WaveCoder: Widespread And Versatile Enhancement For Code Large Language Models By Instruction Tuning
2312.14187
27
0
Abstract
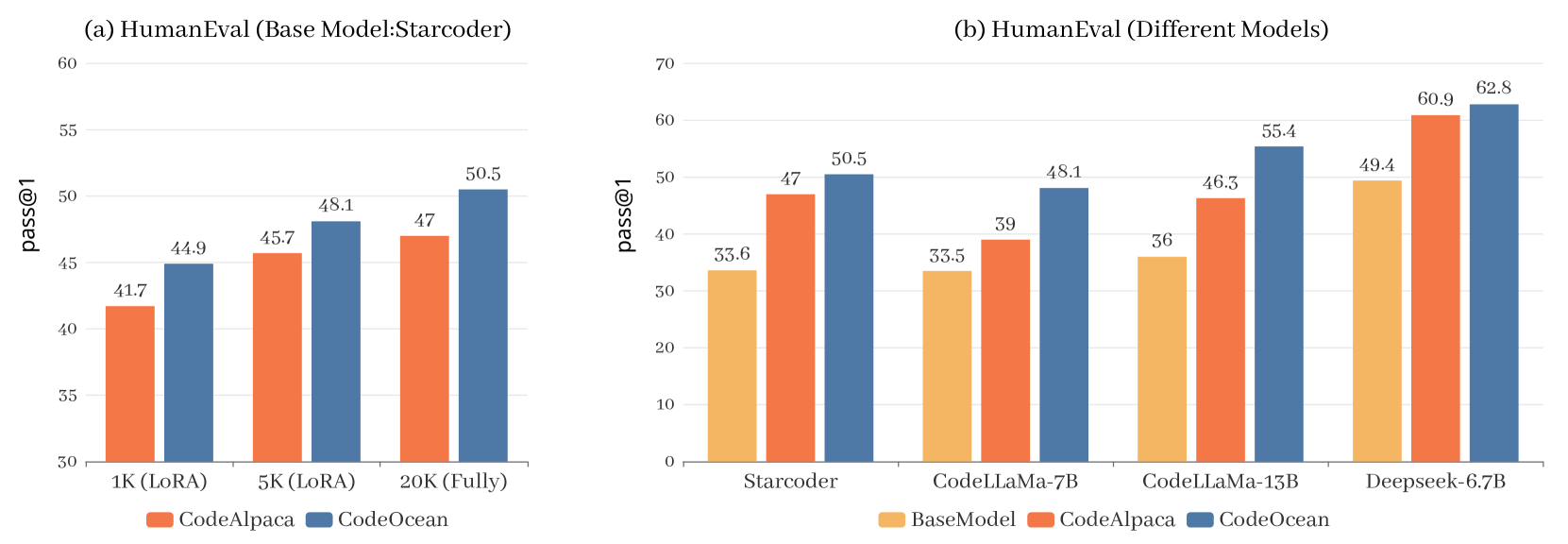
Recent work demonstrates that, after instruction tuning, Code Large Language Models (Code LLMs) can obtain impressive capabilities to address a wide range of code-related tasks. However, current instruction tuning methods for Code LLMs mainly focus on the traditional code generation task, resulting in poor performance in complex multi-task scenarios. In this paper, we concentrate on multiple code-related tasks and present WaveCoder, a series of Code LLMs trained with Widespread And Versatile Enhanced instruction data. To enable the models to tackle complex code-related tasks, we propose a method to stably generate diverse, high-quality instruction data from open source code dataset in multi-task scenarios and obtain CodeSeaXDataset, a dataset comprising 19,915 instruction instances across 4 code-related tasks, which is aimed at improving the generalization ability of Code LLM. Our experiments demonstrate that WaveCoder models significantly outperform other open-source models in terms of the generalization ability across different code-related tasks. Moreover, WaveCoder-Ultra-6.7B presents the state-of-the-art generalization abilities on a wide range of code-related tasks.
Create account to get full access
Overview
- The paper presents a novel approach called "WaveCoder" for enhancing language model training on code-related instruction data.
- The approach involves generating refined and versatile synthetic code-related instruction data to improve the performance of large language models on a variety of code-related tasks.
- The authors introduce a new dataset called "CodeOcean" that includes four diverse code-related instruction tasks, which they use to evaluate the effectiveness of WaveCoder.
Plain English Explanation
The researchers have developed a new technique called "WaveCoder" that aims to improve the way language models are trained on data related to coding and programming instructions. The key idea is to generate high-quality, diverse synthetic data that can supplement the training data for these language models, helping them become better at understanding and generating code-related instructions.
To test their approach, the researchers created a new dataset called "CodeOcean" that includes four different types of code-related tasks, such as [internal link: https://aimodels.fyi/papers/arxiv/alchemistcoder-harmonizing-eliciting-code-capability-by-hindsight] code completion, [internal link: https://aimodels.fyi/papers/arxiv/from-symbolic-tasks-to-code-generation-diversification] code generation, and [internal link: https://aimodels.fyi/papers/arxiv/codeclm-aligning-language-models-tailored-synthetic-data] code summarization. They then used WaveCoder to generate additional training data and evaluated how well the language models performed on the CodeOcean tasks.
Technical Explanation
The paper introduces a new method called "WaveCoder" that aims to improve the training of large language models on code-related instruction data. The key components of WaveCoder include:
-
Refined Data Generation: The authors develop techniques to generate high-quality, diverse synthetic code-related instruction data that can supplement the training data for language models. This includes [internal link: https://aimodels.fyi/papers/arxiv/genixer-empowering-multimodal-large-language-models-as] leveraging code structure and semantics to create more realistic and varied instruction samples.
-
Enhanced Instruction Tuning: The authors propose methods to fine-tune large language models on the generated synthetic data, as well as the original code-related instruction data, in a way that enhances the models' understanding and generation of code-related instructions.
To evaluate the effectiveness of WaveCoder, the authors introduce a new dataset called "CodeOcean" that includes four diverse code-related instruction tasks: [internal link: https://aimodels.fyi/papers/arxiv/transcoder-towards-unified-transferable-code-representation-learning] code completion, code generation, code summarization, and code classification. They show that language models trained using WaveCoder significantly outperform models trained on the original data alone across these tasks.
Critical Analysis
The paper presents a well-designed and thorough study, with a clear focus on improving the performance of language models on code-related tasks. The use of a newly created dataset, CodeOcean, to evaluate the effectiveness of WaveCoder is a particular strength, as it allows for a comprehensive assessment of the approach.
One potential limitation of the work is the reliance on synthetic data generation, which could introduce biases or artifacts that might not be present in real-world data. The authors acknowledge this and suggest that further research is needed to understand the implications of using synthetic data for language model training.
Additionally, the paper does not explore the potential downsides or unintended consequences of improving language models' capabilities in code-related tasks. While the authors highlight the practical benefits, it would be valuable to consider any ethical or societal implications that might arise from more powerful code-generation and understanding systems.
Conclusion
The WaveCoder approach presented in this paper represents a significant advancement in the field of language model training for code-related tasks. By generating refined and versatile synthetic data and using it to enhance the instruction tuning process, the researchers have demonstrated substantial improvements in language model performance across a range of code-related benchmarks.
This work has important implications for a variety of applications, from programming assistance tools to automated code generation systems. As the authors note, further research is needed to fully understand the potential limitations and societal impacts of these advancements. Nevertheless, the WaveCoder technique is an important step forward in the ongoing effort to develop more capable and reliable language models for the domain of software engineering and programming.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

AlchemistCoder: Harmonizing and Eliciting Code Capability by Hindsight Tuning on Multi-source Data
Zifan Song, Yudong Wang, Wenwei Zhang, Kuikun Liu, Chengqi Lyu, Demin Song, Qipeng Guo, Hang Yan, Dahua Lin, Kai Chen, Cairong Zhao
0
0
Open-source Large Language Models (LLMs) and their specialized variants, particularly Code LLMs, have recently delivered impressive performance. However, previous Code LLMs are typically fine-tuned on single-source data with limited quality and diversity, which may insufficiently elicit the potential of pre-trained Code LLMs. In this paper, we present AlchemistCoder, a series of Code LLMs with enhanced code generation and generalization capabilities fine-tuned on multi-source data. To achieve this, we pioneer to unveil inherent conflicts among the various styles and qualities in multi-source code corpora and introduce data-specific prompts with hindsight relabeling, termed AlchemistPrompts, to harmonize different data sources and instruction-response pairs. Additionally, we propose incorporating the data construction process into the fine-tuning data as code comprehension tasks, including instruction evolution, data filtering, and code review. Extensive experiments demonstrate that AlchemistCoder holds a clear lead among all models of the same size (6.7B/7B) and rivals or even surpasses larger models (15B/33B/70B), showcasing the efficacy of our method in refining instruction-following capabilities and advancing the boundaries of code intelligence.
5/30/2024
From Symbolic Tasks to Code Generation: Diversification Yields Better Task Performers
Dylan Zhang, Justin Wang, Francois Charton
0
0
Instruction tuning -- tuning large language models on instruction-output pairs -- is a promising technique for making models better adapted to the real world. Yet, the key factors driving the model's capability to understand and follow instructions not seen during training remain under-explored. Our investigation begins with a series of synthetic experiments within the theoretical framework of a Turing-complete algorithm called Markov algorithm, which allows fine-grained control over the instruction-tuning data. Generalization and robustness with respect to the training distribution emerge once a diverse enough set of tasks is provided, even though very few examples are provided for each task. We extend these initial results to a real-world application scenario of code generation and find that a more diverse instruction set, extending beyond code-related tasks, improves the performance of code generation. Our observations suggest that a more diverse semantic space for instruction-tuning sets greatly improves the model's ability to follow instructions and perform tasks.
6/3/2024
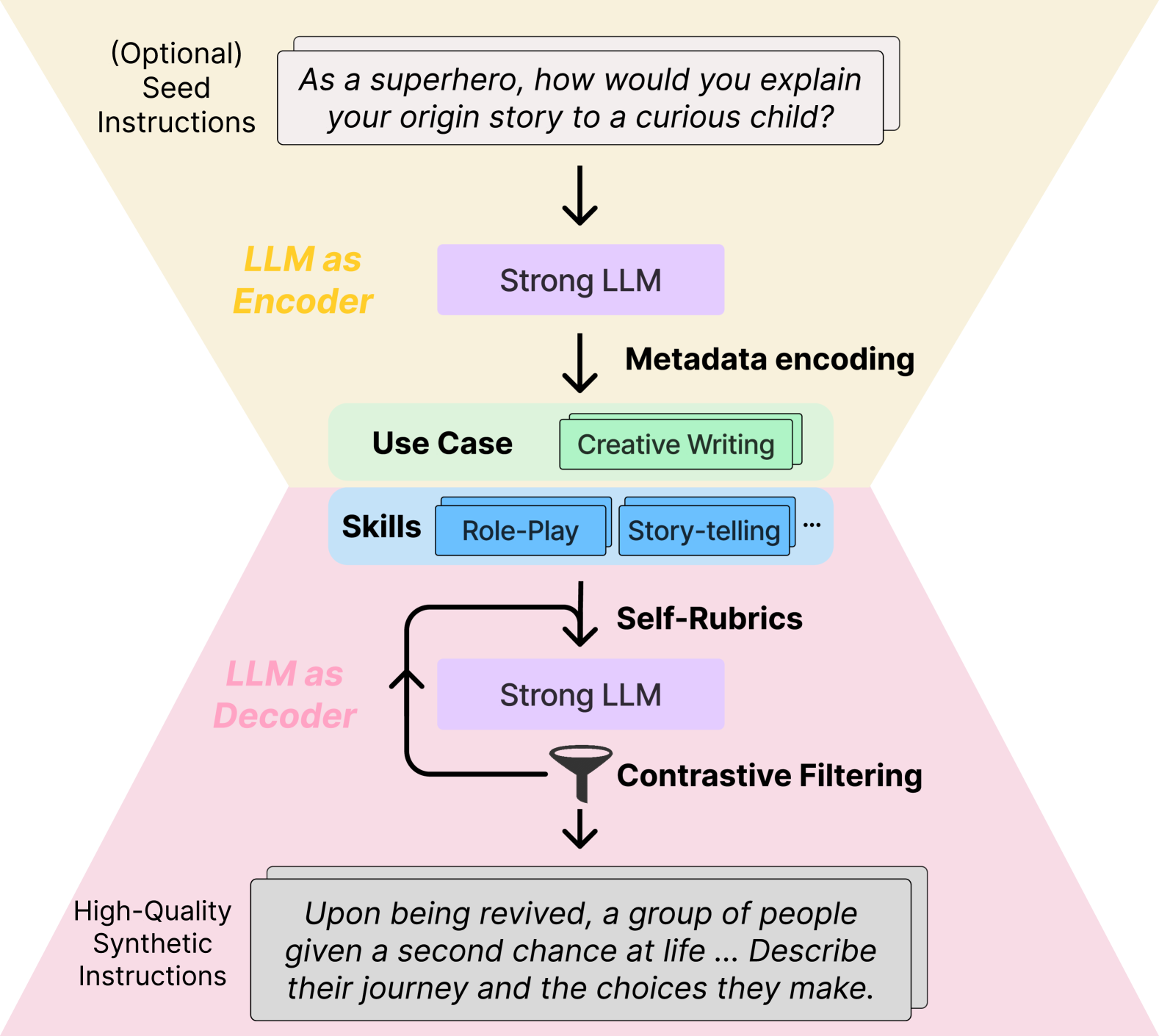
CodecLM: Aligning Language Models with Tailored Synthetic Data
Zifeng Wang, Chun-Liang Li, Vincent Perot, Long T. Le, Jin Miao, Zizhao Zhang, Chen-Yu Lee, Tomas Pfister
0
0
Instruction tuning has emerged as the key in aligning large language models (LLMs) with specific task instructions, thereby mitigating the discrepancy between the next-token prediction objective and users' actual goals. To reduce the labor and time cost to collect or annotate data by humans, researchers start to explore the use of LLMs to generate instruction-aligned synthetic data. Recent works focus on generating diverse instructions and applying LLM to increase instruction complexity, often neglecting downstream use cases. It remains unclear how to tailor high-quality data to elicit better instruction-following abilities in different target instruction distributions and LLMs. To this end, we introduce CodecLM, a general framework for adaptively generating high-quality synthetic data for LLM alignment with different downstream instruction distributions and LLMs. Drawing on the Encode-Decode principles, we use LLMs as codecs to guide the data generation process. We first encode seed instructions into metadata, which are concise keywords generated on-the-fly to capture the target instruction distribution, and then decode metadata to create tailored instructions. We also introduce Self-Rubrics and Contrastive Filtering during decoding to tailor data-efficient samples. Extensive experiments on four open-domain instruction following benchmarks validate the effectiveness of CodecLM over the current state-of-the-arts.
4/10/2024

Genixer: Empowering Multimodal Large Language Models as a Powerful Data Generator
Henry Hengyuan Zhao, Pan Zhou, Mike Zheng Shou
0
0
Multimodal Large Language Models (MLLMs) demonstrate exceptional problem-solving capabilities, but there is limited research focusing on their ability to generate data by converting unlabeled images into visual instruction tuning data. To this end, this paper is the first to explore the potential of empowering MLLM to generate data rather than prompting GPT-4. We introduce Genixer, a holistic data generation pipeline consisting of four key steps: (i) instruction data collection, (ii) instruction template design, (iii) empowering MLLMs, and (iv) data generation and filtering. Additionally, we outline two modes of data generation: task-agnostic and task-specific, enabling controllable output. We demonstrate that a synthetic VQA-like dataset trained with LLaVA1.5 enhances performance on 10 out of 12 multimodal benchmarks. Additionally, the grounding MLLM Shikra, when trained with a REC-like synthetic dataset, shows improvements on 7 out of 8 REC datasets. Through experiments and synthetic data analysis, our findings are: (1) current MLLMs can serve as robust data generators without assistance from GPT-4V; (2) MLLMs trained with task-specific datasets can surpass GPT-4V in generating complex instruction tuning data; (3) synthetic datasets enhance performance across various multimodal benchmarks and help mitigate model hallucinations. The data, code, and models can be found at https://github.com/zhaohengyuan1/Genixer.
5/21/2024