AlchemistCoder: Harmonizing and Eliciting Code Capability by Hindsight Tuning on Multi-source Data

0

Sign in to get full access
Overview
- The paper proposes a novel approach called AlchemistCoder, which aims to harmonize and elicit the capabilities of code-generating language models by using hindsight tuning on multi-source data.
- The key idea is to fine-tune large language models on a diverse set of data sources, including both code and natural language, to create a more versatile and capable code generation system.
- The researchers leverage hindsight tuning, a novel training technique, to further refine the model's performance on a variety of code-related tasks.
Plain English Explanation
The researchers have developed a system called AlchemistCoder that can generate high-quality code. The core insight is that by training the system on a wide range of data sources, including both code and natural language, it can become more versatile and capable.
For example, CodeCLM and MapCoder have shown the benefits of training language models on code-specific data. AlchemistCoder takes this a step further by also incorporating natural language data, which can help the model better understand the context and intent behind the code it generates.
Additionally, the researchers use a novel training technique called "hindsight tuning" to further refine the model's performance on various code-related tasks. This involves fine-tuning the model on a diverse set of code-related benchmarks, allowing it to learn from its mistakes and continuously improve its capabilities.
The goal is to create a system that can generate code that is not only syntactically correct, but also aligns with the user's intent and requirements. This could be useful for a wide range of applications, such as CodeEditorBench or automated programming.
Technical Explanation
The researchers propose a novel approach called AlchemistCoder, which aims to harmonize and elicit the capabilities of code-generating language models by using hindsight tuning on multi-source data.
The core idea is to fine-tune large language models on a diverse set of data sources, including both code and natural language, to create a more versatile and capable code generation system. The researchers leverage the insights from previous work, such as CodeCLM and MapCoder, which have shown the benefits of training language models on code-specific data.
Additionally, the researchers use a novel training technique called "hindsight tuning" to further refine the model's performance on various code-related tasks. This involves fine-tuning the model on a diverse set of code-related benchmarks, such as CodeEditorBench, allowing it to learn from its mistakes and continuously improve its capabilities.
The goal is to create a system that can generate code that is not only syntactically correct, but also aligns with the user's intent and requirements. This could be useful for a wide range of applications, including automated programming and other code-related tasks.
Critical Analysis
The paper presents a promising approach to enhancing the capabilities of code-generating language models. The use of hindsight tuning on multi-source data is a novel and potentially effective way to improve the model's versatility and performance on a wide range of code-related tasks.
However, the paper does not provide detailed information on the specific benchmarks and evaluation metrics used, nor does it address potential limitations or challenges that may arise in real-world deployment scenarios. It would be valuable to see more thorough analysis of the model's performance on a diverse set of code-related tasks and a discussion of any caveats or areas for further research.
Additionally, the paper does not compare the proposed approach to other state-of-the-art methods in the field, which could help contextualize the contributions and insights of this work. Providing a more comprehensive comparison to related techniques, such as CodeEditorBench or performance-aligned LLMs, would strengthen the paper's positioning and the significance of the proposed approach.
Conclusion
The AlchemistCoder system presented in this paper represents a promising step forward in the development of more capable and versatile code-generating language models. By leveraging hindsight tuning on a diverse set of data sources, including both code and natural language, the researchers have demonstrated a novel approach to harmonizing and eliciting the capabilities of these models.
The potential impact of this work could be far-reaching, as it could lead to significant advancements in areas such as automated programming, intelligent code editing, and the overall enhancement of human-AI collaboration in software development. However, further research and thorough evaluation are needed to fully understand the strengths, limitations, and real-world applicability of the AlchemistCoder approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AlchemistCoder: Harmonizing and Eliciting Code Capability by Hindsight Tuning on Multi-source Data
Zifan Song, Yudong Wang, Wenwei Zhang, Kuikun Liu, Chengqi Lyu, Demin Song, Qipeng Guo, Hang Yan, Dahua Lin, Kai Chen, Cairong Zhao
Open-source Large Language Models (LLMs) and their specialized variants, particularly Code LLMs, have recently delivered impressive performance. However, previous Code LLMs are typically fine-tuned on single-source data with limited quality and diversity, which may insufficiently elicit the potential of pre-trained Code LLMs. In this paper, we present AlchemistCoder, a series of Code LLMs with enhanced code generation and generalization capabilities fine-tuned on multi-source data. To achieve this, we pioneer to unveil inherent conflicts among the various styles and qualities in multi-source code corpora and introduce data-specific prompts with hindsight relabeling, termed AlchemistPrompts, to harmonize different data sources and instruction-response pairs. Additionally, we propose incorporating the data construction process into the fine-tuning data as code comprehension tasks, including instruction evolution, data filtering, and code review. Extensive experiments demonstrate that AlchemistCoder holds a clear lead among all models of the same size (6.7B/7B) and rivals or even surpasses larger models (15B/33B/70B), showcasing the efficacy of our method in refining instruction-following capabilities and advancing the boundaries of code intelligence.
Read more5/30/2024
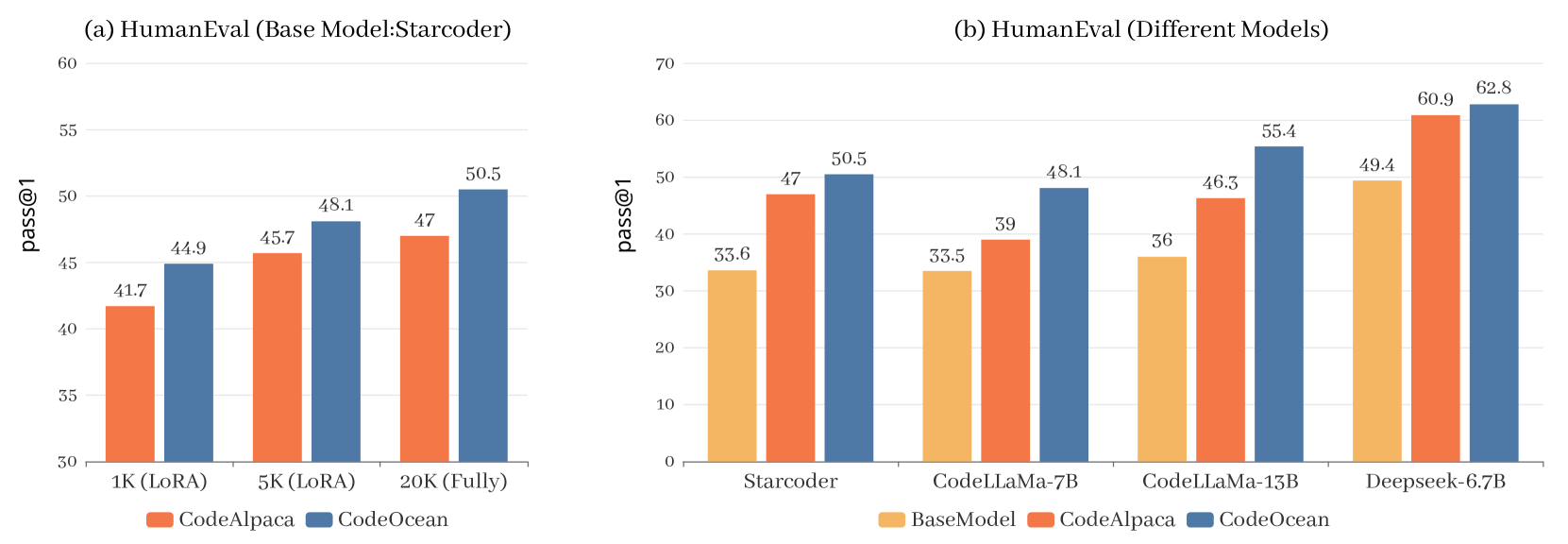
18
WaveCoder: Widespread And Versatile Enhancement For Code Large Language Models By Instruction Tuning
Zhaojian Yu, Xin Zhang, Ning Shang, Yangyu Huang, Can Xu, Yishujie Zhao, Wenxiang Hu, Qiufeng Yin
Recent work demonstrates that, after instruction tuning, Code Large Language Models (Code LLMs) can obtain impressive capabilities to address a wide range of code-related tasks. However, current instruction tuning methods for Code LLMs mainly focus on the traditional code generation task, resulting in poor performance in complex multi-task scenarios. In this paper, we concentrate on multiple code-related tasks and present WaveCoder, a series of Code LLMs trained with Widespread And Versatile Enhanced instruction data. To enable the models to tackle complex code-related tasks, we propose a method to stably generate diverse, high-quality instruction data from open source code dataset in multi-task scenarios and obtain CodeSeaXDataset, a dataset comprising 19,915 instruction instances across 4 code-related tasks, which is aimed at improving the generalization ability of Code LLM. Our experiments demonstrate that WaveCoder models significantly outperform other open-source models in terms of the generalization ability across different code-related tasks. Moreover, WaveCoder-Ultra-6.7B presents the state-of-the-art generalization abilities on a wide range of code-related tasks.
Read more6/10/2024

0
How Do Your Code LLMs Perform? Empowering Code Instruction Tuning with High-Quality Data
Yejie Wang, Keqing He, Dayuan Fu, Zhuoma Gongque, Heyang Xu, Yanxu Chen, Zhexu Wang, Yujia Fu, Guanting Dong, Muxi Diao, Jingang Wang, Mengdi Zhang, Xunliang Cai, Weiran Xu
Recently, there has been a growing interest in studying how to construct better code instruction tuning data. However, we observe Code models trained with these datasets exhibit high performance on HumanEval but perform worse on other benchmarks such as LiveCodeBench. Upon further investigation, we find that many datasets suffer from severe data leakage. After cleaning up most of the leaked data, some well-known high-quality datasets perform poorly. This discovery reveals a new challenge: identifying which dataset genuinely qualify as high-quality code instruction data. To address this, we propose an efficient code data pruning strategy for selecting good samples. Our approach is based on three dimensions: instruction complexity, response quality, and instruction diversity. Based on our selected data, we present XCoder, a family of models finetuned from LLaMA3. Our experiments show XCoder achieves new state-of-the-art performance using fewer training data, which verify the effectiveness of our data strategy. Moreover, we perform a comprehensive analysis on the data composition and find existing code datasets have different characteristics according to their construction methods, which provide new insights for future code LLMs. Our models and dataset are released in https://github.com/banksy23/XCoder
Read more9/9/2024
1
CodecLM: Aligning Language Models with Tailored Synthetic Data
Zifeng Wang, Chun-Liang Li, Vincent Perot, Long T. Le, Jin Miao, Zizhao Zhang, Chen-Yu Lee, Tomas Pfister
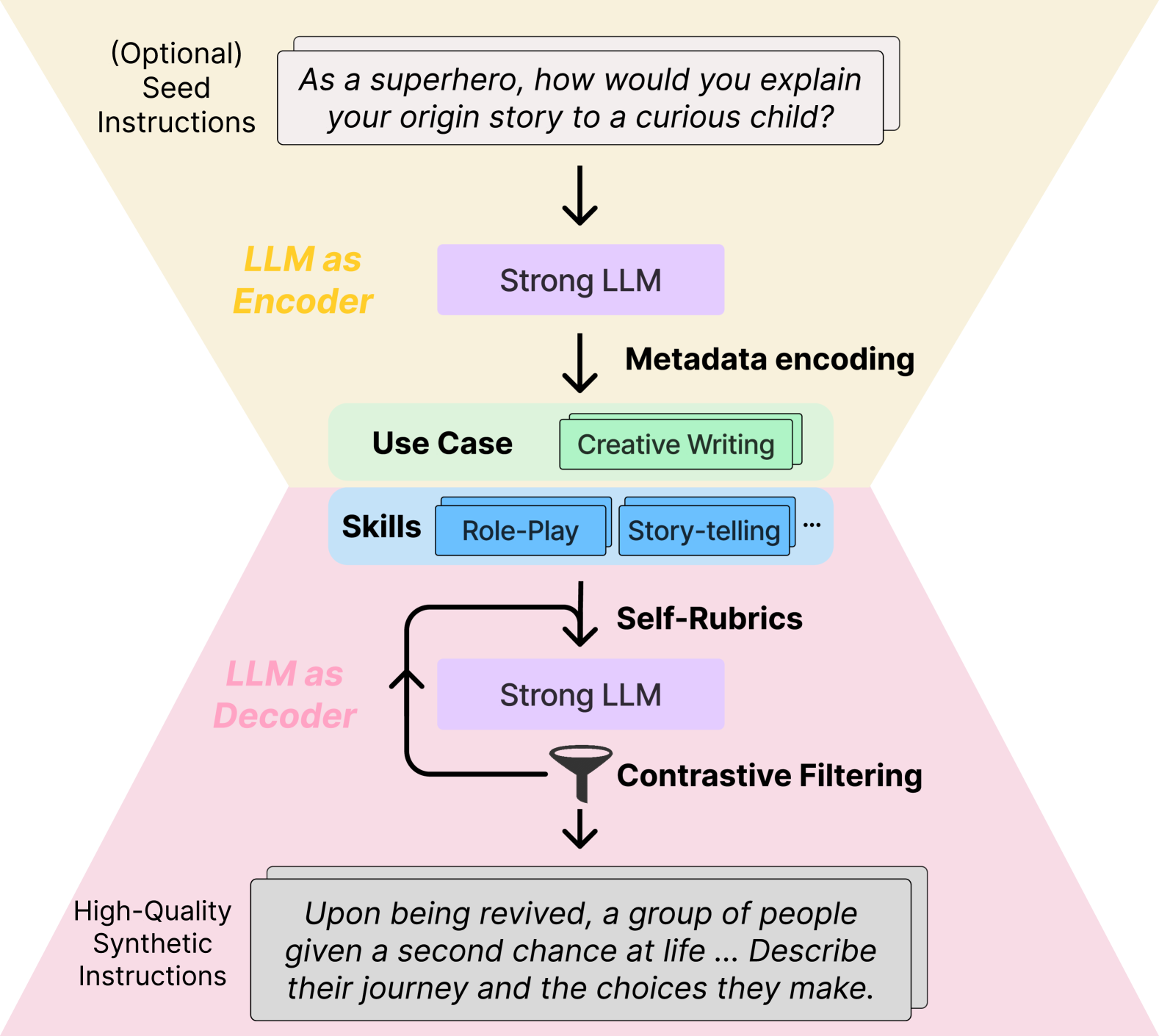
Instruction tuning has emerged as the key in aligning large language models (LLMs) with specific task instructions, thereby mitigating the discrepancy between the next-token prediction objective and users' actual goals. To reduce the labor and time cost to collect or annotate data by humans, researchers start to explore the use of LLMs to generate instruction-aligned synthetic data. Recent works focus on generating diverse instructions and applying LLM to increase instruction complexity, often neglecting downstream use cases. It remains unclear how to tailor high-quality data to elicit better instruction-following abilities in different target instruction distributions and LLMs. To this end, we introduce CodecLM, a general framework for adaptively generating high-quality synthetic data for LLM alignment with different downstream instruction distributions and LLMs. Drawing on the Encode-Decode principles, we use LLMs as codecs to guide the data generation process. We first encode seed instructions into metadata, which are concise keywords generated on-the-fly to capture the target instruction distribution, and then decode metadata to create tailored instructions. We also introduce Self-Rubrics and Contrastive Filtering during decoding to tailor data-efficient samples. Extensive experiments on four open-domain instruction following benchmarks validate the effectiveness of CodecLM over the current state-of-the-arts.
Read more4/10/2024