VoxAct-B: Voxel-Based Acting and Stabilizing Policy for Bimanual Manipulation

0

Sign in to get full access
Overview
- The paper presents VoxAct-B, a voxel-based acting and stabilizing policy for bimanual manipulation tasks.
- VoxAct-B uses a voxel-based representation of the environment to reason about and execute bimanual manipulation actions.
- The proposed approach aims to enable robots to perform complex bimanual tasks more robustly and efficiently.
Plain English Explanation
The paper introduces a new system called VoxAct-B that helps robots perform complex tasks using both of their hands (bimanual manipulation). The core idea is to use a "voxel-based" representation of the environment, which means dividing the space around the robot into a grid of small 3D cubes (voxels). This allows the robot to better understand the objects and obstacles in its surroundings and plan how to use both hands to manipulate things effectively.
The key advantage of this voxel-based approach is that it enables the robot to be more stable and precise when carrying out bimanual actions, like picking up and moving objects. Rather than just relying on sensor data from cameras, the robot can use the detailed voxel model to anticipate potential problems and adjust its movements accordingly. This makes the robot's bimanual manipulation more robust and efficient.
Overall, VoxAct-B aims to advance the capabilities of robots to fluidly use both hands to complete complex real-world tasks, which could have important applications in areas like manufacturing, home assistance, and beyond.
Technical Explanation
The paper introduces VoxAct-B, a novel voxel-based approach for bimanual manipulation tasks. The key innovation is the use of a voxel grid representation of the environment, which allows the robot to reason about the 3D spatial relationships between objects and plan stable bimanual actions.
The VoxAct-B system consists of two main components:
-
Voxel-Based Acting Policy: This module generates bimanual manipulation actions by analyzing the voxel grid representation of the environment. It considers factors like object positions, gripper configurations, and potential collisions to output stable, coordinated motions for both hands.
-
Voxel-Based Stabilizing Policy: This component continuously monitors the execution of the bimanual actions and adjusts the robot's movements in real-time to maintain stability and avoid errors. It uses the voxel grid to anticipate potential issues and make corrections as needed.
The authors evaluate VoxAct-B on a range of simulated bimanual manipulation tasks, including object grasping, transport, and assembly. The results show that the voxel-based approach outperforms prior state-of-the-art methods in terms of task completion rate, execution time, and robustness to uncertainties.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the VoxAct-B system, including comparisons to several baseline approaches. The voxel-based representation and associated acting and stabilizing policies appear to be effective at enabling more robust and efficient bimanual manipulation.
However, the authors acknowledge that the current system is limited to simulation and does not yet address the complexities of real-world environments, such as sensor noise, object deformations, and dynamic obstacles. Extending VoxAct-B to work reliably on physical robot platforms will likely require additional advancements in areas like perception, planning, and control.
Additionally, while the paper demonstrates improved performance on the specific tasks evaluated, it would be helpful to see an analysis of the system's generalization capabilities - i.e., how well it can adapt to novel task variations or object configurations beyond the training distribution.
Overall, VoxAct-B represents a promising step forward in developing more capable bimanual manipulation systems. Further research is needed to address the remaining challenges and broaden the applicability of the approach.
Conclusion
The VoxAct-B system proposed in this paper demonstrates a novel voxel-based approach to bimanual manipulation that enables robots to perform complex tasks more robustly and efficiently. By using a detailed 3D representation of the environment, the system can generate stable, coordinated motions for both hands and make real-time adjustments to maintain execution stability.
The evaluation results show significant improvements over prior state-of-the-art methods, suggesting that the voxel-based acting and stabilizing policies are an effective way to tackle the challenges of bimanual manipulation. While the current system is limited to simulation, the authors' work lays the groundwork for future advancements that could bring these capabilities to real-world robotic systems.
Overall, VoxAct-B represents an important contribution to the field of robotic manipulation, with the potential to unlock new applications for robots in manufacturing, healthcare, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VoxAct-B: Voxel-Based Acting and Stabilizing Policy for Bimanual Manipulation
I-Chun Arthur Liu, Sicheng He, Daniel Seita, Gaurav Sukhatme
Bimanual manipulation is critical to many robotics applications. In contrast to single-arm manipulation, bimanual manipulation tasks are challenging due to higher-dimensional action spaces. Prior works leverage large amounts of data and primitive actions to address this problem, but may suffer from sample inefficiency and limited generalization across various tasks. To this end, we propose VoxAct-B, a language-conditioned, voxel-based method that leverages Vision Language Models (VLMs) to prioritize key regions within the scene and reconstruct a voxel grid. We provide this voxel grid to our bimanual manipulation policy to learn acting and stabilizing actions. This approach enables more efficient policy learning from voxels and is generalizable to different tasks. In simulation, we show that VoxAct-B outperforms strong baselines on fine-grained bimanual manipulation tasks. Furthermore, we demonstrate VoxAct-B on real-world $texttt{Open Drawer}$ and $texttt{Open Jar}$ tasks using two UR5s. Code, data, and videos will be available at https://voxact-b.github.io.
Read more7/8/2024

0
PerAct2: A Perceiver Actor Framework for Bimanual Manipulation Tasks
Markus Grotz, Mohit Shridhar, Tamim Asfour, Dieter Fox
Bimanual manipulation is challenging due to precise spatial and temporal coordination required between two arms. While there exist several real-world bimanual systems, there is a lack of simulated benchmarks with a large task diversity for systematically studying bimanual capabilities across a wide range of tabletop tasks. This paper addresses the gap by extending RLBench to bimanual manipulation. We open-source our code and benchmark comprising 13 new tasks with 23 unique task variations, each requiring a high degree of coordination and adaptability. To kickstart the benchmark, we extended several state-of-the art methods to bimanual manipulation and also present a language-conditioned behavioral cloning agent -- PerAct2, which enables the learning and execution of bimanual 6-DoF manipulation tasks. Our novel network architecture efficiently integrates language processing with action prediction, allowing robots to understand and perform complex bimanual tasks in response to user-specified goals. Project website with code is available at: http://bimanual.github.io
Read more8/1/2024
0
Bi-VLA: Vision-Language-Action Model-Based System for Bimanual Robotic Dexterous Manipulations
Koffivi Fid`ele Gbagbe, Miguel Altamirano Cabrera, Ali Alabbas, Oussama Alyunes, Artem Lykov, Dzmitry Tsetserukou
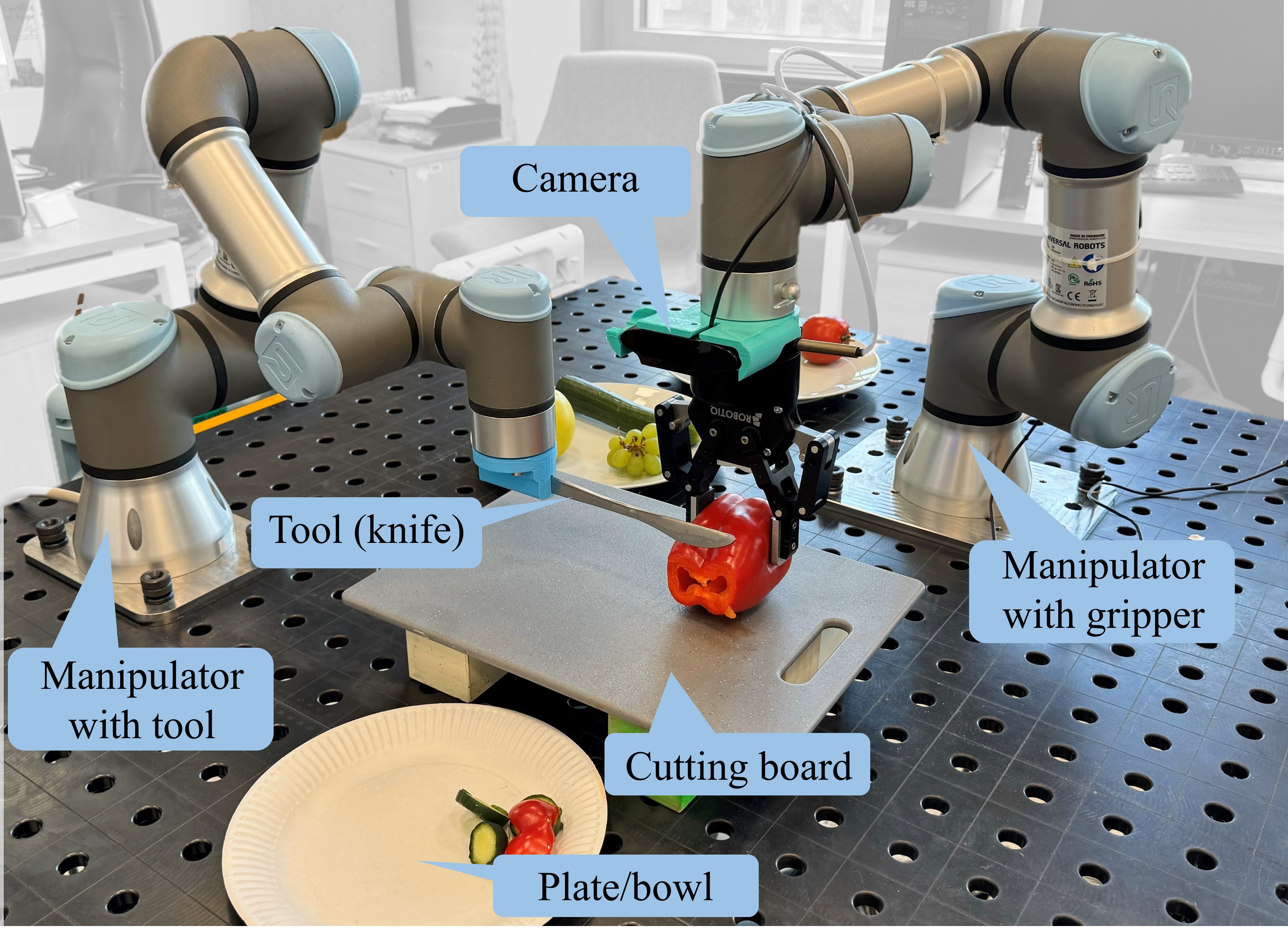
This research introduces the Bi-VLA (Vision-Language-Action) model, a novel system designed for bimanual robotic dexterous manipulation that seamlessly integrates vision for scene understanding, language comprehension for translating human instructions into executable code, and physical action generation. We evaluated the system's functionality through a series of household tasks, including the preparation of a desired salad upon human request. Bi-VLA demonstrates the ability to interpret complex human instructions, perceive and understand the visual context of ingredients, and execute precise bimanual actions to prepare the requested salad. We assessed the system's performance in terms of accuracy, efficiency, and adaptability to different salad recipes and human preferences through a series of experiments. Our results show a 100% success rate in generating the correct executable code by the Language Module, a 96.06% success rate in detecting specific ingredients by the Vision Module, and an overall success rate of 83.4% in correctly executing user-requested tasks.
Read more8/20/2024
0
Large Language Models for Orchestrating Bimanual Robots
Kun Chu, Xufeng Zhao, Cornelius Weber, Mengdi Li, Wenhao Lu, Stefan Wermter
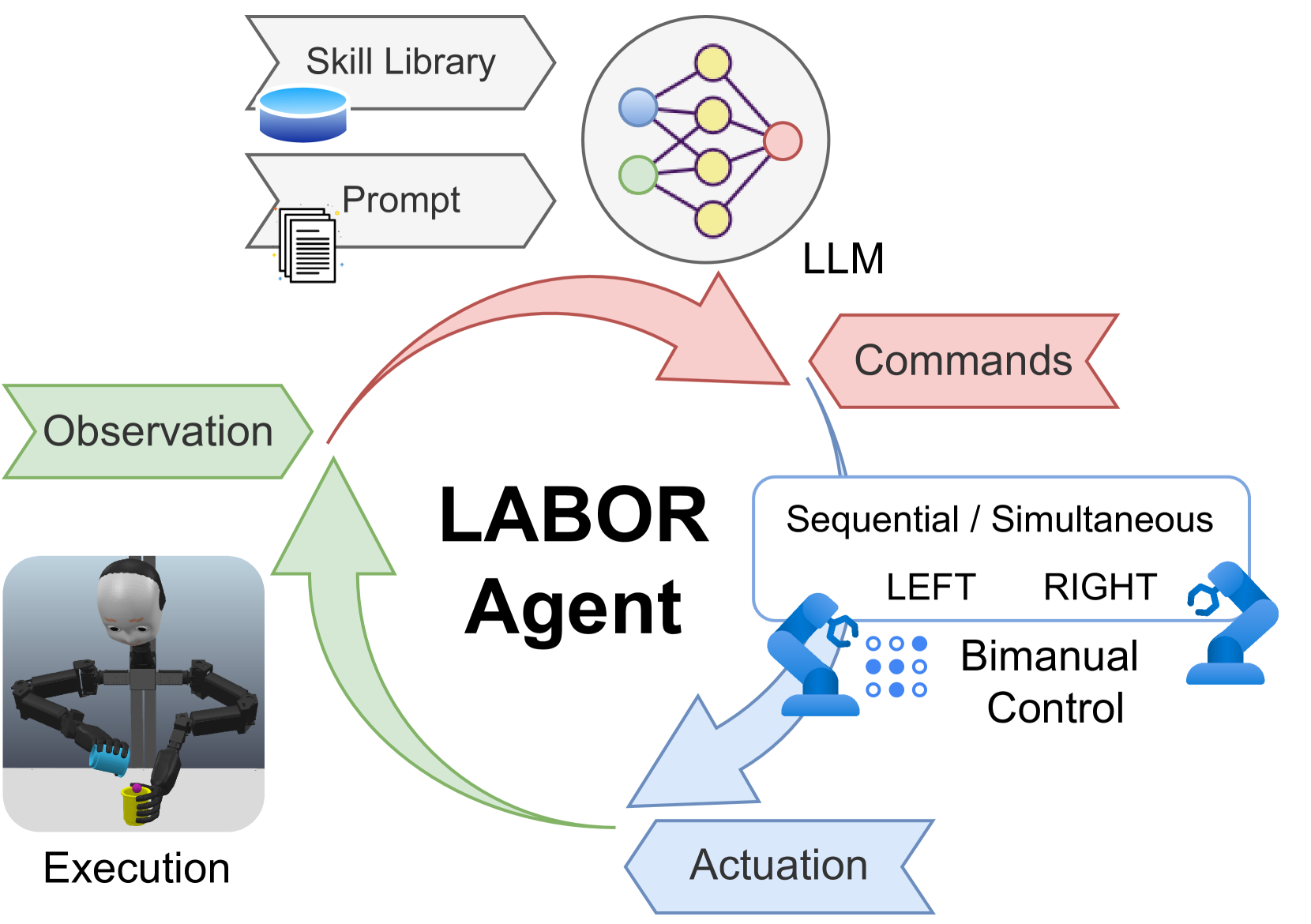
Although there has been rapid progress in endowing robots with the ability to solve complex manipulation tasks, generating control policies for bimanual robots to solve tasks involving two hands is still challenging because of the difficulties in effective temporal and spatial coordination. With emergent abilities in terms of step-by-step reasoning and in-context learning, Large Language Models (LLMs) have taken control of a variety of robotic tasks. However, the nature of language communication via a single sequence of discrete symbols makes LLM-based coordination in continuous space a particular challenge for bimanual tasks. To tackle this challenge for the first time by an LLM, we present LAnguage-model-based Bimanual ORchestration (LABOR), an agent utilizing an LLM to analyze task configurations and devise coordination control policies for addressing long-horizon bimanual tasks. In the simulated environment, the LABOR agent is evaluated through several everyday tasks on the NICOL humanoid robot. Reported success rates indicate that overall coordination efficiency is close to optimal performance, while the analysis of failure causes, classified into spatial and temporal coordination and skill selection, shows that these vary over tasks. The project website can be found at http://labor-agent.github.io
Read more4/3/2024