vitaLITy 2: Reviewing Academic Literature Using Large Language Models

0
Sign in to get full access
Overview
- Summarizes the key points of a research paper on using large language models (LLMs) to review academic literature
- Provides a plain English explanation, technical details, and critical analysis of the research
Plain English Explanation
This paper explores the use of large language models to help researchers review and summarize academic literature more efficiently. The researchers developed a system called "vitaLITy 2" that can read through papers, extract key information, and provide summaries.
The core idea is that LLMs, which are trained on massive amounts of text data, can understand the content and context of research papers better than traditional approaches. This allows the system to identify important points, synthesize insights, and generate concise summaries that capture the essence of the literature.
By automating these literature review tasks, the researchers aim to help researchers save time and effort, allowing them to focus more on higher-level analysis and drawing meaningful conclusions from the research. This could be particularly useful in fields with rapidly growing bodies of literature, where manually keeping up with the latest publications becomes increasingly challenging.
Technical Explanation
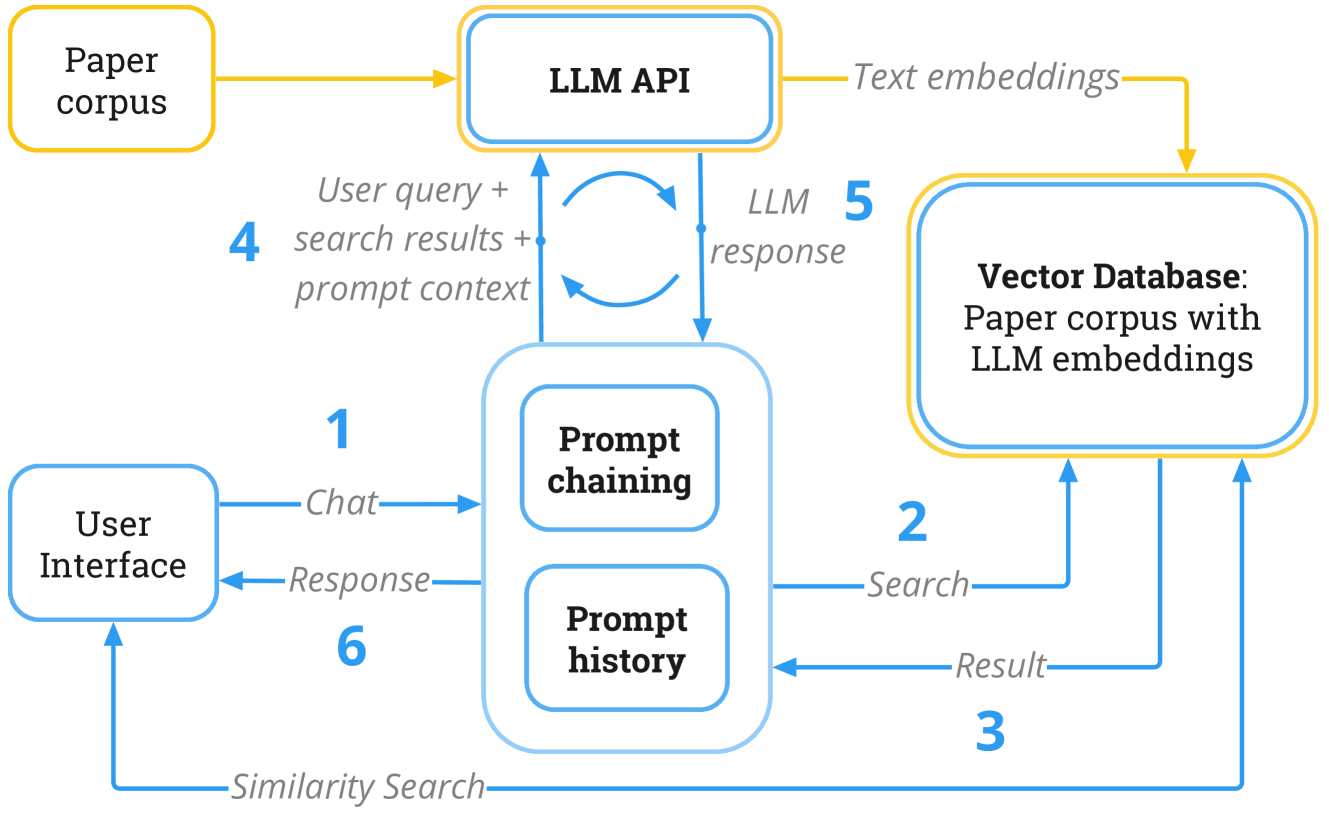
The vitaLITy 2 system uses a multi-step process to review academic papers. First, it ingests the full text of the papers and uses LLMs to extract key information, such as the research question, methodology, findings, and conclusions.
The system then synthesizes this information into a concise summary, highlighting the most important aspects of the paper. To enhance the quality and coherence of the summaries, the researchers incorporated techniques like context-enhanced language models and structured science summarization.
The paper also describes experiments conducted to evaluate the performance of the vitaLITy 2 system. The researchers compared the system's summaries to human-written ones, as well as to summaries generated by other automated approaches. The results suggest that the vitaLITy 2 system can produce high-quality, informative summaries that closely match the level of detail and understanding provided by human experts.
Critical Analysis
The paper acknowledges several limitations and areas for further research. For example, the system's performance may be influenced by the quality and diversity of the training data used to fine-tune the LLMs. Additionally, the researchers note that the system's ability to understand and summarize specialized or technical content may be constrained by the inherent limitations of current language models.
Another potential issue is the potential for bias in the summaries generated by the system. As with any AI-based system, there is a risk that the vitaLITy 2 system may inadvertently amplify or introduce biases present in the training data or the LLMs themselves. This could lead to skewed or incomplete representations of the research literature.
Further research is needed to address these challenges and explore ways to improve the robustness and reliability of the vitaLITy 2 system. Potential areas for future work include developing methods to assess and mitigate bias, as well as exploring ways to enhance the system's understanding of complex scientific concepts and reasoning.
Conclusion
Overall, this paper presents a promising approach to leveraging large language models to streamline the process of reviewing academic literature. By automating the extraction and synthesis of key information from research papers, the vitaLITy 2 system has the potential to significantly improve the efficiency and productivity of literature review tasks.
As the volume of academic research continues to grow, tools like vitaLITy 2 may become increasingly valuable for researchers and scholars seeking to stay informed and up-to-date with the latest developments in their fields. However, the limitations and potential biases inherent in the system will need to be carefully addressed to ensure the reliability and trustworthiness of the generated summaries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
vitaLITy 2: Reviewing Academic Literature Using Large Language Models
Hongye An, Arpit Narechania, Emily Wall, Kai Xu
Academic literature reviews have traditionally relied on techniques such as keyword searches and accumulation of relevant back-references, using databases like Google Scholar or IEEEXplore. However, both the precision and accuracy of these search techniques is limited by the presence or absence of specific keywords, making literature review akin to searching for needles in a haystack. We present vitaLITy 2, a solution that uses a Large Language Model or LLM-based approach to identify semantically relevant literature in a textual embedding space. We include a corpus of 66,692 papers from 1970-2023 which are searchable through text embeddings created by three language models. vitaLITy 2 contributes a novel Retrieval Augmented Generation (RAG) architecture and can be interacted with through an LLM with augmented prompts, including summarization of a collection of papers. vitaLITy 2 also provides a chat interface that allow users to perform complex queries without learning any new programming language. This also enables users to take advantage of the knowledge captured in the LLM from its enormous training corpus. Finally, we demonstrate the applicability of vitaLITy 2 through two usage scenarios. vitaLITy 2 is available as open-source software at https://vitality-vis.github.io.
Read more8/27/2024
💬
0
The emergence of Large Language Models (LLM) as a tool in literature reviews: an LLM automated systematic review
Dmitry Scherbakov, Nina Hubig, Vinita Jansari, Alexander Bakumenko, Leslie A. Lenert
Objective: This study aims to summarize the usage of Large Language Models (LLMs) in the process of creating a scientific review. We look at the range of stages in a review that can be automated and assess the current state-of-the-art research projects in the field. Materials and Methods: The search was conducted in June 2024 in PubMed, Scopus, Dimensions, and Google Scholar databases by human reviewers. Screening and extraction process took place in Covidence with the help of LLM add-on which uses OpenAI gpt-4o model. ChatGPT was used to clean extracted data and generate code for figures in this manuscript, ChatGPT and Scite.ai were used in drafting all components of the manuscript, except the methods and discussion sections. Results: 3,788 articles were retrieved, and 172 studies were deemed eligible for the final review. ChatGPT and GPT-based LLM emerged as the most dominant architecture for review automation (n=126, 73.2%). A significant number of review automation projects were found, but only a limited number of papers (n=26, 15.1%) were actual reviews that used LLM during their creation. Most citations focused on automation of a particular stage of review, such as Searching for publications (n=60, 34.9%), and Data extraction (n=54, 31.4%). When comparing pooled performance of GPT-based and BERT-based models, the former were better in data extraction with mean precision 83.0% (SD=10.4), and recall 86.0% (SD=9.8), while being slightly less accurate in title and abstract screening stage (Maccuracy=77.3%, SD=13.0). Discussion/Conclusion: Our LLM-assisted systematic review revealed a significant number of research projects related to review automation using LLMs. The results looked promising, and we anticipate that LLMs will change in the near future the way the scientific reviews are conducted.
Read more9/10/2024

0
Automated Review Generation Method Based on Large Language Models
Shican Wu, Xiao Ma, Dehui Luo, Lulu Li, Xiangcheng Shi, Xin Chang, Xiaoyun Lin, Ran Luo, Chunlei Pei, Zhi-Jian Zhao, Jinlong Gong
Literature research, vital for scientific advancement, is overwhelmed by the vast ocean of available information. Addressing this, we propose an automated review generation method based on Large Language Models (LLMs) to streamline literature processing and reduce cognitive load. In case study on propane dehydrogenation (PDH) catalysts, our method swiftly generated comprehensive reviews from 343 articles, averaging seconds per article per LLM account. Extended analysis of 1041 articles provided deep insights into catalysts' composition, structure, and performance. Recognizing LLMs' hallucinations, we employed a multi-layered quality control strategy, ensuring our method's reliability and effective hallucination mitigation. Expert verification confirms the accuracy and citation integrity of generated reviews, demonstrating LLM hallucination risks reduced to below 0.5% with over 95% confidence. Released Windows application enables one-click review generation, aiding researchers in tracking advancements and recommending literature. This approach showcases LLMs' role in enhancing scientific research productivity and sets the stage for further exploration.
Read more7/31/2024

0
Cutting Through the Clutter: The Potential of LLMs for Efficient Filtration in Systematic Literature Reviews
Lucas Joos, Daniel A. Keim, Maximilian T. Fischer
In academic research, systematic literature reviews are foundational and highly relevant, yet tedious to create due to the high volume of publications and labor-intensive processes involved. Systematic selection of relevant papers through conventional means like keyword-based filtering techniques can sometimes be inadequate, plagued by semantic ambiguities and inconsistent terminology, which can lead to sub-optimal outcomes. To mitigate the required extensive manual filtering, we explore and evaluate the potential of using Large Language Models (LLMs) to enhance the efficiency, speed, and precision of literature review filtering, reducing the amount of manual screening required. By using models as classification agents acting on a structured database only, we prevent common problems inherent in LLMs, such as hallucinations. We evaluate the real-world performance of such a setup during the construction of a recent literature survey paper with initially more than 8.3k potentially relevant articles under consideration and compare this with human performance on the same dataset. Our findings indicate that employing advanced LLMs like GPT-4o, Claude 3.5 Sonnet, Gemini 1.5 Flash, or Llama3 with simple prompting can significantly reduce the time required for literature filtering - from usually weeks of manual research to only a few minutes. Simultaneously, we crucially show that false negatives can indeed be controlled through a consensus scheme, achieving recalls >98.8% at or even beyond the typical human error threshold, thereby also providing for more accurate and relevant articles selected. Our research not only demonstrates a substantial improvement in the methodology of literature reviews but also sets the stage for further integration and extensive future applications of responsible AI in academic research practices.
Read more7/16/2024