VS-Assistant: Versatile Surgery Assistant on the Demand of Surgeons

0
🚀
Sign in to get full access
Overview
- This research paper proposes a "Versatile Surgery Assistant" (VS-Assistant) that can accurately understand a surgeon's intentions and complete a variety of surgical tasks, such as scene analysis, instrument detection, and segmentation.
- The key innovation is the use of advanced multimodal large language models (MLLMs) to achieve superior surgical multimodal understanding, with a "Mixture of Projectors" (MOP) module to align the model's natural and surgical knowledge.
- The researchers also devise a "Surgical Function-Calling Tuning" strategy to enable the VS-Assistant to understand surgical intentions and execute the appropriate functions to support the surgeon's needs.
Plain English Explanation
The paper describes the development of an intelligent surgical assistant that can understand what the surgeon wants and then perform relevant tasks to help them. Current algorithms for surgical assistance are often limited to a single specific task and require manual combination of different functions, which can be cumbersome in practice.
The researchers have created a more versatile assistant by using advanced multimodal language models that can understand the surgeon's spoken or written instructions. This allows the assistant to accurately interpret the surgeon's intentions and then carry out the appropriate actions, such as analyzing the surgical scene, detecting surgical instruments, or performing segmentation tasks.
The key innovations are a "Mixture of Projectors" module that helps the language model balance its general knowledge with specialized surgical understanding, and a "Surgical Function-Calling Tuning" strategy that enables the assistant to directly execute the functions needed by the surgeon. Extensive testing on neurosurgery data showed the VS-Assistant outperforming existing multimodal language models in terms of understanding the surgeon's intentions and carrying out the required tasks.
Technical Explanation
The researchers propose a Versatile Surgery Assistant (VS-Assistant) that leverages advanced multimodal large language models (MLLMs) to accurately understand a surgeon's intentions and complete a series of surgical understanding tasks.
To achieve superior surgical multimodal understanding, the team devises a "Mixture of Projectors" (MOP) module. This aligns the surgical MLLM in the VS-Assistant, helping it balance its general natural language knowledge with more specialized surgical domain knowledge.
Furthermore, the researchers develop a "Surgical Function-Calling Tuning" strategy. This enables the VS-Assistant to directly understand the surgeon's intentions and make the appropriate function calls to carry out the required tasks, such as surgical scene analysis, instrument detection, and segmentation.
Extensive experiments on neurosurgery data demonstrate that the VS-Assistant can understand the surgeon's intentions more accurately than existing MLLM approaches. This results in strong performance across a range of textual analysis and visual understanding tasks.
Critical Analysis
The paper presents a compelling approach to developing a versatile surgical assistant using advanced multimodal language models. The key innovations around the MOP module and Surgical Function-Calling Tuning strategy appear well-designed to address the limitations of existing surgical assistance algorithms.
However, the paper does not provide much detail on the specific architectural choices or training procedures for the VS-Assistant. It would be helpful to understand how the researchers structured the MOP module and tuned the function-calling capabilities, as these are likely critical to the system's performance.
Additionally, while the experiments on neurosurgery data are promising, it would be valuable to see the VS-Assistant evaluated on a broader range of surgical specialties and real-world surgical environments. This would help assess the system's true versatility and robustness.
Finally, the paper does not discuss potential ethical considerations or limitations of the proposed approach. As an intelligent surgical assistant, it will be important to carefully consider issues around data privacy, algorithmic bias, and the potential risks of over-reliance on automated decision-making in high-stakes medical procedures.
Conclusion
This research presents an innovative "Versatile Surgery Assistant" that leverages advanced multimodal language models to provide surgeons with intelligent, context-aware support. By aligning the language model's general and surgical-specific knowledge, and enabling direct execution of surgical functions, the VS-Assistant demonstrates significant improvements in understanding surgeon intentions and completing relevant tasks.
While further research is needed to fully assess the system's capabilities and limitations, this work represents an important step towards developing more versatile and intelligent surgical assistants. If successfully deployed, such systems could enhance surgical workflow, reduce cognitive load on practitioners, and ultimately improve patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
VS-Assistant: Versatile Surgery Assistant on the Demand of Surgeons
Zhen Chen, Xingjian Luo, Jinlin Wu, Danny T. M. Chan, Zhen Lei, Jinqiao Wang, Sebastien Ourselin, Hongbin Liu
The surgical intervention is crucial to patient healthcare, and many studies have developed advanced algorithms to provide understanding and decision-making assistance for surgeons. Despite great progress, these algorithms are developed for a single specific task and scenario, and in practice require the manual combination of different functions, thus limiting the applicability. Thus, an intelligent and versatile surgical assistant is expected to accurately understand the surgeon's intentions and accordingly conduct the specific tasks to support the surgical process. In this work, by leveraging advanced multimodal large language models (MLLMs), we propose a Versatile Surgery Assistant (VS-Assistant) that can accurately understand the surgeon's intention and complete a series of surgical understanding tasks, e.g., surgical scene analysis, surgical instrument detection, and segmentation on demand. Specifically, to achieve superior surgical multimodal understanding, we devise a mixture of projectors (MOP) module to align the surgical MLLM in VS-Assistant to balance the natural and surgical knowledge. Moreover, we devise a surgical Function-Calling Tuning strategy to enable the VS-Assistant to understand surgical intentions, and thus make a series of surgical function calls on demand to meet the needs of the surgeons. Extensive experiments on neurosurgery data confirm that our VS-Assistant can understand the surgeon's intention more accurately than the existing MLLM, resulting in overwhelming performance in textual analysis and visual tasks. Source code and models will be made public.
Read more5/15/2024

0
LLaVA-Surg: Towards Multimodal Surgical Assistant via Structured Surgical Video Learning
Jiajie Li, Garrett Skinner, Gene Yang, Brian R Quaranto, Steven D Schwaitzberg, Peter C W Kim, Jinjun Xiong
Multimodal large language models (LLMs) have achieved notable success across various domains, while research in the medical field has largely focused on unimodal images. Meanwhile, current general-domain multimodal models for videos still lack the capabilities to understand and engage in conversations about surgical videos. One major contributing factor is the absence of datasets in the surgical field. In this paper, we create a new dataset, Surg-QA, consisting of 102,000 surgical video-instruction pairs, the largest of its kind so far. To build such a dataset, we propose a novel two-stage question-answer generation pipeline with LLM to learn surgical knowledge in a structured manner from the publicly available surgical lecture videos. The pipeline breaks down the generation process into two stages to significantly reduce the task complexity, allowing us to use a more affordable, locally deployed open-source LLM than the premium paid LLM services. It also mitigates the risk of LLM hallucinations during question-answer generation, thereby enhancing the overall quality of the generated data. We further train LLaVA-Surg, a novel vision-language conversational assistant capable of answering open-ended questions about surgical videos, on this Surg-QA dataset, and conduct comprehensive evaluations on zero-shot surgical video question-answering tasks. We show that LLaVA-Surg significantly outperforms all previous general-domain models, demonstrating exceptional multimodal conversational skills in answering open-ended questions about surgical videos. We will release our code, model, and the instruction-tuning dataset.
Read more8/16/2024

0
GP-VLS: A general-purpose vision language model for surgery
Samuel Schmidgall, Joseph Cho, Cyril Zakka, William Hiesinger
Surgery requires comprehensive medical knowledge, visual assessment skills, and procedural expertise. While recent surgical AI models have focused on solving task-specific problems, there is a need for general-purpose systems that can understand surgical scenes and interact through natural language. This paper introduces GP-VLS, a general-purpose vision language model for surgery that integrates medical and surgical knowledge with visual scene understanding. For comprehensively evaluating general-purpose surgical models, we propose SurgiQual, which evaluates across medical and surgical knowledge benchmarks as well as surgical vision-language questions. To train GP-VLS, we develop six new datasets spanning medical knowledge, surgical textbooks, and vision-language pairs for tasks like phase recognition and tool identification. We show that GP-VLS significantly outperforms existing open- and closed-source models on surgical vision-language tasks, with 8-21% improvements in accuracy across SurgiQual benchmarks. GP-VLS also demonstrates strong performance on medical and surgical knowledge tests compared to open-source alternatives. Overall, GP-VLS provides an open-source foundation for developing AI assistants to support surgeons across a wide range of tasks and scenarios. The code and data for this work is publicly available at gpvls-surgery-vlm.github.io.
Read more8/9/2024
0
Towards Intelligent Speech Assistants in Operating Rooms: A Multimodal Model for Surgical Workflow Analysis
Kubilay Can Demir, Belen Lojo Rodriguez, Tobias Weise, Andreas Maier, Seung Hee Yang
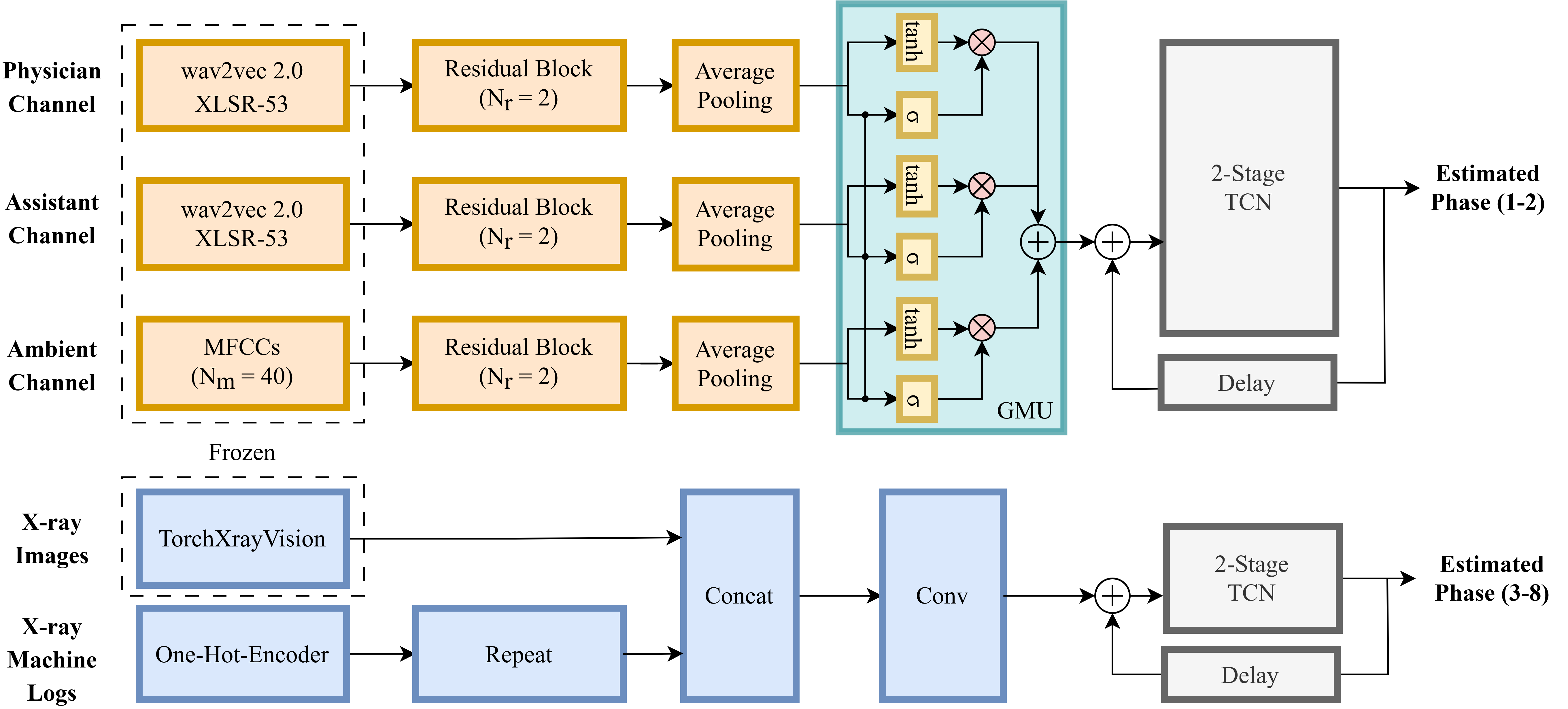
To develop intelligent speech assistants and integrate them seamlessly with intra-operative decision-support frameworks, accurate and efficient surgical phase recognition is a prerequisite. In this study, we propose a multimodal framework based on Gated Multimodal Units (GMU) and Multi-Stage Temporal Convolutional Networks (MS-TCN) to recognize surgical phases of port-catheter placement operations. Our method merges speech and image models and uses them separately in different surgical phases. Based on the evaluation of 28 operations, we report a frame-wise accuracy of 92.65 $pm$ 3.52% and an F1-score of 92.30 $pm$ 3.82%. Our results show approximately 10% improvement in both metrics over previous work and validate the effectiveness of integrating multimodal data for the surgical phase recognition task. We further investigate the contribution of individual data channels by comparing mono-modal models with multimodal models.
Read more6/24/2024