
📈
0
Multi-Scale VMamba: Hierarchy in Hierarchy Visual State Space Model
Yuheng Shi, Minjing Dong, Chang Xu
Despite the significant achievements of Vision Transformers (ViTs) in various vision tasks, they are constrained by the quadratic complexity. Recently, State Space Models (SSMs) have garnered widespread attention due to their global receptive field and linear complexity with respect to the input length, demonstrating substantial potential across fields including natural language processing and computer vision. To improve the performance of SSMs in vision tasks, a multi-scan strategy is widely adopted, which leads to significant redundancy of SSMs. For a better trade-off between efficiency and performance, we analyze the underlying reasons behind the success of the multi-scan strategy, where long-range dependency plays an important role. Based on the analysis, we introduce Multi-Scale Vision Mamba (MSVMamba) to preserve the superiority of SSMs in vision tasks with limited parameters. It employs a multi-scale 2D scanning technique on both original and downsampled feature maps, which not only benefits long-range dependency learning but also reduces computational costs. Additionally, we integrate a Convolutional Feed-Forward Network (ConvFFN) to address the lack of channel mixing. Our experiments demonstrate that MSVMamba is highly competitive, with the MSVMamba-Tiny model achieving 82.8% top-1 accuracy on ImageNet, 46.9% box mAP, and 42.2% instance mAP with the Mask R-CNN framework, 1x training schedule on COCO, and 47.6% mIoU with single-scale testing on ADE20K.Code is available at url{https://github.com/YuHengsss/MSVMamba}.
Read more5/24/2024
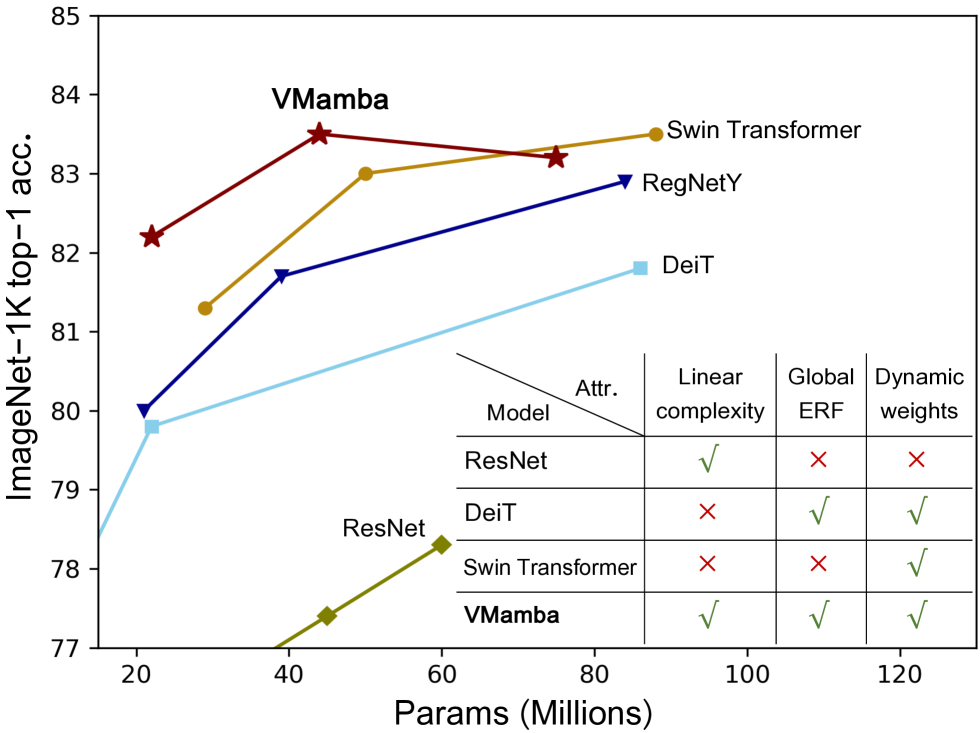
0
VMamba: Visual State Space Model
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Yunfan Liu
Designing computationally efficient network architectures persists as an ongoing necessity in computer vision. In this paper, we transplant Mamba, a state-space language model, into VMamba, a vision backbone that works in linear time complexity. At the core of VMamba lies a stack of Visual State-Space (VSS) blocks with the 2D Selective Scan (SS2D) module. By traversing along four scanning routes, SS2D helps bridge the gap between the ordered nature of 1D selective scan and the non-sequential structure of 2D vision data, which facilitates the gathering of contextual information from various sources and perspectives. Based on the VSS blocks, we develop a family of VMamba architectures and accelerate them through a succession of architectural and implementation enhancements. Extensive experiments showcase VMamba's promising performance across diverse visual perception tasks, highlighting its advantages in input scaling efficiency compared to existing benchmark models. Source code is available at https://github.com/MzeroMiko/VMamba.
Read more5/28/2024
🖼️
0
Frequency-Assisted Mamba for Remote Sensing Image Super-Resolution
Yi Xiao, Qiangqiang Yuan, Kui Jiang, Yuzeng Chen, Qiang Zhang, Chia-Wen Lin
Recent progress in remote sensing image (RSI) super-resolution (SR) has exhibited remarkable performance using deep neural networks, e.g., Convolutional Neural Networks and Transformers. However, existing SR methods often suffer from either a limited receptive field or quadratic computational overhead, resulting in sub-optimal global representation and unacceptable computational costs in large-scale RSI. To alleviate these issues, we develop the first attempt to integrate the Vision State Space Model (Mamba) for RSI-SR, which specializes in processing large-scale RSI by capturing long-range dependency with linear complexity. To achieve better SR reconstruction, building upon Mamba, we devise a Frequency-assisted Mamba framework, dubbed FMSR, to explore the spatial and frequent correlations. In particular, our FMSR features a multi-level fusion architecture equipped with the Frequency Selection Module (FSM), Vision State Space Module (VSSM), and Hybrid Gate Module (HGM) to grasp their merits for effective spatial-frequency fusion. Considering that global and local dependencies are complementary and both beneficial for SR, we further recalibrate these multi-level features for accurate feature fusion via learnable scaling adaptors. Extensive experiments on AID, DOTA, and DIOR benchmarks demonstrate that our FMSR outperforms state-of-the-art Transformer-based methods HAT-L in terms of PSNR by 0.11 dB on average, while consuming only 28.05% and 19.08% of its memory consumption and complexity, respectively. Code will be available at https://github.com/XY-boy/FreMamba
Read more8/30/2024