SpeechVerse: A Large-scale Generalizable Audio Language Model
2405.08295
0
0
💬
Abstract
Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
Create account to get full access
Overview
- Large language models (LLMs) have shown impressive abilities in understanding and following natural language instructions, but their capabilities are often limited to specific tasks.
- The researchers developed SpeechVerse, a framework that combines pre-trained speech and text foundation models to achieve robust multi-task performance on a diverse range of speech processing tasks using natural language instructions.
- The model is trained using a curriculum learning approach, leveraging continuous latent representations from a speech foundation model.
- Extensive benchmarking shows the SpeechVerse model outperforms traditional task-specific baselines on the majority of the evaluated tasks.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly skilled at understanding and following natural language instructions. However, these models are often limited to specific tasks, like speech recognition or translation.
The researchers behind SpeechVerse wanted to create a more versatile model that could handle a wider range of speech processing tasks. They did this by combining pre-trained speech and text models using a small set of learnable parameters, while keeping the pre-trained models frozen during training.
The key innovation is the use of curriculum learning, a training approach that starts with simpler tasks and gradually increases the difficulty. This allows the model to learn in a structured way, building up its capabilities over time.
The researchers tested SpeechVerse on a variety of speech processing tasks, and found that it outperformed traditional task-specific models on most of them. This suggests that the model has developed a more general understanding of speech and language, rather than being limited to specific applications.
Overall, SpeechVerse represents an important step forward in developing language models that can understand and process speech in a more flexible and adaptable way. This could have applications in areas like virtual assistants, language learning, and accessibility technology.
Technical Explanation
The researchers developed SpeechVerse, a multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models. The speech foundation model is used to extract continuous latent representations, which are then used to fine-tune the model on a diverse range of speech processing tasks using natural language instructions.
The key aspects of the SpeechVerse approach include:
- Multimodal Integration: The framework integrates pre-trained speech and text foundation models, such as AudioChatLLaMA and GPT-3, through a small set of learnable parameters, while keeping the pre-trained models frozen during training.
- Curriculum Learning: The model is trained using a curriculum learning approach, where the difficulty of the tasks gradually increases over the training process. This allows the model to build its capabilities in a structured way.
- Continuous Latent Representations: The speech foundation model is used to extract continuous latent representations of the speech input, which are then used to fine-tune the model on the target tasks.
- Instruction Finetuning: The model is fine-tuned using natural language instructions, allowing it to perform a diverse range of speech processing tasks.
The researchers conducted extensive benchmarking, comparing the SpeechVerse model's performance against traditional task-specific baselines across several datasets and tasks. The results show that the SpeechVerse model outperforms the baselines on 9 out of the 11 evaluated tasks, demonstrating its superior generalization capabilities.
Critical Analysis
The researchers have presented a compelling approach to developing more versatile and adaptable language models for speech processing tasks. The use of curriculum learning and continuous latent representations appears to be a effective strategy for building models with robust multi-task capabilities.
However, the paper does not address some potential limitations of the SpeechVerse framework. For example, the model's performance on out-of-domain tasks or novel prompts is not extensively evaluated, and it's unclear how the model would handle significant distributional shift or unexpected inputs.
Additionally, the paper does not provide much insight into the specific architectural choices or training details that contribute to the model's performance. A more detailed discussion of the design decisions and their rationale would have been helpful for understanding the key innovations.
Finally, the paper does not explore the potential ethical implications of developing such powerful language models, particularly in areas like fairness, bias, and safety. As these models become more capable, it will be crucial to consider their societal impact and ensure they are developed responsibly.
Overall, the SpeechVerse framework represents an important step forward in the development of more versatile and adaptable language models for speech processing tasks. However, further research is needed to fully understand the model's limitations and potential risks.
Conclusion
The SpeechVerse framework developed by the researchers represents a significant advancement in the field of language models for speech processing. By combining pre-trained speech and text foundation models and using curriculum learning and continuous latent representations, the model demonstrates impressive multi-task capabilities that outperform traditional task-specific baselines.
This work has important implications for the development of more versatile and adaptable language models, which could have a wide range of applications in areas like virtual assistants, language learning, and accessibility technology. As the capabilities of these models continue to expand, it will be crucial to carefully consider the ethical implications and ensure they are developed responsibly.
Overall, the SpeechVerse framework is an important step forward in the quest to create language models that can truly understand and process speech in a flexible and generalized way.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
UniverSLU: Universal Spoken Language Understanding for Diverse Tasks with Natural Language Instructions
Siddhant Arora, Hayato Futami, Jee-weon Jung, Yifan Peng, Roshan Sharma, Yosuke Kashiwagi, Emiru Tsunoo, Karen Livescu, Shinji Watanabe
0
0
Recent studies leverage large language models with multi-tasking capabilities, using natural language prompts to guide the model's behavior and surpassing performance of task-specific models. Motivated by this, we ask: can we build a single model that jointly performs various spoken language understanding (SLU) tasks? We start by adapting a pre-trained automatic speech recognition model to additional tasks using single-token task specifiers. We enhance this approach through instruction tuning, i.e., finetuning by describing the task using natural language instructions followed by the list of label options. Our approach can generalize to new task descriptions for the seen tasks during inference, thereby enhancing its user-friendliness. We demonstrate the efficacy of our single multi-task learning model UniverSLU for 12 speech classification and sequence generation task types spanning 17 datasets and 9 languages. On most tasks, UniverSLU achieves competitive performance and often even surpasses task-specific models. Additionally, we assess the zero-shot capabilities, finding that the model generalizes to new datasets and languages for seen task types.
4/4/2024
🧠
SpeechX: Neural Codec Language Model as a Versatile Speech Transformer
Xiaofei Wang, Manthan Thakker, Zhuo Chen, Naoyuki Kanda, Sefik Emre Eskimez, Sanyuan Chen, Min Tang, Shujie Liu, Jinyu Li, Takuya Yoshioka
0
0
Recent advancements in generative speech models based on audio-text prompts have enabled remarkable innovations like high-quality zero-shot text-to-speech. However, existing models still face limitations in handling diverse audio-text speech generation tasks involving transforming input speech and processing audio captured in adverse acoustic conditions. This paper introduces SpeechX, a versatile speech generation model capable of zero-shot TTS and various speech transformation tasks, dealing with both clean and noisy signals. SpeechX combines neural codec language modeling with multi-task learning using task-dependent prompting, enabling unified and extensible modeling and providing a consistent way for leveraging textual input in speech enhancement and transformation tasks. Experimental results show SpeechX's efficacy in various tasks, including zero-shot TTS, noise suppression, target speaker extraction, speech removal, and speech editing with or without background noise, achieving comparable or superior performance to specialized models across tasks. See https://aka.ms/speechx for demo samples.
6/27/2024
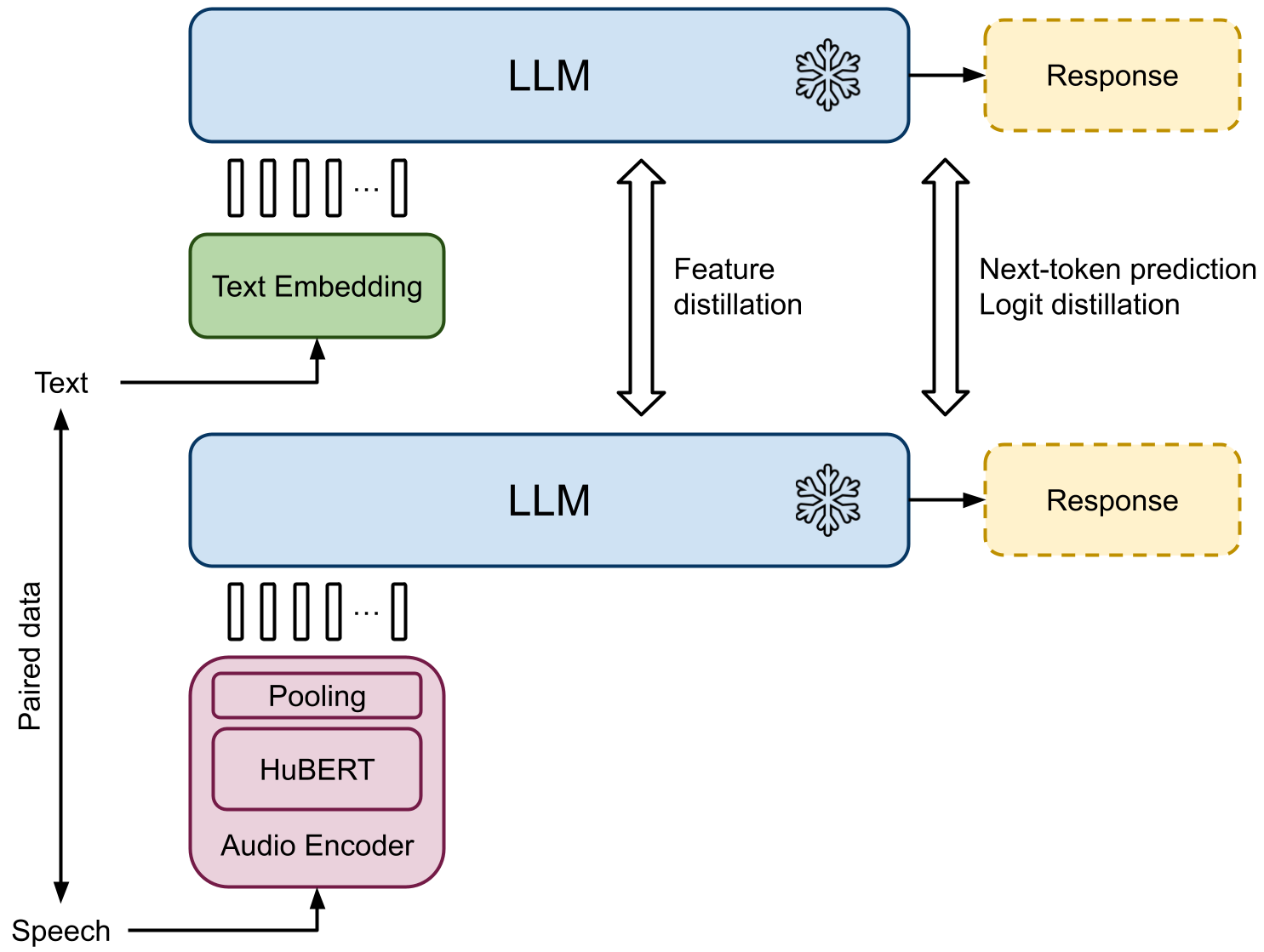
Prompting Large Language Models with Audio for General-Purpose Speech Summarization
Wonjune Kang, Deb Roy
0
0
In this work, we introduce a framework for speech summarization that leverages the processing and reasoning capabilities of large language models (LLMs). We propose an end-to-end system that combines an instruction-tuned LLM with an audio encoder that converts speech into token representations that the LLM can interpret. Using a dataset with paired speech-text data, the overall system is trained to generate consistent responses to prompts with the same semantic information regardless of the input modality. The resulting framework allows the LLM to process speech inputs in the same way as text, enabling speech summarization by simply prompting the LLM. Unlike prior approaches, our method is able to summarize spoken content from any arbitrary domain, and it can produce summaries in different styles by varying the LLM prompting strategy. Experiments demonstrate that our approach outperforms a cascade baseline of speech recognition followed by LLM text processing.
6/11/2024
🗣️
ViSpeR: Multilingual Audio-Visual Speech Recognition
Sanath Narayan, Yasser Abdelaziz Dahou Djilali, Ankit Singh, Eustache Le Bihan, Hakim Hacid
0
0
This work presents an extensive and detailed study on Audio-Visual Speech Recognition (AVSR) for five widely spoken languages: Chinese, Spanish, English, Arabic, and French. We have collected large-scale datasets for each language except for English, and have engaged in the training of supervised learning models. Our model, ViSpeR, is trained in a multi-lingual setting, resulting in competitive performance on newly established benchmarks for each language. The datasets and models are released to the community with an aim to serve as a foundation for triggering and feeding further research work and exploration on Audio-Visual Speech Recognition, an increasingly important area of research. Code available at href{https://github.com/YasserdahouML/visper}{https://github.com/YasserdahouML/visper}.
6/4/2024