ViSpeR: Multilingual Audio-Visual Speech Recognition
2406.00038
0
0
🗣️
Abstract
This work presents an extensive and detailed study on Audio-Visual Speech Recognition (AVSR) for five widely spoken languages: Chinese, Spanish, English, Arabic, and French. We have collected large-scale datasets for each language except for English, and have engaged in the training of supervised learning models. Our model, ViSpeR, is trained in a multi-lingual setting, resulting in competitive performance on newly established benchmarks for each language. The datasets and models are released to the community with an aim to serve as a foundation for triggering and feeding further research work and exploration on Audio-Visual Speech Recognition, an increasingly important area of research. Code available at href{https://github.com/YasserdahouML/visper}{https://github.com/YasserdahouML/visper}.
Create account to get full access
Overview
- This paper introduces ViSpeR, a novel multilingual audio-visual speech recognition (AVSR) dataset and models that can transcribe speech in multiple languages from video data.
- ViSpeR consists of over 1,000 hours of audio-visual data across 40 languages, making it one of the largest and most diverse AVSR datasets to date.
- The authors propose several AVSR models, including a hybrid CTC-RNN model and a multi-layer cross-attention fusion model, that achieve state-of-the-art performance on ViSpeR and other AVSR benchmarks.
- The paper also discusses the potential benefits of leveraging audio-visual data for large-scale multilingual automatic speech recognition and unified video-language pre-training.
Plain English Explanation
The researchers created a new dataset called ViSpeR that contains over 1,000 hours of video and audio data in 40 different languages. This makes it one of the largest and most diverse datasets for training AI models to transcribe speech from videos.
The researchers then developed several machine learning models that can use this audio-visual data to accurately transcribe speech in multiple languages. One of these models combines two common techniques, called Connectionist Temporal Classification (CTC) and Recurrent Neural Networks (RNNs), to effectively process the video and audio information together.
Another model uses a more complex "multi-layer cross-attention" approach to fuse the visual and audio cues. These models outperform previous state-of-the-art methods on ViSpeR and other speech recognition benchmarks.
The researchers believe that this kind of multilingual audio-visual speech recognition technology could be very useful for large-scale industrial speech recognition systems as well as for unifying video and language understanding in AI models.
Technical Explanation
The paper introduces the ViSpeR dataset, which contains over 1,000 hours of audio-visual data across 40 languages. This makes it one of the largest and most diverse AVSR datasets available. The authors describe the data collection and processing methodology used to create ViSpeR.
The paper then proposes several AVSR models for ViSpeR. One is a hybrid CTC-RNN architecture that takes both video and audio inputs and uses a combination of CTC loss and RNN-based sequence modeling. Another is a multi-layer cross-attention fusion model that learns to effectively integrate the visual and acoustic features.
Experiments show that these AVSR models significantly outperform previous state-of-the-art methods on ViSpeR and other AVSR benchmarks. The authors also discuss the potential benefits of leveraging audio-visual data for large-scale multilingual automatic speech recognition and unified video-language pre-training.
Critical Analysis
The paper provides a thorough evaluation of the ViSpeR dataset and proposed AVSR models, demonstrating their strong performance on several benchmarks. However, the authors do not discuss potential limitations or ethical considerations around the development and deployment of such multilingual speech recognition technology.
For example, the dataset may not fully represent the linguistic diversity and accents found in real-world multilingual settings. There could also be privacy concerns around collecting and using audio-visual data for speech recognition, especially for vulnerable populations.
Additionally, the paper does not address potential biases or fairness issues that may arise when applying these models across different languages and demographics. Further research is needed to ensure that multilingual AVSR systems are developed and deployed responsibly and equitably.
Conclusion
This paper presents a novel multilingual audio-visual speech recognition dataset called ViSpeR and several state-of-the-art AVSR models that leverage it. The large scale and diversity of ViSpeR, along with the strong performance of the proposed models, suggest that audio-visual data could be a valuable resource for building robust, multilingual speech recognition systems.
The authors also highlight the potential for using AVSR technology in large-scale industrial applications and for advancing unified video-language understanding. However, more work is needed to address the ethical and fairness considerations around deploying such systems in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
Multilingual Audio-Visual Speech Recognition with Hybrid CTC/RNN-T Fast Conformer
Maxime Burchi, Krishna C. Puvvada, Jagadeesh Balam, Boris Ginsburg, Radu Timofte
0
0
Humans are adept at leveraging visual cues from lip movements for recognizing speech in adverse listening conditions. Audio-Visual Speech Recognition (AVSR) models follow similar approach to achieve robust speech recognition in noisy conditions. In this work, we present a multilingual AVSR model incorporating several enhancements to improve performance and audio noise robustness. Notably, we adapt the recently proposed Fast Conformer model to process both audio and visual modalities using a novel hybrid CTC/RNN-T architecture. We increase the amount of audio-visual training data for six distinct languages, generating automatic transcriptions of unlabelled multilingual datasets (VoxCeleb2 and AVSpeech). Our proposed model achieves new state-of-the-art performance on the LRS3 dataset, reaching WER of 0.8%. On the recently introduced MuAViC benchmark, our model yields an absolute average-WER reduction of 11.9% in comparison to the original baseline. Finally, we demonstrate the ability of the proposed model to perform audio-only, visual-only, and audio-visual speech recognition at test time.
5/24/2024
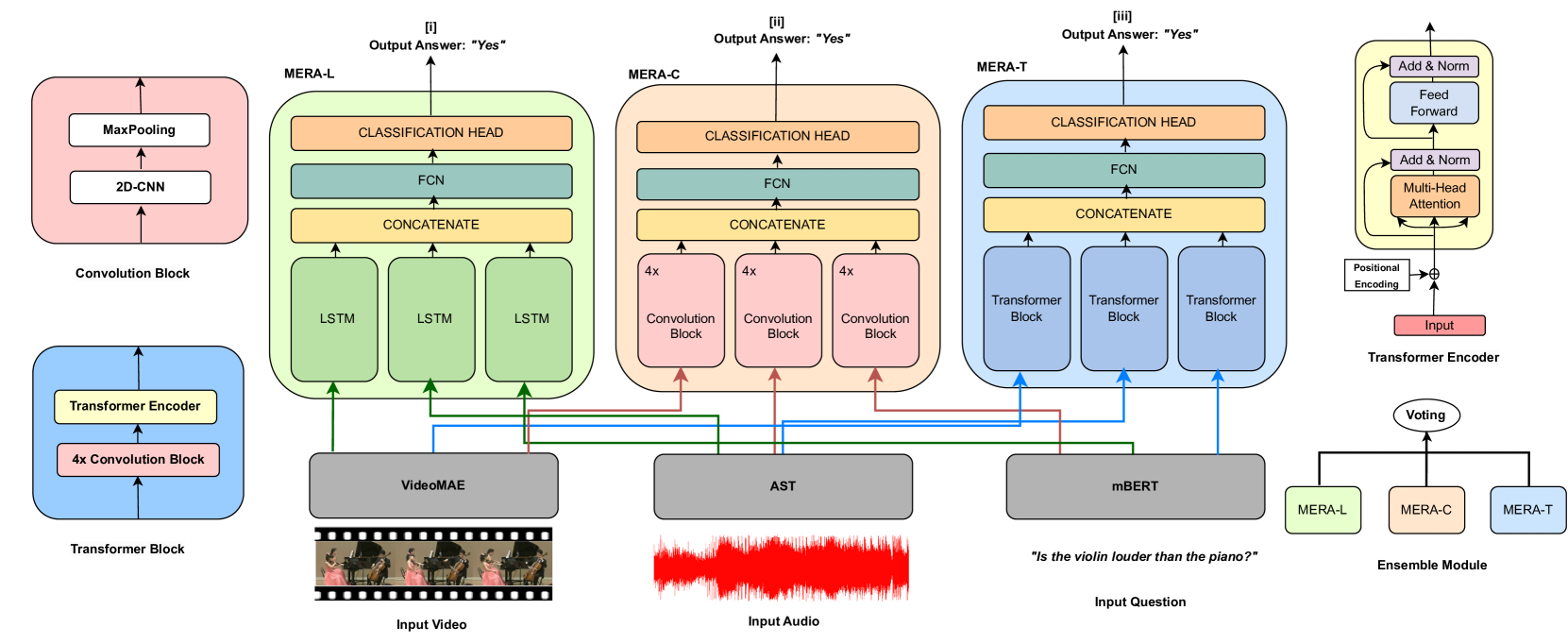
Towards Multilingual Audio-Visual Question Answering
Orchid Chetia Phukan, Priyabrata Mallick, Swarup Ranjan Behera, Aalekhya Satya Narayani, Arun Balaji Buduru, Rajesh Sharma
0
0
In this paper, we work towards extending Audio-Visual Question Answering (AVQA) to multilingual settings. Existing AVQA research has predominantly revolved around English and replicating it for addressing AVQA in other languages requires a substantial allocation of resources. As a scalable solution, we leverage machine translation and present two multilingual AVQA datasets for eight languages created from existing benchmark AVQA datasets. This prevents extra human annotation efforts of collecting questions and answers manually. To this end, we propose, MERA framework, by leveraging state-of-the-art (SOTA) video, audio, and textual foundation models for AVQA in multiple languages. We introduce a suite of models namely MERA-L, MERA-C, MERA-T with varied model architectures to benchmark the proposed datasets. We believe our work will open new research directions and act as a reference benchmark for future works in multilingual AVQA.
6/14/2024

MLCA-AVSR: Multi-Layer Cross Attention Fusion based Audio-Visual Speech Recognition
He Wang, Pengcheng Guo, Pan Zhou, Lei Xie
0
0
While automatic speech recognition (ASR) systems degrade significantly in noisy environments, audio-visual speech recognition (AVSR) systems aim to complement the audio stream with noise-invariant visual cues and improve the system's robustness. However, current studies mainly focus on fusing the well-learned modality features, like the output of modality-specific encoders, without considering the contextual relationship during the modality feature learning. In this study, we propose a multi-layer cross-attention fusion based AVSR (MLCA-AVSR) approach that promotes representation learning of each modality by fusing them at different levels of audio/visual encoders. Experimental results on the MISP2022-AVSR Challenge dataset show the efficacy of our proposed system, achieving a concatenated minimum permutation character error rate (cpCER) of 30.57% on the Eval set and yielding up to 3.17% relative improvement compared with our previous system which ranked the second place in the challenge. Following the fusion of multiple systems, our proposed approach surpasses the first-place system, establishing a new SOTA cpCER of 29.13% on this dataset.
4/9/2024
💬
SpeechVerse: A Large-scale Generalizable Audio Language Model
Nilaksh Das, Saket Dingliwal, Srikanth Ronanki, Rohit Paturi, Zhaocheng Huang, Prashant Mathur, Jie Yuan, Dhanush Bekal, Xing Niu, Sai Muralidhar Jayanthi, Xilai Li, Karel Mundnich, Monica Sunkara, Sundararajan Srinivasan, Kyu J Han, Katrin Kirchhoff
0
0
Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
6/3/2024