Visual grounding for desktop graphical user interfaces

0

Sign in to get full access
Overview
- Explores using multi-modal AI systems to optimize graphical user interface (GUI) agents for visual instruction grounding
- Aims to improve the ability of AI assistants to understand and follow instructions related to GUI interactions
- Combines computer vision and natural language processing techniques to enable AI agents to interpret and execute GUI-based commands
Plain English Explanation
The research paper focuses on developing more advanced AI systems that can better understand and follow instructions related to graphical user interfaces (GUIs). Current AI assistants often struggle with tasks like navigating menus, clicking buttons, or interacting with various GUI elements based on verbal commands.
The researchers propose using a multi-modal AI approach that combines computer vision and natural language processing techniques. This allows the AI agent to both see and understand the visual elements of the GUI, as well as process the natural language instructions provided by the user. By optimizing the AI agent in this way, the goal is to improve its ability to correctly interpret and execute GUI-related commands.
This could have significant real-world applications, enabling users to more seamlessly control and interact with computer systems and applications using just their voice or natural language instructions, rather than relying solely on manual GUI interactions. It represents an important step forward in making AI-powered virtual assistants more capable and useful in everyday computing tasks.
Technical Explanation
The paper presents a novel approach for optimizing graphical user interface (GUI) agents using multi-modal artificial intelligence (AI) systems. The core idea is to combine computer vision and natural language processing techniques to enable AI assistants to better understand and execute instructions related to visual GUI elements.
The authors first review relevant prior work in areas like visual grounding, GUI-based AI assistants, and general vision-language models. They then outline their proposed architecture, which takes in both visual inputs (e.g. screenshots of a GUI) and textual instructions, and uses a multi-modal neural network to predict the appropriate GUI actions to take.
Key components of the system include:
- A computer vision module to analyze the GUI visual elements
- A natural language processing module to understand the user's instructions
- A multi-modal fusion module that integrates the visual and textual information
- A decision-making module that determines the optimal GUI actions to perform
The system is trained and evaluated on a dataset of GUI screenshots and corresponding natural language instructions for completing various tasks. Experimental results demonstrate significant improvements in the AI agent's ability to correctly interpret and execute GUI-based commands compared to prior approaches.
Critical Analysis
The research presented in this paper represents an important step forward in developing more capable and natural conversational AI agents that can seamlessly interact with graphical user interfaces. By combining computer vision and natural language processing, the proposed system overcomes key limitations of prior work that relied solely on one modality or the other.
However, the paper does acknowledge several potential limitations and areas for further research. For example, the current dataset and experiments are focused on a relatively narrow domain of GUI interactions. Scaling the approach to handle a wider range of GUI applications and tasks will likely require significantly larger and more diverse training data.
Additionally, the paper does not deeply explore potential issues around AI safety and robustness. As these systems become more advanced and integrated into critical computing workflows, it will be crucial to ensure they behave reliably and do not make harmful mistakes when interpreting user instructions or performing GUI actions.
Further research is also needed to understand the generalization capabilities of these multi-modal AI agents. Can the skills learned on one set of GUI applications transfer to novel interfaces and tasks, or will significant retraining be required? Addressing these types of questions will be important for making the technology truly scalable and practical.
Overall, this work represents an exciting advance in the field of AI-powered virtual assistants. With continued research and development, systems like the one proposed here have the potential to drastically improve the efficiency and accessibility of graphical user interfaces for all users.
Conclusion
This research paper outlines a novel approach for optimizing graphical user interface (GUI) agents using multi-modal artificial intelligence (AI) systems. By combining computer vision and natural language processing, the proposed system enables AI assistants to better understand and execute instructions related to visual GUI elements.
The technical work demonstrates significant improvements in the agent's ability to correctly interpret and perform GUI-based commands compared to prior methods. This has important real-world applications in making computing tasks more accessible and efficient through natural language interactions.
While the paper acknowledges some limitations and areas for future research, this work represents an important step forward in developing more capable and versatile AI-powered virtual assistants. As these technologies continue to advance, they have the potential to transform how humans interact with and control computerized systems in their daily lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Visual grounding for desktop graphical user interfaces
Tassnim Dardouri, Laura Minkova, Jessica L'opez Espejel, Walid Dahhane, El Hassane Ettifouri
Most instance perception and image understanding solutions focus mainly on natural images. However, applications for synthetic images, and more specifically, images of Graphical User Interfaces (GUI) remain limited. This hinders the development of autonomous computer-vision-powered Artificial Intelligence (AI) agents. In this work, we present Instruction Visual Grounding or IVG, a multi-modal solution for object identification in a GUI. More precisely, given a natural language instruction and GUI screen, IVG locates the coordinates of the element on the screen where the instruction would be executed. To this end, we develop two methods. The first method is a three-part architecture that relies on a combination of a Large Language Model (LLM) and an object detection model. The second approach uses a multi-modal foundation model.
Read more9/18/2024

0
VGA: Vision GUI Assistant -- Minimizing Hallucinations through Image-Centric Fine-Tuning
Ziyang Meng, Yu Dai, Zezheng Gong, Shaoxiong Guo, Minglong Tang, Tongquan Wei
Recent advances in Large Vision-Language Models (LVLMs) have significantly improve performance in image comprehension tasks, such as formatted charts and rich-content images. Yet, Graphical User Interface (GUI) pose a greater challenge due to their structured format and detailed textual information. Existing LVLMs often overly depend on internal knowledge and neglect image content, resulting in hallucinations and incorrect responses in GUI comprehension. To address these issues, we introduce VGA, a fine-tuned model designed for comprehensive GUI understanding. Our model aims to enhance the interpretation of visual data of GUI and reduce hallucinations. We first construct a Vision Question Answering (VQA) dataset of 63.8k high-quality examples with our propose Referent Method, which ensures the model's responses are highly depend on visual content within the image. We then design a two-stage fine-tuning method called Foundation and Advanced Comprehension (FAC) to enhance both the model's ability to extract information from image content and alignment with human intent. Experiments show that our approach enhances the model's ability to extract information from images and achieves state-of-the-art results in GUI understanding tasks. Our dataset and fine-tuning script will be released soon.
Read more6/24/2024
🤔
0
Beyond Literal Descriptions: Understanding and Locating Open-World Objects Aligned with Human Intentions
Wenxuan Wang, Yisi Zhang, Xingjian He, Yichen Yan, Zijia Zhao, Xinlong Wang, Jing Liu
Visual grounding (VG) aims at locating the foreground entities that match the given natural language expressions. Previous datasets and methods for classic VG task mainly rely on the prior assumption that the given expression must literally refer to the target object, which greatly impedes the practical deployment of agents in real-world scenarios. Since users usually prefer to provide intention-based expression for the desired object instead of covering all the details, it is necessary for the agents to interpret the intention-driven instructions. Thus, in this work, we take a step further to the intention-driven visual-language (V-L) understanding. To promote classic VG towards human intention interpretation, we propose a new intention-driven visual grounding (IVG) task and build a large-scale IVG dataset termed IntentionVG with free-form intention expressions. Considering that practical agents need to move and find specific targets among various scenarios to realize the grounding task, our IVG task and IntentionVG dataset have taken the crucial properties of both multi-scenario perception and egocentric view into consideration. Besides, various types of models are set up as the baselines to realize our IVG task. Extensive experiments on our IntentionVG dataset and baselines demonstrate the necessity and efficacy of our method for the V-L field. To foster future research in this direction, our newly built dataset and baselines will be publicly available at https://github.com/Rubics-Xuan/IVG.
Read more5/27/2024
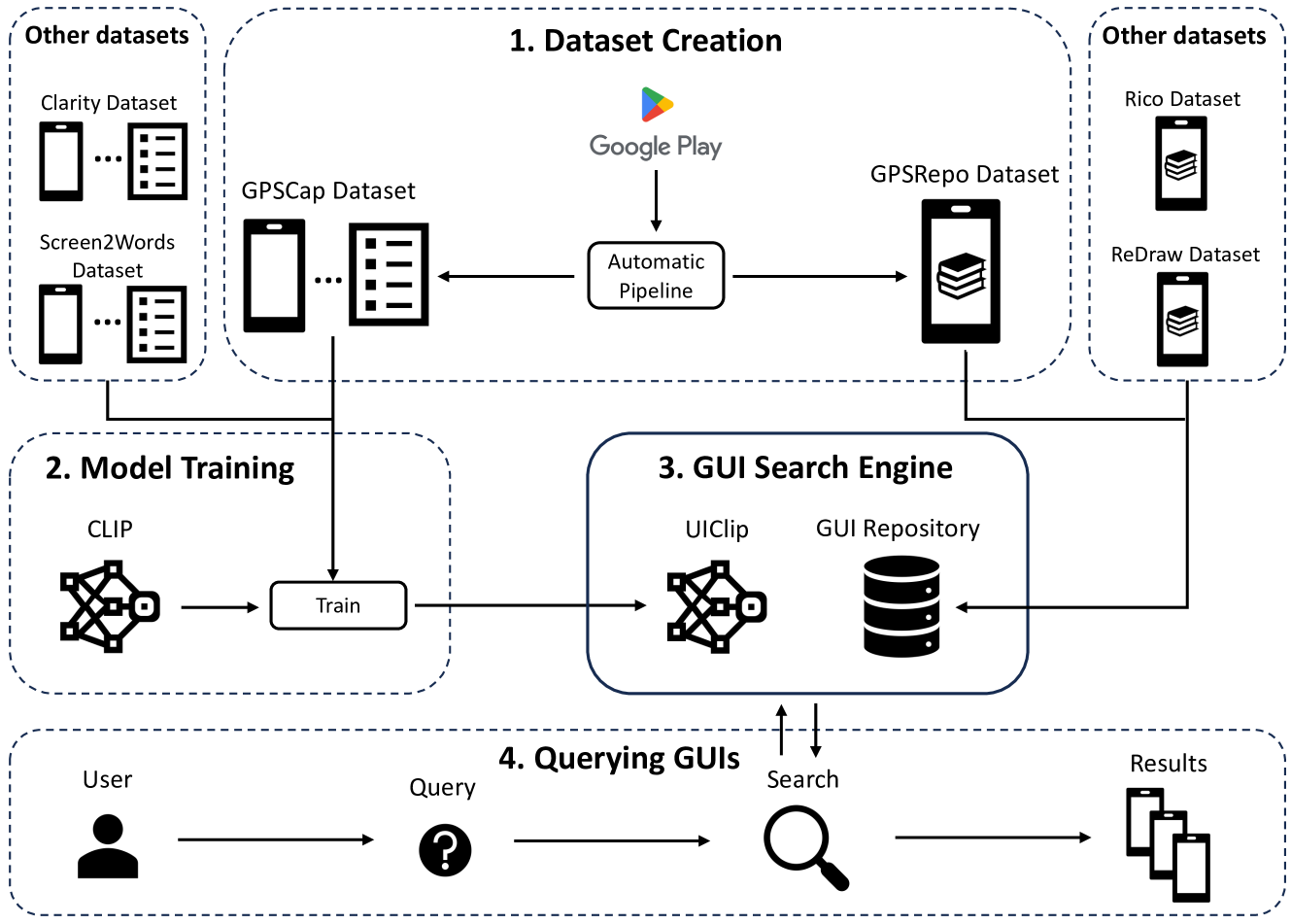
0
GUing: A Mobile GUI Search Engine using a Vision-Language Model
Jialiang Wei, Anne-Lise Courbis, Thomas Lambolais, Binbin Xu, Pierre Louis Bernard, G'erard Dray, Walid Maalej
App developers use the Graphical User Interface (GUI) of other apps as a source of inspiration for designing and improving their own apps. Recent research has thus suggested retrieving relevant GUI designs that match a certain text query from screenshot datasets acquired through crowdsourced or automated exploration of GUIs. However, such text-to-GUI retrieval approaches only leverage the textual information of the GUI elements, neglecting visual information such as icons or background images. In addition, retrieved screenshots are not steered by app developers and often lack important app features that require particular input data. To overcome these limitations, this paper proposes GUing, a GUI search engine based on a vision-language model called GUIClip, which we trained specifically for the problem of designing app GUIs. For this, we first collected from Google Play app introduction images which usually display the most representative screenshots and are often captioned (i.e.~labeled) by app vendors. Then, we developed an automated pipeline to classify, crop, and extract the captions from these images. This resulted in a large dataset which we share with this paper: including 303k app screenshots, out of which 135k have captions. We used this dataset to train a novel vision-language model, which is, to the best of our knowledge, the first of its kind in GUI retrieval. We evaluated our approach on various datasets from related work and in manual experiment. The results demonstrate that our model outperforms previous approaches in text-to-GUI retrieval achieving a Recall@10 of up to 0.69 and a HIT@10 of 0.91. We also explored the performance of GUIClip for other GUI tasks including GUI classification and sketch-to-GUI retrieval with encouraging results.
Read more9/4/2024