WaterMAS: Sharpness-Aware Maximization for Neural Network Watermarking

0
Sign in to get full access
Overview
- The paper introduces "WaterMAS", a sharpness-aware optimization technique for watermarking neural networks to protect intellectual property rights.
- WaterMAS aims to maximize the watermark's robustness while preserving the network's performance and visual quality.
- The authors demonstrate the effectiveness of WaterMAS on various network architectures and datasets, showing improvements over existing watermarking methods.
Plain English Explanation
Watermarking neural networks is a way to protect the intellectual property (IP) rights of the people who create these models. It involves embedding a hidden "watermark" into the model that can be detected later to prove ownership.
The paper introduces a new watermarking technique called WaterMAS that uses a "sharpness-aware" optimization approach. This means it tries to make the watermark as robust as possible while also preserving the model's performance and visual quality. The goal is to create a watermark that is hard to remove or detect, but doesn't negatively impact the model's usefulness.
The authors test WaterMAS on different neural network architectures and datasets, and show that it outperforms existing watermarking methods. This suggests it could be a valuable tool for protecting the IP of AI models developed by companies and researchers.
Technical Explanation
The key elements of the WaterMAS paper are:
-
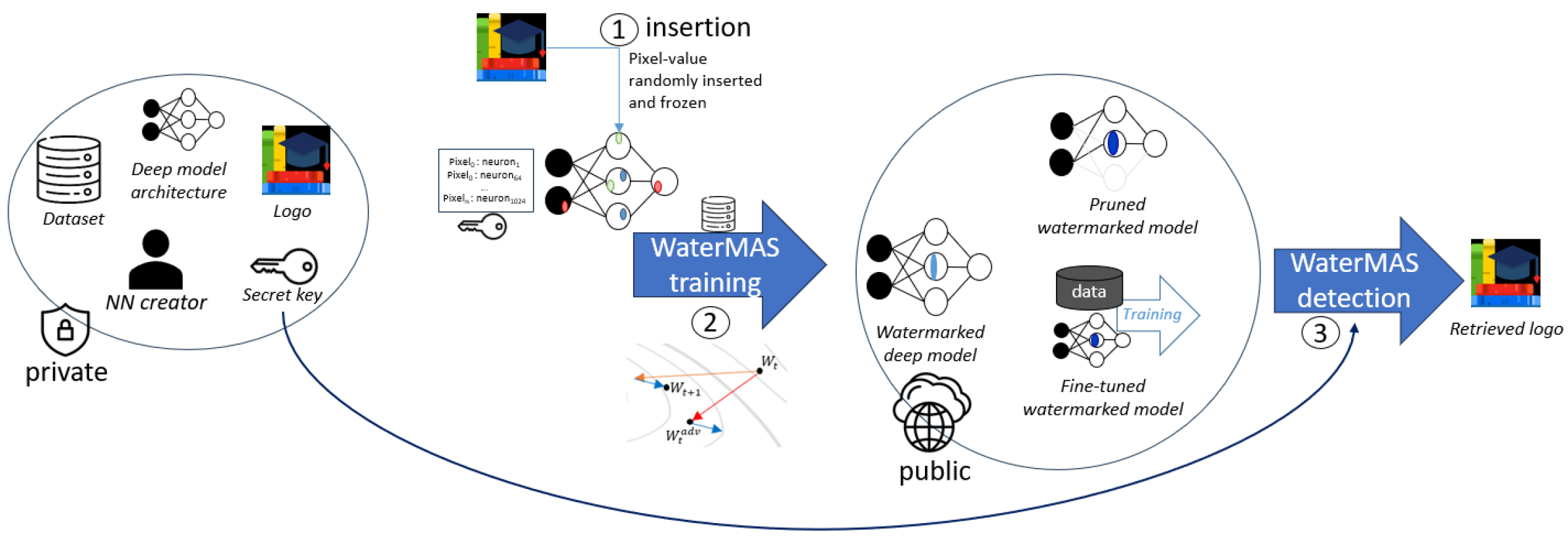
Watermarking Approach: WaterMAS embeds a watermark into the weights of a neural network model during the training process. The watermark is designed to be robust to potential attacks aimed at removing or detecting it.
-
Sharpness-Aware Optimization: WaterMAS uses a sharpness-aware training objective that simultaneously maximizes the watermark's robustness and preserves the model's performance and visual quality. This is in contrast to previous methods that often degraded the model's core functionality.
-
Experimental Evaluation: The authors evaluate WaterMAS on various network architectures (e.g., ResNet, BERT) and datasets (e.g., ImageNet, GLUE). They demonstrate that WaterMAS outperforms existing watermarking techniques in terms of watermark robustness, model accuracy, and visual quality.
-
Watermark Extraction: WaterMAS uses a two-stage watermark extraction process that first localizes the watermark and then extracts the embedded information. This approach is shown to be more effective than simpler extraction methods.
Critical Analysis
The WaterMAS paper presents a promising approach for watermarking neural networks, but there are a few potential limitations and areas for further research:
-
Attack Resistance: While the authors demonstrate the robustness of WaterMAS to certain attacks, there may be other types of attacks that could still remove or detect the watermark. Further research is needed to fully understand the security guarantees of this method.
-
Scalability: The paper focuses on relatively small-scale models and datasets. Applying WaterMAS to larger, more complex models may present additional challenges that need to be explored.
-
Interpretability: The paper does not delve into the interpretability of the embedded watermarks or provide insights into how they are represented within the model. Understanding the internal workings of the watermarking process could lead to improvements.
-
Real-World Deployment: The paper evaluates WaterMAS in a controlled, academic setting. Deploying this technique in real-world scenarios with practical constraints (e.g., computational resources, deployment timelines) may require further adaptations and considerations.
Conclusion
The WaterMAS paper presents a novel sharpness-aware optimization technique for watermarking neural networks, which demonstrates improved robustness, model performance, and visual quality compared to existing watermarking methods. This research contributes to the ongoing efforts to protect the intellectual property of AI models, which is an increasingly important issue as these technologies become more prevalent and valuable. While the paper highlights promising results, further research is needed to address potential limitations and ensure the practical viability of this approach in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
WaterMAS: Sharpness-Aware Maximization for Neural Network Watermarking
Carl De Sousa Trias, Mihai Mitrea, Attilio Fiandrotti, Marco Cagnazzo, Sumanta Chaudhuri, Enzo Tartaglione
Nowadays, deep neural networks are used for solving complex tasks in several critical applications and protecting both their integrity and intellectual property rights (IPR) has become of utmost importance. To this end, we advance WaterMAS, a substitutive, white-box neural network watermarking method that improves the trade-off among robustness, imperceptibility, and computational complexity, while making provisions for increased data payload and security. WasterMAS insertion keeps unchanged the watermarked weights while sharpening their underlying gradient space. The robustness is thus ensured by limiting the attack's strength: even small alterations of the watermarked weights would impact the model's performance. The imperceptibility is ensured by inserting the watermark during the training process. The relationship among the WaterMAS data payload, imperceptibility, and robustness properties is discussed. The secret key is represented by the positions of the weights conveying the watermark, randomly chosen through multiple layers of the model. The security is evaluated by investigating the case in which an attacker would intercept the key. The experimental validations consider 5 models and 2 tasks (VGG16, ResNet18, MobileNetV3, SwinT for CIFAR10 image classification, and DeepLabV3 for Cityscapes image segmentation) as well as 4 types of attacks (Gaussian noise addition, pruning, fine-tuning, and quantization). The code will be released open-source upon acceptance of the article.
Read more9/9/2024

0
New!FreeMark: A Non-Invasive White-Box Watermarking for Deep Neural Networks
Yuzhang Chen, Jiangnan Zhu, Yujie Gu, Minoru Kuribayashi, Kouichi Sakurai
Deep neural networks (DNNs) have achieved significant success in real-world applications. However, safeguarding their intellectual property (IP) remains extremely challenging. Existing DNN watermarking for IP protection often require modifying DNN models, which reduces model performance and limits their practicality. This paper introduces FreeMark, a novel DNN watermarking framework that leverages cryptographic principles without altering the original host DNN model, thereby avoiding any reduction in model performance. Unlike traditional DNN watermarking methods, FreeMark innovatively generates secret keys from a pre-generated watermark vector and the host model using gradient descent. These secret keys, used to extract watermark from the model's activation values, are securely stored with a trusted third party, enabling reliable watermark extraction from suspect models. Extensive experiments demonstrate that FreeMark effectively resists various watermark removal attacks while maintaining high watermark capacity.
Read more9/17/2024
🤖
0
WaterPool: A Watermark Mitigating Trade-offs among Imperceptibility, Efficacy and Robustness
Baizhou Huang, Xiaojun Wan
With the increasing use of large language models (LLMs) in daily life, concerns have emerged regarding their potential misuse and societal impact. Watermarking is proposed to trace the usage of specific models by injecting patterns into their generated texts. An ideal watermark should produce outputs that are nearly indistinguishable from those of the original LLM (imperceptibility), while ensuring a high detection rate (efficacy), even when the text is partially altered (robustness). Despite many methods having been proposed, none have simultaneously achieved all three properties, revealing an inherent trade-off. This paper utilizes a key-centered scheme to unify existing watermarking techniques by decomposing a watermark into two distinct modules: a key module and a mark module. Through this decomposition, we demonstrate for the first time that the key module significantly contributes to the trade-off issues observed in prior methods. Specifically, this reflects the conflict between the scale of the key sampling space during generation and the complexity of key restoration during detection. To this end, we introduce textbf{WaterPool}, a simple yet effective key module that preserves a complete key sampling space required by imperceptibility while utilizing semantics-based search to improve the key restoration process. WaterPool can integrate with most watermarks, acting as a plug-in. Our experiments with three well-known watermarking techniques show that WaterPool significantly enhances their performance, achieving near-optimal imperceptibility and markedly improving efficacy and robustness (+12.73% for KGW, +20.27% for EXP, +7.27% for ITS).
Read more5/24/2024

0
Fragile Model Watermark for integrity protection: leveraging boundary volatility and sensitive sample-pairing
ZhenZhe Gao, Zhenjun Tang, Zhaoxia Yin, Baoyuan Wu, Yue Lu
Neural networks have increasingly influenced people's lives. Ensuring the faithful deployment of neural networks as designed by their model owners is crucial, as they may be susceptible to various malicious or unintentional modifications, such as backdooring and poisoning attacks. Fragile model watermarks aim to prevent unexpected tampering that could lead DNN models to make incorrect decisions. They ensure the detection of any tampering with the model as sensitively as possible.However, prior watermarking methods suffered from inefficient sample generation and insufficient sensitivity, limiting their practical applicability. Our approach employs a sample-pairing technique, placing the model boundaries between pairs of samples, while simultaneously maximizing logits. This ensures that the model's decision results of sensitive samples change as much as possible and the Top-1 labels easily alter regardless of the direction it moves.
Read more6/14/2024